- The paper demonstrates that LLMs maintain robust reasoning performance even with up to 40% reward noise, achieving high accuracy on math benchmarks.
- It introduces a novel Reasoning Pattern Reward (RPR) method that reinforces effective reasoning phrases as an alternative to strict answer verification.
- The study confirms that calibrating noisy reward models with RPR improves performance on open-ended NLP tasks and enhances smaller model capabilities.
Reward Noise in Learning to Reason
This paper investigates the impact of reward noise on post-training LLMs for reasoning tasks. It challenges the conventional focus on tasks with easily verifiable rewards, such as math problems, and explores scenarios where rewards are noisy due to imperfect reward models or rule-based functions. The research demonstrates that LLMs exhibit a surprising robustness to substantial reward noise and introduces a method to calibrate noisy reward models using reasoning patterns.
Robustness to Reward Noise in Math Tasks
The authors begin by examining the effects of manually introduced noise in the reward signals for math tasks (Section \ref{sec:math-exp}). They train a Qwen-2.5-7B model on a dataset of 57K high-quality math problems, using vanilla PPO with GAE. Noise is introduced by randomly flipping the reward with a probability p, effectively assigning positive rewards to incorrect answers. The model's performance is evaluated on MATH-500, GPQA, and AIME 2024 datasets.

Figure 1: The prompt used in math training, where the ``question'' placeholder will be replaced with a specific question.
The results indicate that the model can tolerate a high flip rate of up to 40% without significant performance degradation, achieving a peak score of 72.02% on MATH-500 compared to 75.85% with no noise (Figure \ref{fig:noise-p}). Training collapses only when the flip rate reaches 50%, rendering the reward entirely random. This robustness suggests that even outputs with incorrect answers often contain valuable logical reasoning processes that contribute to learning. The paper posits that RL's effectiveness in enhancing LLMs stems from exploring appropriate reasoning patterns during rollouts, allowing the model to leverage its pre-trained knowledge more effectively.
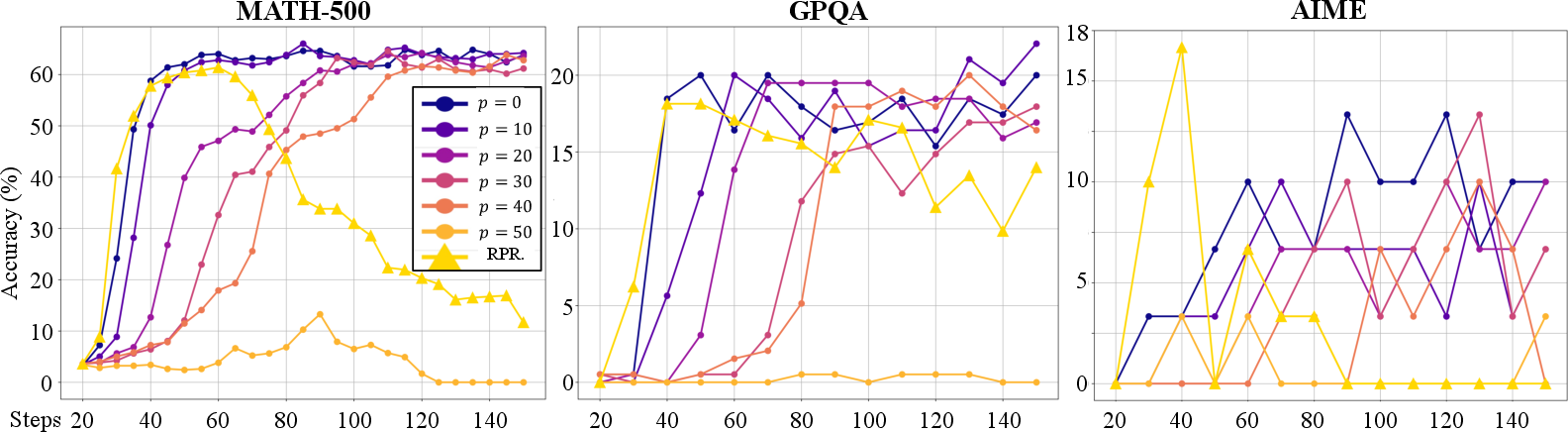
Figure 2: Accuracy on three test sets during training. Due to critic warmup, the actor model is not updated during the first 20 steps; thus, the x-axis begins at step 20.
The authors contrast the performance of Qwen-2.5-7B with that of Llama-3.1-8B, finding that Qwen significantly outperforms Llama in both downstream performance after RL and robustness to noisy rewards. This difference aligns with Llama's widely recognized weakness in reasoning.
Reasoning Pattern Reward (RPR)
To further investigate the importance of reasoning patterns, the authors introduce a novel reward strategy called Reasoning Pattern Reward (RPR) (Section \ref{sec:math-exp}). Instead of verifying the correctness of the answer, the model is rewarded for including key reasoning phrases, such as "first, I need to" or "let me first," in its outputs. Using only RPR, the model achieves peak task performance comparable to that achieved with strict correctness verification. This provides strong evidence that LLMs can reason through RL because they have already learned to reason during pre-training, with RL simply reinforcing effective reasoning patterns.
Noisy Reward Models in Open-Ended NLP Tasks
The study then shifts its focus to open-ended NLP tasks, where rewards are typically provided by neural reward models (RMs). The authors use the NVIDIA HelpSteer3 dataset, which contains 40.5K multi-domain open-ended questions requiring helpful assistance. They train RMs with varying accuracies by adjusting the training set size, simulating scenarios with different levels of reward noise. The prompt template instructs the model to summarize its reasoning and present the final response within the <answer> tag (Figure \ref{fig:nlp-prompt}). The RM only evaluates the text within the <answer> tag, ensuring consistency with the mathematical experiments.

Figure 3: The prompt used in the HelpSteer3 task, where the question'' andchat history'' placeholders are filled accordingly.
The evaluation of open-ended tasks is performed using a subset of 200 samples assessed by both GPT-4o and human evaluators. The results indicate that an LLM trained with an 85%-accurate RM performs similarly to one trained with a 75%-accurate RM but significantly better than one trained with a 65%-accurate RM (Figure \ref{fig:diff-compare}). This suggests that while robustness to reward noise persists in open-ended tasks, it is less pronounced than in mathematical tasks.
Calibrating Noisy RMs with RPR
Recognizing the limitations of relying solely on noisy RMs, the authors propose a method for calibrating RMs using RPR (Section \ref{sec:nlp-exp}). They focus on compensating for potential false negative signals by assigning a compensatory reward based on the RPR score calculated only for the thought text. This calibration boosts downstream LLM performance, outperforming LLMs trained with original RMs.
Conclusion
This paper demonstrates that LLMs exhibit a surprising robustness to reward noise, particularly when they possess strong inherent reasoning abilities. The study also provides evidence that RL enhances LLM performance primarily by reinforcing effective reasoning patterns rather than imparting substantial new knowledge. Finally, the authors propose a method to calibrate noisy reward models using RPR, leading to improved LLM performance on open-ended NLP tasks and unlocking smaller models' reasoning capabilities. The findings underscore the importance of enhancing foundational abilities during pre-training while providing insights for improving post-training techniques.

