- The paper introduces pFedFDA, which personalizes federated learning by adapting a global feature distribution to match client-specific data using a generative modeling framework.
- The methodology employs random Gaussian initialization and a local-global interpolation technique to estimate client-specific feature distributions for effective adaptation.
- Experimental results demonstrate over 6% accuracy improvement on benchmarks like CIFAR10, especially under non-IID and data-scarce conditions.
Personalized Federated Learning via Feature Distribution Adaptation
Introduction
The paper "Personalized Federated Learning via Feature Distribution Adaptation" (2411.00329) addresses a critical challenge in federated learning (FL) under conditions of data heterogeneity. The authors propose a method called pFedFDA, which is designed to enhance model personalization by adapting a global feature distribution to local client feature distributions. Standard FL approaches like FedAvg often falter under non-IID client data distributions, leading to client drift and suboptimal results. This paper aims to bridge this gap by employing a generative modeling perspective for representation learning, thereby improving the adaptability of personalized federated learning (PFL) models in complex scenarios such as covariate shifts or data scarcity.
Methodology
The methodology of pFedFDA involves training a global shared representation via a generative classifier derived from the global feature distribution. The algorithm begins with random Gaussian initialization of feature extraction parameters and global feature distribution estimates. During each FL round, active clients receive these parameters and train the shared feature extractor to minimize classification loss, guided by the global distribution. Local adaptation is achieved by estimating client-specific feature distributions through low-sample Gaussian techniques and a local-global interpolation method. The aggregation of local estimates to update global parameters ensures efficient personalization for clients.
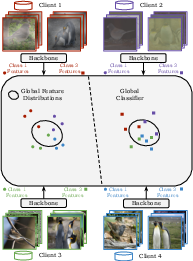
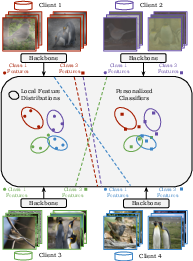
Figure 1: Global Representation Learning.
Generative Modeling Perspective
The generative model, fundamental to pFedFDA, posits that client data heterogeneity can be tackled through representation learning with generative classifiers. By choosing a class-conditional Gaussian model for feature distributions, clients can efficiently compute Bayesian classifiers, aligning local learning objectives with global representation. This model inherently handles the bias-variance trade-off critical in PFL, enabling effective client collaboration and mitigating the disparity introduced by global knowledge.
Experimental Setup
Extensive experiments demonstrate the efficacy of pFedFDA across several image classification datasets, including CIFAR variants and EMNIST, under various data partition settings. In particularly challenging conditions—characterized by data scarcity and covariate shifts—the method exhibited substantial improvements over state-of-the-art benchmarks, consistently achieving higher accuracy rates. Notably, pFedFDA yielded a >6% accuracy improvement in data-scarce settings and competitive performance in traditional scenarios with moderate heterogeneity.
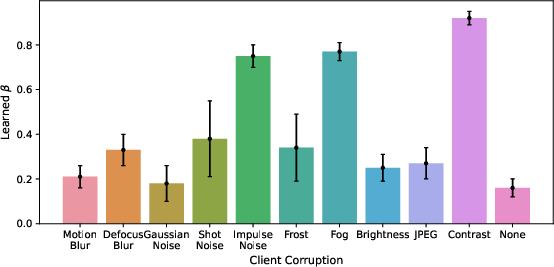
Figure 2: Comparison of client beta and local dataset corruption on CIFAR10-S.
Numerical Results
The experimental outcomes reveal that under severe heterogeneity and low-data configurations, pFedFDA provides superior model adaptability and precision, achieving remarkable accuracy gains—up to 6.9% improvement on CIFAR10 compared to the next-best method. The method also showed enhanced generalization capabilities to new clients, performing well even with covariate shifts not observed during training, highlighting its robustness and practical viability.
Ablation Studies
A series of ablation studies confirmed the advantage of the local-global interpolation method for feature distribution estimation. The choice of a single interpolation coefficient was demonstrated to be cost-effective and efficient, while adapting coefficients for features' means and covariances provided additional advantages in settings with high distribution shifts.
Conclusion
The pFedFDA method represents a significant advancement in personalized federated learning by effectively addressing the bias-variance trade-off through generative modeling, thereby ensuring scalable and adaptable client personalization. Future research may explore the integration of more complex generative models or clustering strategies to enhance its applicability in broader domains. With its robust handling of data heterogeneity and efficient execution, pFedFDA holds promise for widespread FL applications, including those necessitating enhanced privacy-preserving measures and greater client generalization capabilities.
