- The paper demonstrates that TOP improves language modeling by ranking upcoming tokens based on their proximity, outperforming traditional next-token and multi-token predictions.
- The authors modify the architecture minimally with a single unembedding layer and a custom Triton kernel, ensuring efficient training and scalability.
- Experimental results reveal higher benchmark scores and lower perplexity across datasets, indicating enhanced generalization and parameter efficiency.
Token Order Prediction (TOP): A Scalable Auxiliary Objective for Language Modeling
Introduction and Motivation
The paper introduces Token Order Prediction (TOP) as a novel auxiliary objective for LLM pretraining, addressing the limitations of Multi-Token Prediction (MTP). While MTP augments next-token prediction (NTP) with additional heads to predict future tokens, it suffers from scalability issues, inconsistent improvements on standard NLP benchmarks, and increased architectural complexity. The authors hypothesize that the difficulty of exact future token prediction in MTP impedes its effectiveness, especially for small models and large look-ahead windows. TOP is proposed as a more tractable alternative, leveraging a learning-to-rank loss to order upcoming tokens by proximity, thus relaxing the prediction task and reducing architectural overhead.
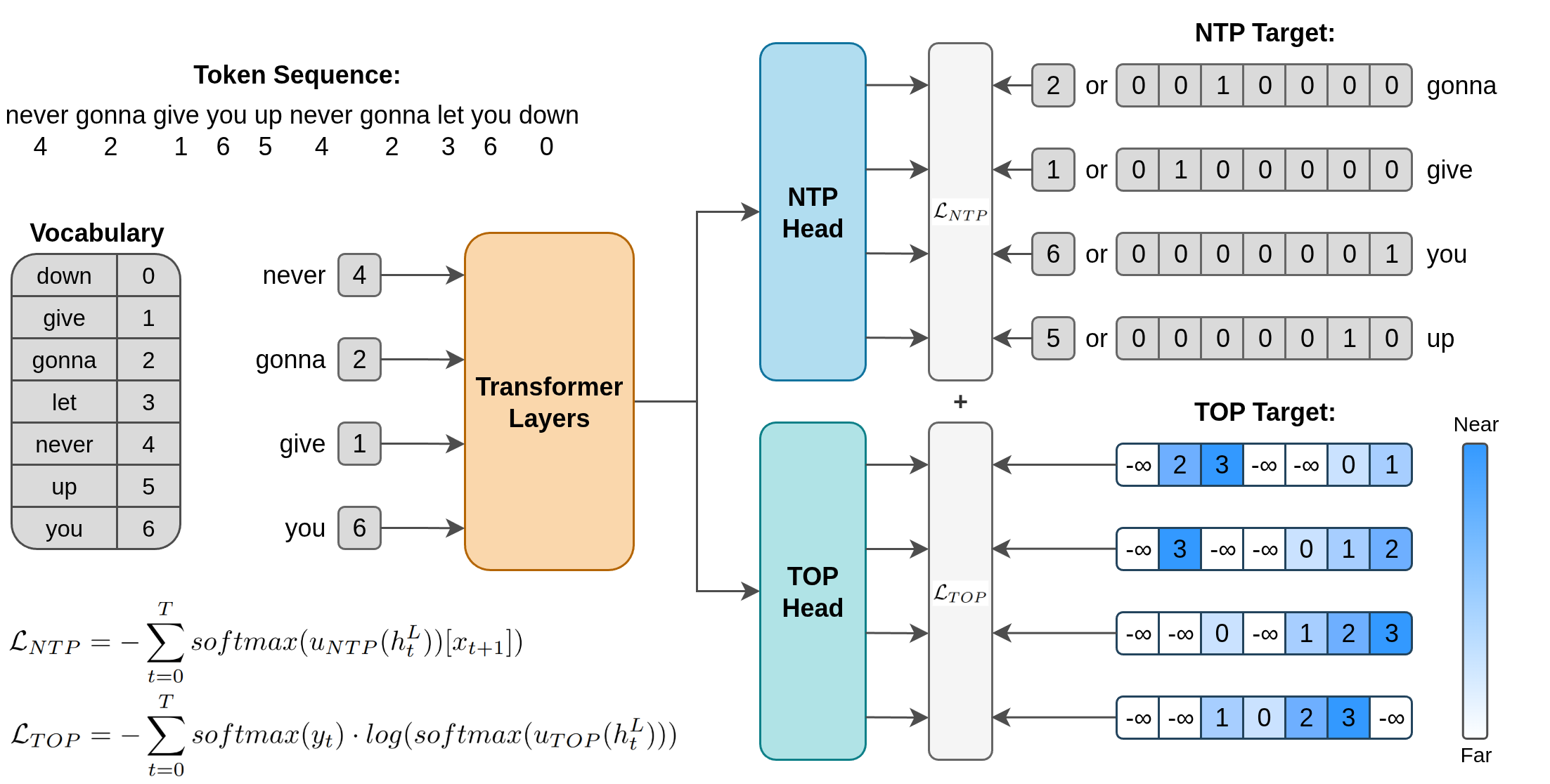
Figure 1: An overview of Token Order Prediction (TOP), illustrating the construction of the TOP target sequence and the dual unembedding heads for NTP and TOP.
