- The paper proposes Future Summary Prediction (FSP) to replace multi-token objectives, reducing exposure bias and shortcut learning in LLMs.
- It introduces both hand-crafted and learned summary approaches, with FSP-RevLM adaptively focusing on the most informative future tokens.
- Empirical results show FSP-RevLM improves reasoning and coding tasks by up to 5% on 3B and 8B models, underscoring its scalability.
Future Summary Prediction: Advancing LLM Pretraining Beyond Multi-Token Prediction
Introduction and Motivation
The paper "Beyond Multi-Token Prediction: Pretraining LLMs with Future Summaries" (2510.14751) addresses fundamental limitations in standard next-token prediction (NTP) and multi-token prediction (MTP) objectives for LLM pretraining. NTP, which relies on teacher forcing, suffers from exposure bias and shortcut learning, impeding long-horizon reasoning, planning, and creative generation. MTP partially mitigates these issues by predicting several future tokens, but its improvements are constrained by short-range dependencies and scalability bottlenecks. The authors propose Future Summary Prediction (FSP), a framework that trains an auxiliary head to predict a compact representation of the long-term future, either via hand-crafted or learned summaries, thereby providing richer supervision and reducing teacher forcing.
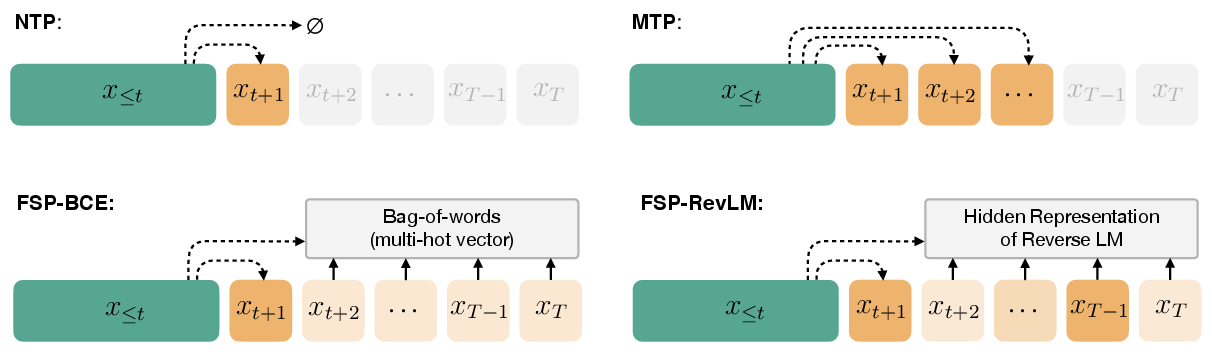
Figure 1: A comparison of future-aware pretraining objectives. All methods take a prefix x≤t as input; FSP methods predict a summary of the future rather than individual tokens.
Pretraining Objectives: NTP, MTP, and FSP
Next-Token and Multi-Token Prediction
NTP optimizes the likelihood of the next token given the prefix, but its reliance on ground-truth histories during training leads to a train-inference mismatch. MTP extends this by predicting multiple future tokens using auxiliary heads, but typically assumes independence among future tokens and is limited by the number of auxiliary heads that can be practically deployed.
Future Summary Prediction (FSP)
FSP introduces a single auxiliary head that predicts a summary vector a(t,τ) of the future sequence (xt+2,…,xt+τ). Two instantiations are explored:
- Hand-crafted summaries (FSP-BCE): A multi-hot vector over the vocabulary indicating the presence of future tokens, trained with a binary cross-entropy loss.
- Learned summaries (FSP-RevLM): A compact embedding produced by a reverse LLM (RevLM) trained on right-to-left sequences, with the forward model's auxiliary head trained to match this representation via ℓ2 loss.
This approach is more scalable than MTP, as it requires only a single auxiliary head and can capture long-range dependencies.
Synthetic Task Analysis: Long-Horizon and Adaptive Summaries
Path-Star Graph: Long-Horizon Planning
The path-star graph task demonstrates that NTP and MTP fail to generalize for long paths due to shortcut learning and gradient starvation. FSP-BCE, by summarizing the entire future trajectory, achieves perfect accuracy even as path length increases, indicating its superiority in long-horizon planning.
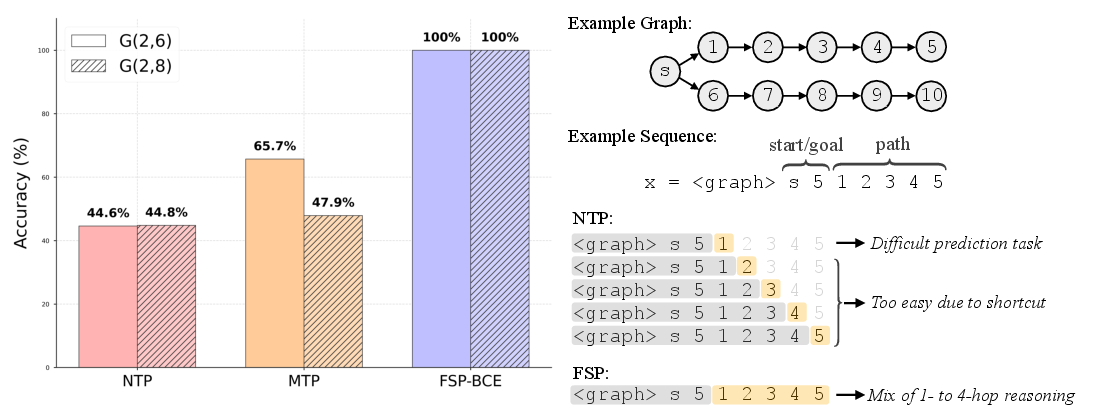
Figure 2: FSP-BCE achieves perfect accuracy on long path-star graphs, while NTP and MTP degrade as path length increases.
