- The paper introduces FedCKD, which employs dual-teacher distillation from global and historical models to balance personalization and generalization.
- It achieves superior accuracy, outperforming benchmarks by up to 1.98% on CIFAR100, effectively addressing catastrophic forgetting.
- The method phases training into local distillation and global aggregation, ensuring robust performance in heterogeneous data environments.
Towards Personalized Federated Learning via Comprehensive Knowledge Distillation
Introduction
Federated Learning (FL) is a decentralized machine learning approach aimed at protecting data privacy by allowing collaborative training of machine learning models without sharing raw data. However, FL faces challenges due to data heterogeneity across clients, leading to catastrophic forgetting, where models lose previously acquired knowledge when learning new information. Personalized Federated Learning (PFL) attempts to customize models for individual clients to combat this issue. This paper proposes the FedCKD method, which leverages comprehensive knowledge distillation (KD) to balance model personalization and generalization.
Personalized Federated Learning
In FL, a server coordinates n clients, each with private data Dk={xk,yk}. The goal is to train a global model wg by minimizing the overall loss across all clients. Traditional FL methods often fail in heterogeneous data scenarios, where personalization is required. PFL aims to overcome this by optimizing individual models wk for each client, striking a balance between local adaptation and global knowledge.
Challenges and Limitations
Traditional PFL places excessive emphasis on personalization, potentially leading to overfitting and compromised generalization. Existing methods like pFedSD focus on transferring personalized knowledge from historical models but neglect generalized knowledge, compromising adaptability across diverse clients.
Comprehensive Knowledge Distillation
Knowledge Distillation (KD) enables the transfer of knowledge from a teacher model to a student model, smoothing output distributions with a temperature parameter τ. FedCKD applies multi-teacher KD, using both a global model wg and a historical model wh as teachers. This approach effectively integrates global generalization and personalized learning, mitigating catastrophic forgetting and enhancing model performance.
Figure 1
Figure 1: Data heterogeneity in FL leads to catastrophic forgetting.
Multi-Teacher Knowledge Distillation
FedCKD utilizes dual knowledge sources: the global model for generalized knowledge and the historical model for personalized knowledge. The loss function incorporates both these sources, facilitating comprehensive learning. An annealing mechanism adjusts the emphasis on soft labels over time, enhancing the transition from knowledge transfer to independent learning.
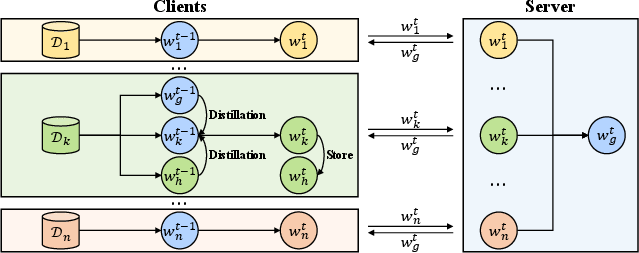
Figure 2: The framework of our method. The client update phase is divided into local distillation and local store processes.
Methodology
FedCKD divides training into multiple phases, including server broadcasting, client updating, local distillation, and global aggregation. Clients update their models with global knowledge, perform comprehensive distillation, and store updated models for future iterations. Algorithmically, this ensures a dynamic balance between personal and collective learning.
Experiments
Setup
Experiments utilized FMNIST, CIFAR10, and CIFAR100 datasets under practical and pathological settings. FedCKD is compared against benchmarks such as FedAvg, FedProx, and diverse PFL methods. Experiments varied client numbers, participation rates, and model architectures.
Figure 3
Figure 3: Data heterogeneity among 20 clients on the CIFAR100 dataset.
Results
FedCKD consistently achieved superior accuracy across datasets, notably surpassing pFedSD by 1.98\% on CIFAR100 with 20 clients. It demonstrated strong personalized performance, robustly adapting to varying client data distributions while achieving high individual fairness. Sensitivity analysis further confirmed its stability across heterogeneity levels, client participation rates, and model architectures.