Methodology
TOP constructs a target sequence for each input position, assigning a score to each vocabulary token based on its proximity of first appearance within a fixed window. The scoring function is implemented efficiently via a custom Triton kernel, enabling on-the-fly target generation with negligible overhead. The model architecture is minimally modified: a single additional linear unembedding layer (TOP head) is appended in parallel to the NTP head, both operating on the final transformer hidden state.
The TOP loss is defined using a listwise learning-to-rank objective, specifically the ListNet loss:
LTOP=−t=0∑Tsoftmax(yt)⋅log(softmax(uTOP(htL)))
where yt is the proximity score vector for position t, uTOP is the TOP unembedding layer, and htL is the final hidden state. The total training loss is the sum of the NTP and TOP losses:
L=LNTP+LTOP
This approach avoids the need for additional transformer layers per future token, as required by MTP, and scales efficiently with window size.
Comparison to Multi-Token Prediction (MTP)
MTP introduces N parallel transformer heads, each predicting a specific future token offset, with the loss:
LMTP=−t=0∑Tn=1∑Nlog(Pθ(xt+n∣x0:t))
Empirical evidence shows that MTP's loss increases and converges more slowly for tokens further in the future, indicating the increased difficulty of the task.
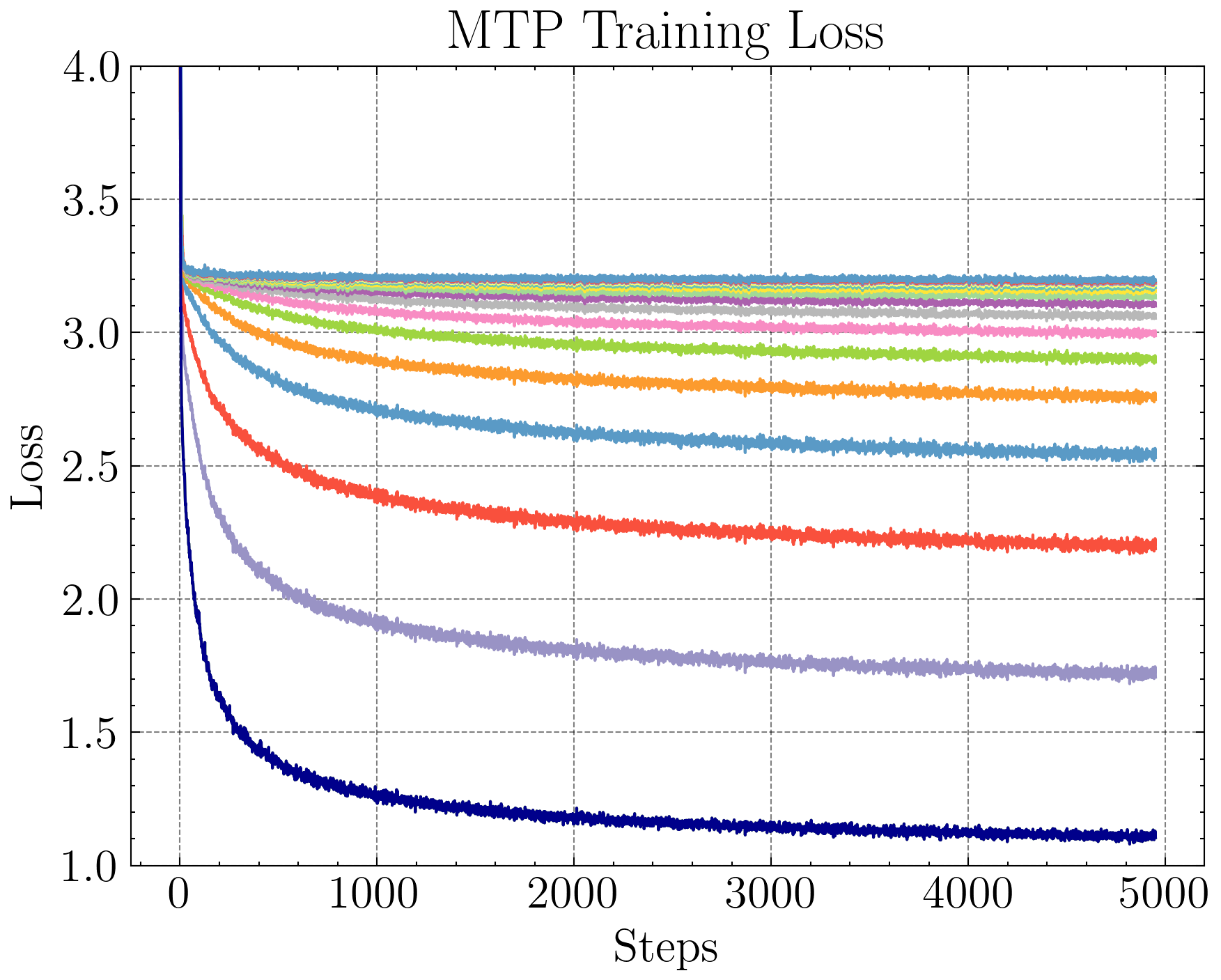
Figure 2: Training loss of a small MTP transformer model with 16 MTP heads, demonstrating the increasing difficulty of predicting tokens at larger offsets.
TOP circumvents this by focusing on relative ordering rather than exact prediction, making the auxiliary objective more learnable and less sensitive to model size and window hyperparameters.
Experimental Results
Models of sizes 340M, 1.8B, and 7B were pretrained on the FineWeb-Edu dataset using NTP, MTP, and TOP objectives. Evaluation on eight standard NLP benchmarks (ARC Challenge, Lambada, PIQA, SciQ, Social IQa, TriviaQA, NaturalQuestions Open, HellaSwag) demonstrates that TOP consistently outperforms both NTP and MTP across most tasks and scales.
Key findings include:
- TOP achieves higher benchmark scores and lower perplexity than NTP and MTP, even as model size increases.
- MTP shows competitive results for small models but underperforms at 7B parameters on non-coding tasks.
- TOP exhibits higher NTP training loss but better generalization, suggesting a regularization effect.
