- The paper empirically demonstrates that next token prediction (NTP) training provides superior reasoning and generalization compared to critical token prediction (CTP) on diverse benchmarks.
- It details experiments showing that NTP achieves near-perfect accuracy on arithmetic and multi-hop tasks, while CTP tends to overfit and is more sensitive to noise.
- The study highlights a trade-off where NTP’s robust pretraining leads to catastrophic forgetting during fine-tuning, suggesting a need for hybrid optimization strategies.
Reasoning Bias of Next Token Prediction Training
Introduction
The paper "Reasoning Bias of Next Token Prediction Training" presents a systematic examination of Next Token Prediction (NTP) compared to Critical Token Prediction (CTP) within transformer-based LLMs, specifically for reasoning tasks. This research examines the counterintuitive superior reasoning capabilities of NTP, despite its inherent exposure to noise. The primary contribution is the empirical demonstration of NTP's enhanced generalization and robustness, challenging the traditional emphasis on reduced noise within tasks typically handled by CTP.
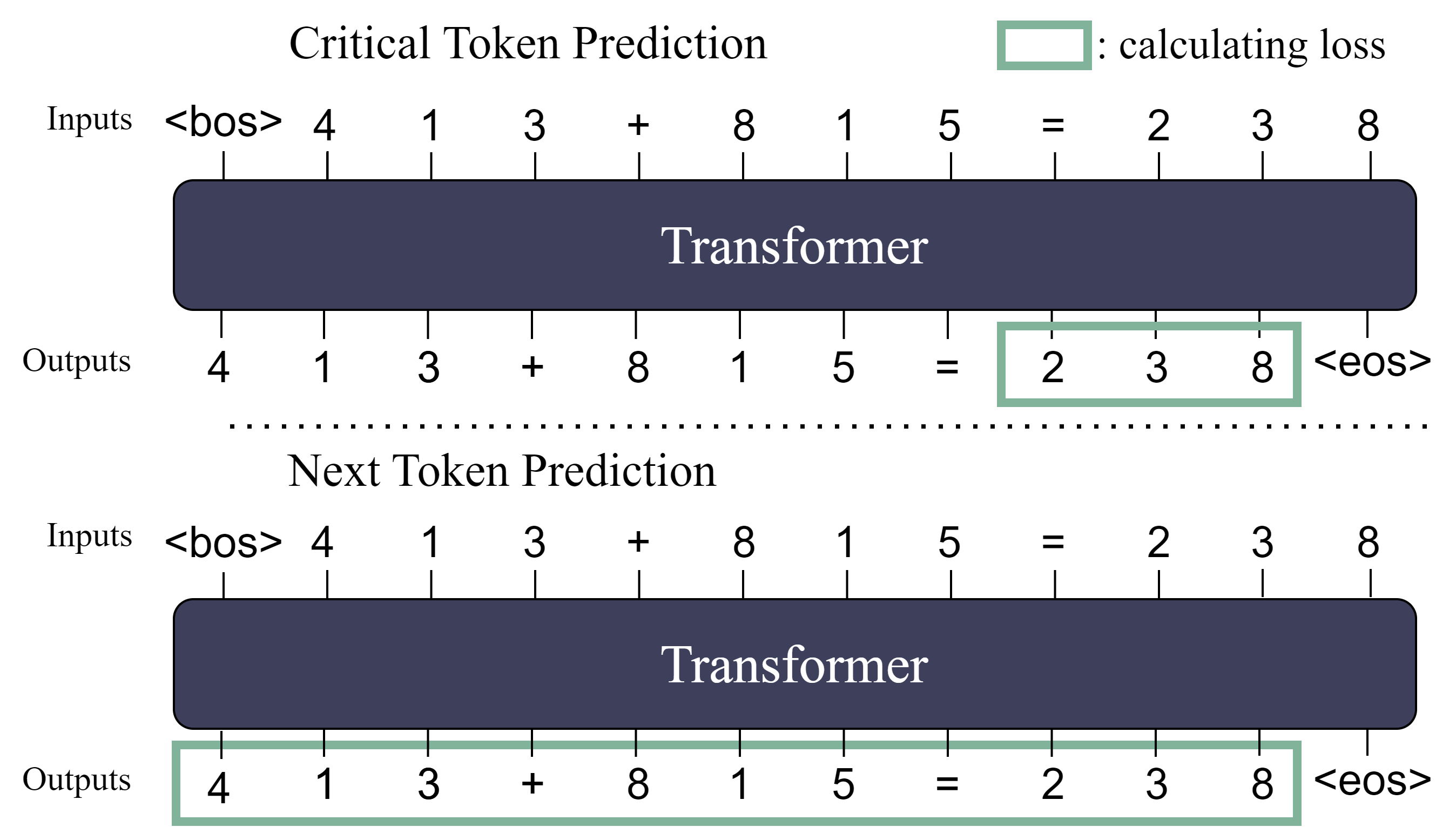
Figure 1: The schematic illustration comparing NTP and CTP. In the context of arithmetic addition tasks, CTP's loss function exclusively focuses on the answer, whereas NTP's loss encompasses the entire sequence, consequently introducing a certain degree of noise during the optimization process.
Experimental Framework
The experiments contrast NTP and CTP using a comprehensive set of reasoning benchmarks, including PrOntoQA and various other natural language reasoning tasks. The key differences between these methods lie in their loss functions: NTP computes loss over the entire sequence, introducing noise, while CTP focuses solely on the critical token, usually the answer, reducing noise but potentially overfitting to surface patterns.
