- The paper presents ALCE, a benchmark that compels LLMs to generate text with verifiable citations, enhancing factual accuracy.
- It systematically evaluates diverse retrieval and synthesis strategies to balance fluency, correctness, and citation quality.
- Empirical results reveal that even top models achieve around 50% citation support, underlining the need for improved evidence integration.
Enabling LLMs to Generate Text with Citations: The ALCE Benchmark
Motivation and Problem Statement
LLMs have demonstrated impressive capabilities in natural language generation and are widely used for information retrieval tasks. However, hallucinated or unverifiable outputs remain pervasive, undermining their trustworthiness for fact-seeking applications. Addressing this, the work introduces a new paradigm: compelling LLMs to ground their generations by citing supporting passages from a fixed retrieval corpus for each factual statement, enabling both factual correctness and verifiability by design.
To systematically study this setting, the paper proposes ALCE—Automatic LLM Citation Evaluation—a reproducible benchmark for rigorous end-to-end assessment of LLMs' capabilities to generate long-form answers with precise citations. Prior works in this area largely relied on commercial search engines (hindering reproducibility), or depended on costly and subjective human evaluations, or failed to tightly couple generated statements and corresponding evidence.
The ALCE task is defined as: Given an open-domain factual question q and a large corpus D, generate an answer segmented into statements, each annotated with citations to one or more passages from D. The dataset construction and segmentation protocol ensures every factual assertion can be independently verified.
Three datasets span diverse genres and question forms:
- ASQA: Long-form ambiguous factoid QA over Wikipedia (21M passages).
- QAMPARI: Multi-answer list-style factoid QA over Wikipedia.
- ELI5: Long-form "why/how/what" questions over a Common Crawl-based corpus (Sphere, 899M passages).
This design captures challenges such as synthesizing information from multiple heterogeneous sources, grounding complex answers, and handling both extractive and abstractive reasoning requirements.

