- The paper introduces OpenScholar, a novel retrieval-augmented language model that integrates a datastore, retriever, and generator in an iterative self-feedback pipeline.
- It employs a bi-encoder retriever with a cross-encoder reranker to accurately identify relevant passages and ensure precise citation verification.
- Experimental evaluations on ScholarQABench demonstrate superior correctness, citation accuracy, and human preference compared to baseline systems.
OpenScholar: Synthesizing Scientific Literature with Retrieval-augmented LMs
Introduction
The paper "OpenScholar: Synthesizing Scientific Literature with Retrieval-augmented LMs" addresses the challenge of sifting through the vast and growing body of scientific literature to synthesize pertinent information for scientific queries. OpenScholar is proposed as a retrieval-augmented LLM (LM) specifically designed to meet this challenge by leveraging a vast database of scientific papers and enhancing retrieval accuracy and synthesis.
System Architecture
OpenScholar is composed of three primary components: a datastore, retrievers, and LLMs. OpenScholar integrates these components through a novel pipeline that incorporates self-feedback mechanisms to iteratively refine responses.
- Datastore: OpenScholar utilizes the OpenScholar-DataStore (OSDS), which contains 45 million open-access scientific papers. Each paper is processed into embeddings to aid efficient retrieval.
- Retriever: A bi-encoder retriever selects candidate passages, and a cross-encoder reranker refines these candidates to identify the most relevant passages.
- LLM: The generator LLM synthesizes the retrieved passages and iteratively improves its output via self-feedback generation.
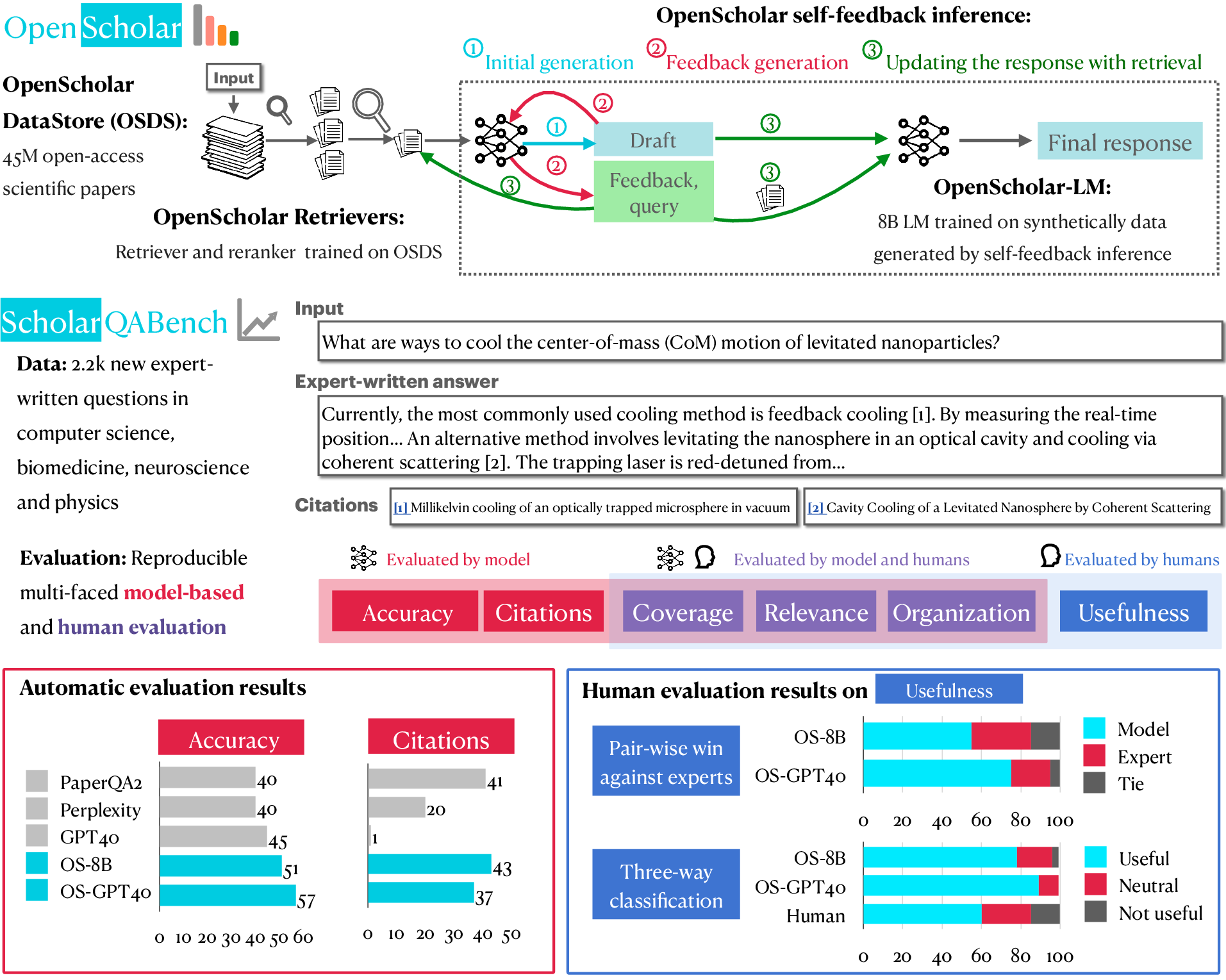
Figure 1: Overview of OpenScholar, illustrating its datastore, retrieval, and synthesis components, integrated with self-feedback mechanisms.