- TOP's architectural simplicity (single unembedding layer) enables efficient scaling and minimal compute overhead.
These results indicate that TOP is a more effective and scalable auxiliary objective for general language modeling compared to MTP.
Practical and Theoretical Implications
The introduction of TOP has several practical advantages:
- Parameter Efficiency: Only one additional unembedding layer is required, regardless of window size, in contrast to MTP's multiple transformer layers.
- Scalability: TOP scales well with model size and window hyperparameters, making it suitable for large-scale LLM pretraining.
- Generalization: The regularization effect observed with TOP suggests improved generalization and reduced overfitting, particularly on limited datasets.
- Inference Compatibility: The TOP head is removed at inference, preserving the standard transformer architecture and generation capabilities.
Theoretically, TOP reframes auxiliary objectives in language modeling from exact prediction to ranking, aligning with advances in learning-to-rank literature. This relaxation of the prediction task may facilitate the learning of richer internal representations, potentially benefiting downstream tasks that require contextual reasoning and look-ahead capabilities.
Future Directions
The paper outlines several avenues for further research:
- Comparative analysis with DeepSeek V3's sequential MTP variant.
- Evaluation of TOP on generative tasks (summarization, coding) and synthetic reasoning benchmarks (star graph problem).
- Investigation of self-speculative decoding using TOP.
- Analysis of the regularization effect and its impact on generalization.
These directions will clarify the scope and limitations of TOP and its applicability to broader LLM training regimes.
Conclusion
Token Order Prediction (TOP) is presented as a scalable, parameter-efficient auxiliary objective for LLM pretraining. By shifting from exact future token prediction to ranking upcoming tokens by proximity, TOP overcomes the limitations of MTP and demonstrates superior performance on standard NLP benchmarks across multiple model sizes. The method's architectural simplicity and empirical effectiveness suggest its potential for widespread adoption in LLM training pipelines. Future work will further elucidate its benefits and extend its evaluation to generative and synthetic reasoning tasks.