Figure 1: The ALCE task setup: for each question, the system generates text while providing citations to specific supporting passages.
Evaluation Protocol and Metrics
To enable reproducible, fine-grained, and automated evaluation, ALCE introduces metrics along three axes:
- Fluency (text naturalness): Quantified using MAUVE, which correlates with human acceptability.
- Correctness (factual accuracy and completeness): Separate proxies are defined for each dataset (e.g., EM recall for ASQA, recall-k for QAMPARI, and NLI-born claim recall for ELI5).
- Citation Quality (faithfulness and precision): Leveraging the TRUE NLI model, the system determines if each statement is entailed by its cited passages (citation recall), and if each citation is necessary (citation precision).
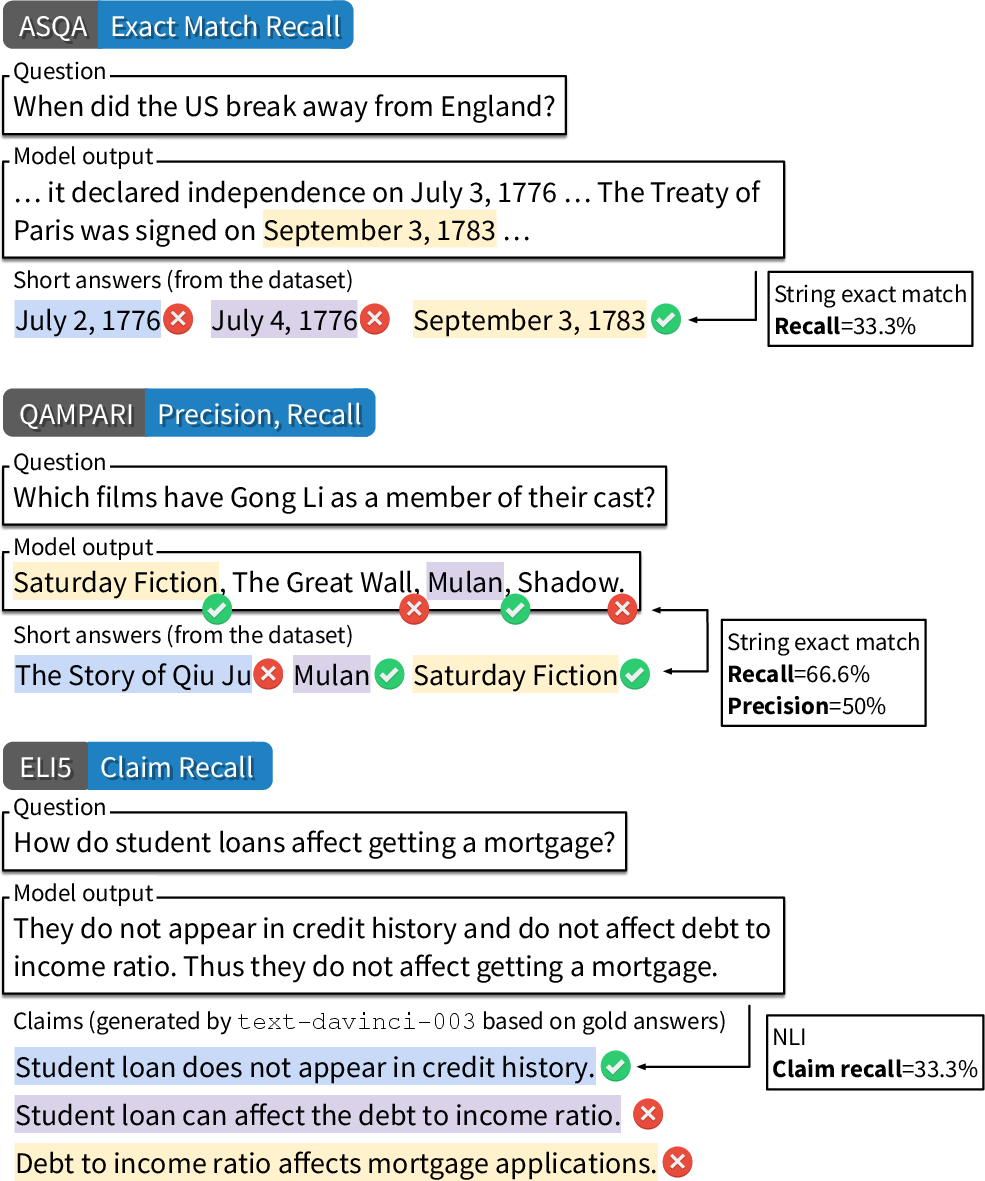
Figure 2: Illustration of correctness evaluation across QA datasets, reflecting subtasks like recall of covered answers and claim entailment.

Figure 3: The citation quality metric pipeline: an NLI model verifies if the generated statement is fully supported by the concatenation of its cited passages.
Robustness validation includes showing that shortcut strategies (e.g., copying top passages verbatim) yield poor fluency/correctness despite high citation scores, demonstrating the necessity of composite metrics.
Modeling Strategies and Experimental Analysis
The paper systematically evaluates and ablates multiple modeling strategies for retrieval, synthesis, and post-editing within the ALCE framework:
- Retrieval: Dense retrievers (GTR, DPR) for Wikipedia; BM25 for Sphere; retrieving the top-100 passages per query.
- Synthesis Approaches:
- Vanilla: Conditioning answer generation on top-k retrieved passages, instructing the LLM to cite appropriately.
- Summ/Snippet: Compressing passages via summarization or snippet extraction, allowing higher k given the context window.
- Interact/InlineSearch: Interactive prompting schemes enabling on-the-fly passage inspection or search during generation.
- ClosedBook: Generation only from model’s parametric memory, with post-hoc matching of citations.
Key findings:
- The Vanilla in-context strategy is a surprisingly effective baseline given well-retrieved, sufficiently diverse inputs.