Inference Pipeline
The inference process in OpenScholar is marked by an iterative generation cycle that includes:
- Initial Response Generation: The LM generates a preliminary response based on retrieved context.
- Feedback Generation: The system generates feedback, which includes directives to add missing information or improve organization.
- Response Refinement: Iterative refinements to the initial response are made based on the generated feedback.
- Citation Verification: Finally, the system ensures that the generated text is adequately substantiated with correct citations.
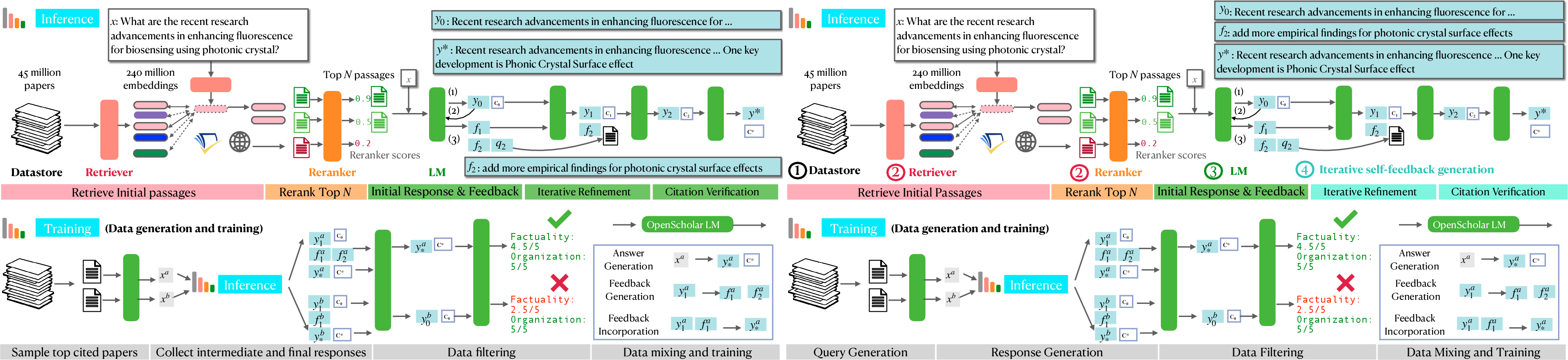
Figure 2: Detailed overview of OpenScholar inference and training mechanisms.
Training Data and Model
The training of OpenScholar-8B was augmented with synthetic data generated via the inference-time pipeline. This synthetic data simulates complex information synthesis scenarios in scientific literature, enhancing the model's capability to perform similar tasks during actual inference. The model is trained with a combination of domain-specific synthetic data, general domain instruction tuning data, and fact verification data.
Evaluation Benchmark: ScholarQABench
OpenScholar's performance is assessed using ScholarQABench, a benchmark crafted for evaluating literature synthesis across multiple disciplines. The benchmark includes:
Experimental Results
OpenScholar-8B and OpenScholar-GPT4o demonstrated superior performance on the ScholarQABench benchmark, outperforming comparable systems in areas such as correctness, citation accuracy, and human preference.
- Correctness: Achieved significant improvements over baseline models.
- Citation Accuracy: Maintained high precision and recall, matching human experts in citation verification.
- Human Preference: In human evaluations, OpenScholar-generated responses were favored over expert-written responses in various instances, notably due to their comprehensive content coverage.
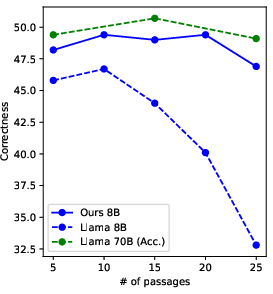
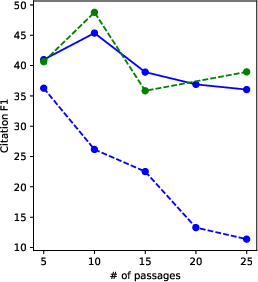
Figure 4: Fine-grained evaluation results highlight the effectiveness of OpenScholar in synthesizing scientific literature.
Conclusion
OpenScholar represents a significant step forward in automating the synthesis of scientific literature, leveraging retrieval-augmented LLMs to achieve high-quality responses backed by accurate citations. The system's iterative refinement approach, coupled with its robust retrieval mechanism, ensures it can meet the demanding requirements of scientific inquiry. OpenScholar is publicly released, along with its benchmarks and evaluation tools, to support further advancements in the field.