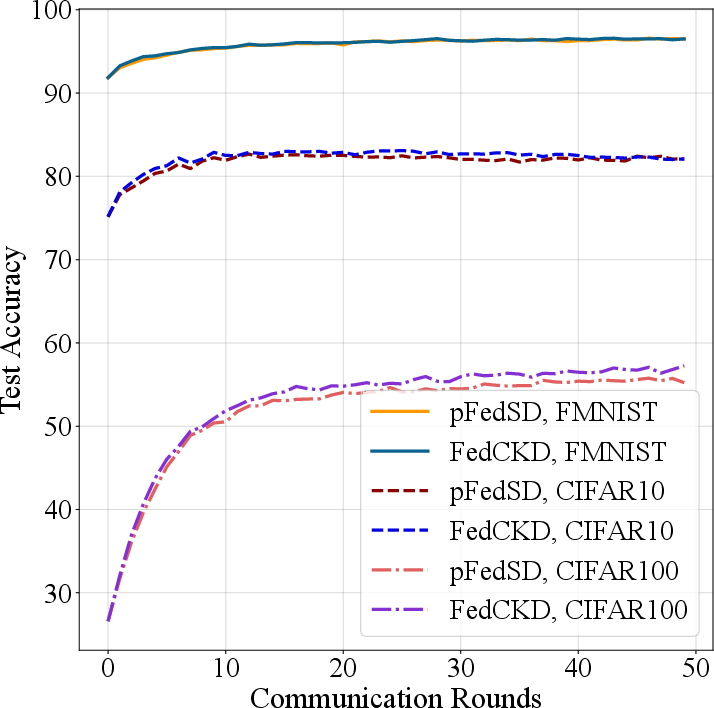
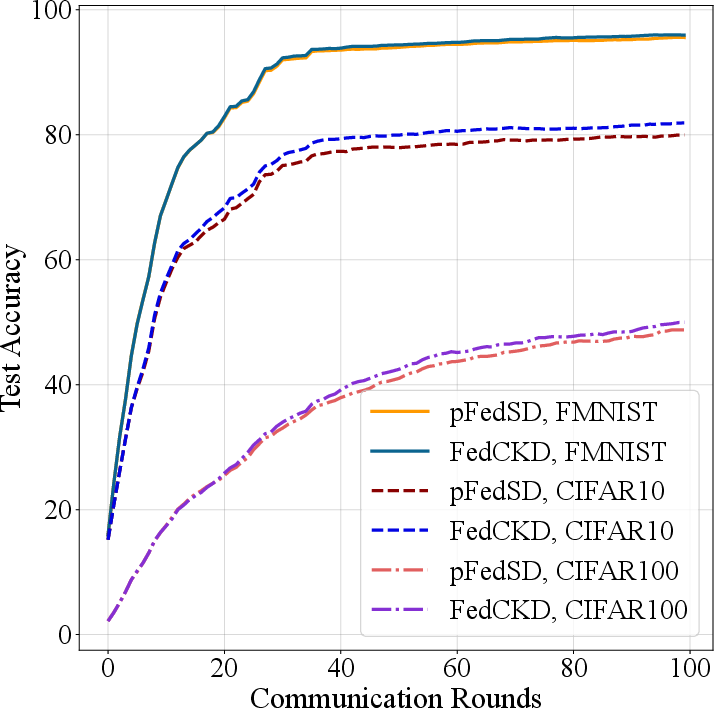
Figure 4: Learning curves under different experimental settings.
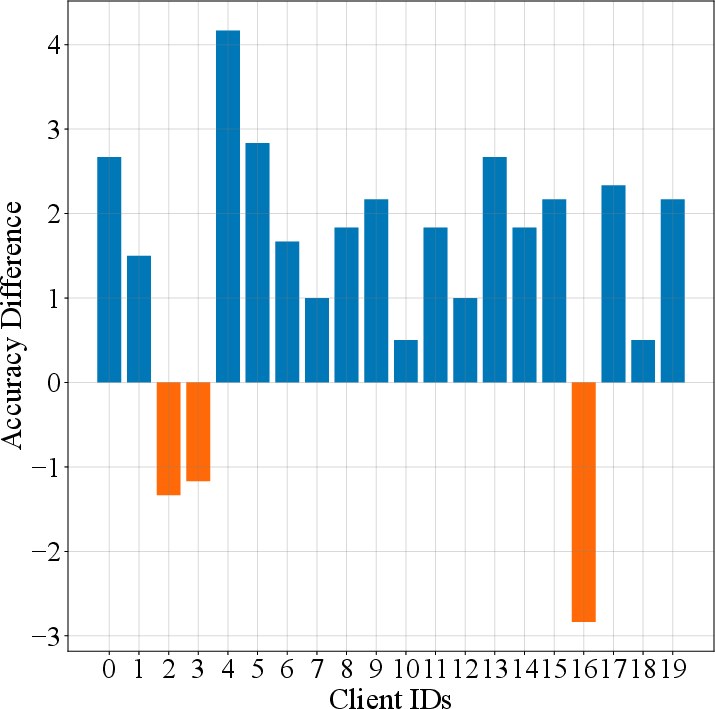
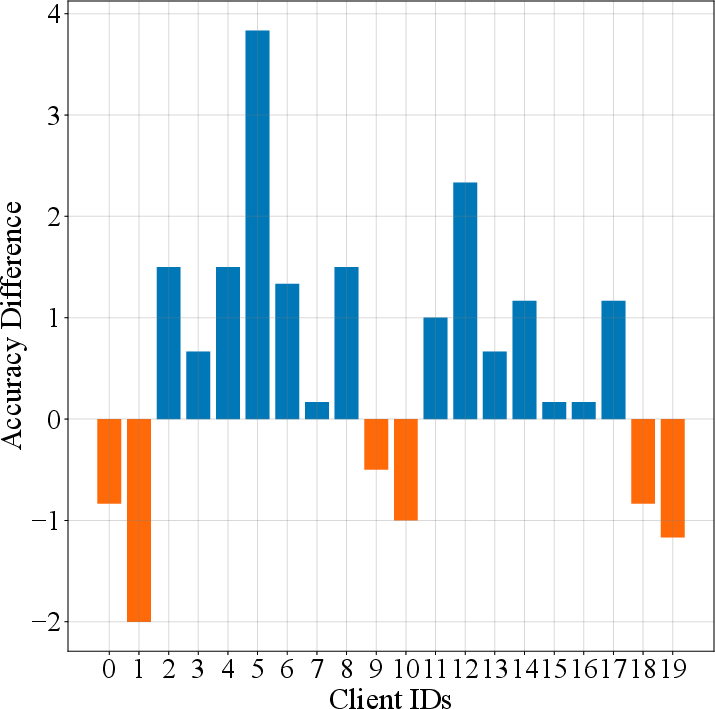
Figure 5: Accuracy difference~(\%) among 20 clients on the CIFAR100 dataset.
Conclusion
FedCKD introduces an innovative approach to PFL, achieving a harmonious integration of personalized and generalized knowledge. Through comprehensive KD and a strategic annealing mechanism, it substantially mitigates catastrophic forgetting while improving model accuracy and stability. Future research should focus on optimizing KD to reduce computational overhead in federated environments.