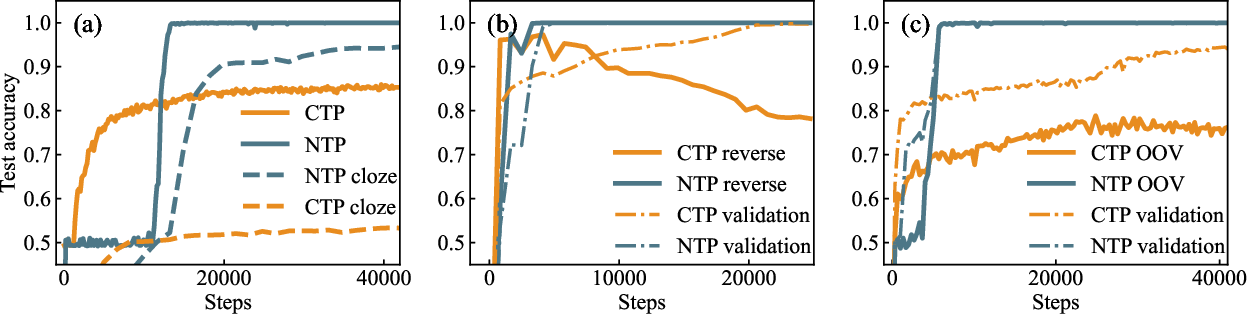
Figure 2: (a) Accuracy of NTP and CTP on the original/cloze PrOntoQA task over training epochs. In the original task, NTP eventually achieves perfect accuracy, while CTP plateaus around 80\%. In the cloze task, the performance difference between NTP and CTP is enlarged. (b) 2-hop specific PrOntoQA: Performance of NTP and CTP on the specified key-answer PrOntoQA task. NTP maintains high accuracy without overfitting, whereas CTP overfits to the training data, leading to decreased accuracy on the reverse test set. (c) 1-hop specific PrOntoQA on OOV data: Accuracy of NTP and CTP on the 1-hop PrOntoQA task with OOV data. NTP achieves nearly 100\% accuracy, while CTP stabilizes around 70\%.
Findings on PrOntoQA and Other Reasoning Tasks
PrOntoQA, a synthetic dataset designed for multi-hop inference, served as a critical benchmark. In various tasks, including cloze and reverse setups, NTP demonstrated superior generalization, ultimately achieving near-perfect accuracy in scenarios where CTP struggled or overfit the training data.

Figure 3: Performance comparison of NTP and CTP across various reasoning tasks. NTP consistently outperforms CTP in reasoning tasks, while performance on text classification tasks is more mixed. All tasks are trained on the GPT-2 model (125M) from scratch to dismiss the effect of NTP in the pretraining stage.
Evaluation of Robustness
The study extended to evaluating robustness through embedding noise and training with misleading labels. NTP showed greater stability and slower memorization of erroneous data compared to CTP, suggesting a deeper capture of reasoning structures beyond overt noise.

Figure 4: Effect of embedding noise on model performance in different reasoning tasks. The x-axis represents the perturbation strength α in Eq.~\eqref{eq:robustness}. NTP-trained models maintain higher accuracy under varying levels of input noise compared to CTP-trained models.
Finetuning and Transfer Learning
Investigations into transfer learning highlighted NTP's superior performance during early stages of finetuning. However, it also displayed a higher propensity for catastrophic forgetting, a trade-off for its initial advantage in model flexibility and generalization.
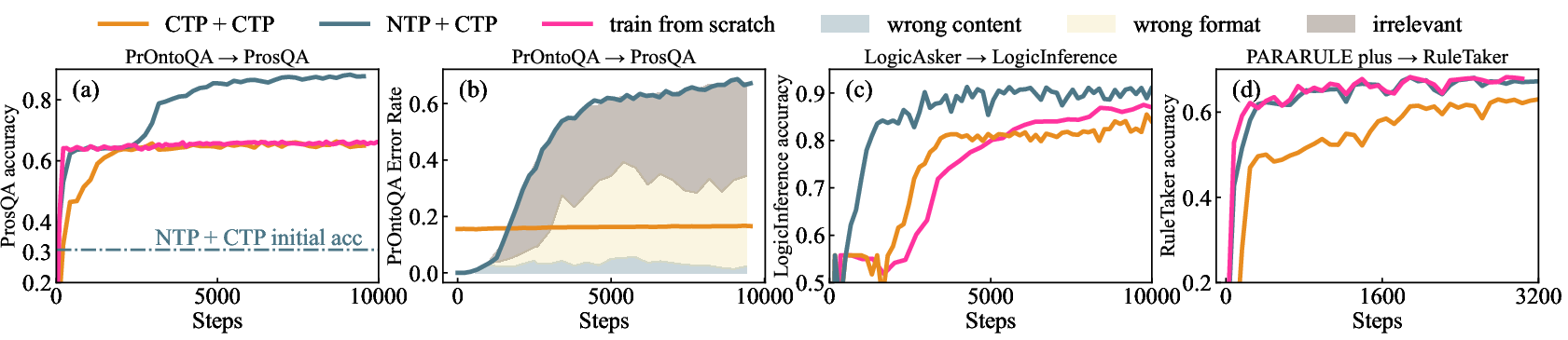
Figure 5: Finetuning results with multiple tasks. NTP+CTP means the model is NTP-trained on previous task and CTP-finetuned on post task; train from scratch means the model is trained from scratch with the same configuration of CTP-funtuning.
Conclusion
The study concludes that NTP, despite noise exposure, inherently fosters reasoning capabilities during pretraining, proving more effective in capturing generalization capabilities compared to CTP. The findings advocate a hybrid approach: adopting NTP during pretraining for enhanced reasoning and deploying CTP for finetuning to achieve focused, task-specific optimization. Future work should explore mechanistic analyses of NTP and broader training paradigms, particularly considering the implications of noise and generalization in LLMs.