Sibling Discovery: Need for Adaptive Summaries
In the modified sibling discovery task, only a subset of future tokens is informative. FSP-BCE, which summarizes all future tokens, suffers from irrelevant information, whereas FSP-RevLM, which learns to focus on informative aspects, converges faster and remains robust as the number of components increases.
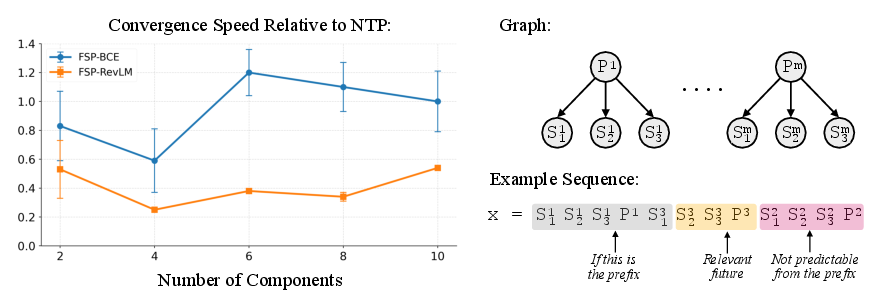
Figure 3: FSP-RevLM converges faster than NTP and FSP-BCE, especially as the number of components increases, due to its adaptive future summary.
Large-Scale Pretraining and Empirical Results
The authors pretrain 3B and 8B parameter models on up to 1T tokens, evaluating on ARC, MBPP, HumanEval+, GSM8K, and MATH. FSP-RevLM consistently outperforms NTP and MTP on reasoning and coding tasks at 8B scale, with up to 5% absolute improvement on math and coding benchmarks. At 3B scale, DeepSeek-MTP is competitive, but FSP-RevLM exhibits stronger scaling properties, overtaking DS-MTP as model size increases.
Notably, FSP-RevLM enhances output diversity on math reasoning tasks compared to vanilla MTP, as shown by increased pass@k scores and more varied generations.
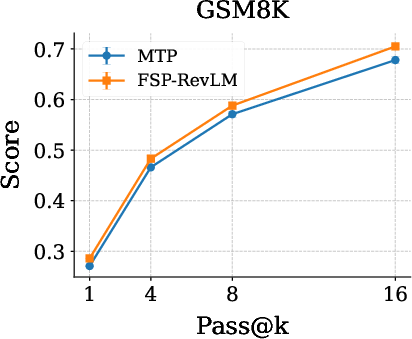
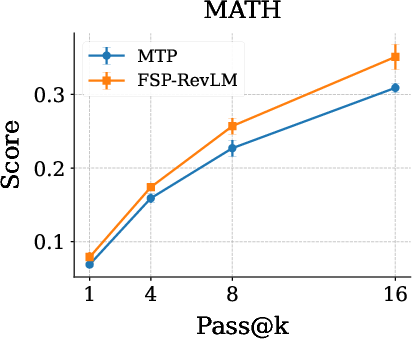
Figure 4: FSP-RevLM substantially increases output diversity compared to MTP on GSM8K and MATH benchmarks.
Architectural and Implementation Considerations
FSP is implemented by augmenting the standard transformer backbone with a single auxiliary head. For hand-crafted summaries, the auxiliary head outputs logits over the vocabulary, trained with a reweighted BCE loss. For learned summaries, a reverse LLM is trained in parallel, and its hidden states serve as targets for the auxiliary head, matched via ℓ2 loss. The computational overhead of training the reverse model is amortized and excluded from student model comparisons.
Key trade-offs include:
- Scalability: FSP requires only one auxiliary head, unlike MTP which scales linearly with the number of future tokens.
- Signal Quality: Hand-crafted summaries can be noisy if the future contains irrelevant tokens; learned summaries via RevLM are more adaptive and robust.
- Resource Requirements: Training the reverse model incurs a one-time cost, but the main model's training remains efficient and parallelizable.
Theoretical and Practical Implications
FSP provides a more robust and informative training signal, reducing teacher forcing and discouraging shortcut learning. This leads to improved generalization on tasks requiring long-horizon reasoning and planning. The approach is compatible with existing transformer architectures and can be integrated into large-scale pretraining pipelines with minimal modifications.
Theoretically, FSP shifts the focus from local token prediction to global sequence properties, aligning the training objective more closely with the demands of open-ended generation and reasoning. Practically, it enables more efficient use of training data and compute, especially as scaling laws plateau.
Future Directions
Potential avenues for future research include:
- Refinement of learned summaries: Exploring alternative architectures for the reverse model or more sophisticated summary extraction methods.
- Integration with bidirectional and diffusion-based models: Combining FSP with other paradigms that leverage global sequence information.
- Task-specific summary adaptation: Dynamically adjusting the summary window or representation based on downstream task requirements.
- Analysis of summary informativeness: Quantifying the contribution of different summary components to downstream performance.
Conclusion
Future Summary Prediction (FSP) represents a principled advancement in LLM pretraining objectives, addressing the scalability and informativeness limitations of multi-token prediction. By predicting compact, adaptive summaries of the future, FSP delivers stronger supervision, reduces teacher forcing, and improves performance on long-horizon reasoning and coding tasks. The empirical results and architectural simplicity suggest that FSP is a promising direction for next-generation LLMs, with broad applicability and potential for further refinement.