- Summarization and snippet selection improve answer coverage, but often degrade citation fidelity due to information loss.
- Interactive and search-on-the-fly paradigms, although intuitively promising for selective synthesis, currently fall short in these open-ended QA settings, possibly due to insufficient prompt context or brittle model reasoning.
- Closed-book generation, with post-hoc citation, achieves competitive correctness but much weaker citation recall and precision, as it fails to tightly couple statements to in-context evidence.
Empirical Results and Insights
On all datasets, systems based on state-of-the-art models (ChatGPT, GPT-4, instruction-tuned LLaMA-2-Chat-70B) exhibit fluent text but systematically underperform on correctness and citation metrics compared to the estimated retrieval upper bounds.
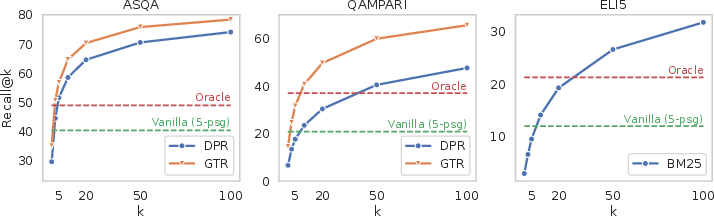
Figure 4: Retrieval recall@k for all datasets, alongside correctness scores of top-performing systems and oracle systems with gold passages.
Notable empirical observations:
- On ELI5, even best models achieved citation support on only ~50% of generations, evidencing substantial room for improvement.
- Increasing the number of retrieved passages (enabled by longer context windows, e.g., GPT-4’s 8K) yields moderate improvements for GPT-4 but little utility for ChatGPT-16K, underscoring architecture-dependent source aggregation capacity.
- Instruction-tuned open-source models (LLaMA-2-Chat-70B) narrow the performance gap with commercial APIs on correctness, but citation quality consistently lags, reflecting limitations in both retrieval integration and evidence tracking capabilities.
A detailed retrieval analysis confirms that correctness/citation scores are sharply upper-bounded by the quality of retrieval, but that LLMs underutilize available evidence even when information is directly present in context.
Human Evaluation and Metric Validation
A structured human evaluation compares the utility, citation recall, and citation precision between model generations and ALCE's automatic metrics. Human and automatic judgments are strongly correlated, with Cohen's kappa values of 0.698 for citation recall and 0.525 for citation precision, validating the reliability of automated assessment for reproducible benchmarking.
Implications and Directions for Future Research
Theoretical implications:
The ALCE benchmark concretely demonstrates the performance limitations of current LLMs in multi-document evidence synthesis, contextual grounding, and fine-grained attribution. This highlights open challenges in model architecture (context scaling, source tracking), retriever-generation integration (end-to-end training, joint optimization), and automated, fact-level evaluation.
Practical implications:
ALCE provides a modular and extensible platform for both academic and industrial practitioners to test progress in LLM-based fact-seeking and citation-rich applications, with metrics robust against shortcutting and applicable to new document domains.
Future AI development:
The paper suggests promising directions:
- Advancing retriever architectures with higher recall and diversity.
- Developing LLMs explicitly designed for extended context processing and reliable evidence attribution.
- Seamlessly integrating retrieval, generation, and citation in a differentiable, trainable pipeline with supervision on both correctness and attribution.
- Extension of benchmarks to cover complex reasoning (multi-hop, mathematical, code) and more granular citation scenarios (statement-level, claim-level, partial support).
Conclusion
The paper presents a comprehensive, automated, and reproducible benchmark—ALCE—establishing a new methodology for measuring and advancing the ability of LLMs to generate verifiable, citation-grounded text (2305.14627). The benchmark highlights the substantial gap between fluent generation and reliable citation-grounded correctness, indicating that future progress in retrieval-augmented LLMs will require principled advances in both modeling and evaluation.