- The paper introduces a novel approach that uses a collaboration graph for selecting suitable client partners in decentralized federated learning.
- It leverages a bi-level optimization framework and a greedy graph construction algorithm to balance personalized model training with resource constraints.
- Experimental evaluations on CIFAR10, FEMNIST, and CINIC10 datasets show improved personalization and reduced communication overhead compared to conventional methods.
Decentralized Personalized Federated Learning
The paper "Decentralized Personalized Federated Learning" (2406.06520) addresses critical challenges associated with data heterogeneity and communication constraints in decentralized federated learning (FL) environments. The authors propose a novel approach that constructs a collaboration graph to guide clients in selecting suitable collaborators. By focusing on personalized model training leveraging local data, this method aims to enhance resource efficiency and address statistical heterogeneity in client data distributions. The paper introduces the Decentralized Personalized Federated Learning (DPFL) method, providing substantial improvements in model personalization and communication overhead reduction.
Introduction to Federated Learning
Federated learning is a distributed machine learning paradigm where client devices collaborate by sharing model parameters rather than raw data, preserving data privacy. The typical federated learning setup involves rounds of local model training followed by aggregation to produce an improved global model. However, a significant challenge in FL is data heterogeneity, particularly the non-IID nature of data and absence of prior knowledge on client data distributions, which complicates achieving a globally satisfactory model (2406.06520).
In response, personalized federated learning methods have emerged, offering tailored models for clients that better accommodate local data patterns. The focus shifts to decentralized learning where direct peer-to-peer collaboration is emphasized, reducing communication overhead and enhancing privacy.
Methodology: Optimization Framework
The proposed DPFL algorithm deals with two interconnected problems: optimizing personalized models and refining the collaboration graph. The bi-level optimization framework they introduce integrates these tasks while considering resource constraints such as network bandwidth and computational resources.
The authors reformulate the optimization problem to minimize the function F(w,C) which aggregates the individual loss functions of clients. In this scenario, Ck represents the collaboration set for client k, constrained to a maximum size Bc. The objective is to find optimal personalized models within the confines of the collaboration graph while adhering to communication and resource budgets.
Alternating Minimization
Solving this optimization problem involves two alternating steps: optimizing local model parameters using the current collaboration graph and updating the graph based on the updated models. A novel greedy graph construction algorithm (GGC) is introduced for this purpose.
Proposed Method: Greedy Graph Construction
The DPFL algorithm utilizes the GGC algorithm to identify the collaboration graph effectively. The algorithm prioritizes client cooperation that yields the best local validation loss improvements — a non-monotone submodular optimization problem with a focus on group synergy (Figure 1). This extended to graph asymmetry, where collaboration benefits are not necessarily mutual, reflecting real-world situations where data distributions vary dramatically across clients.
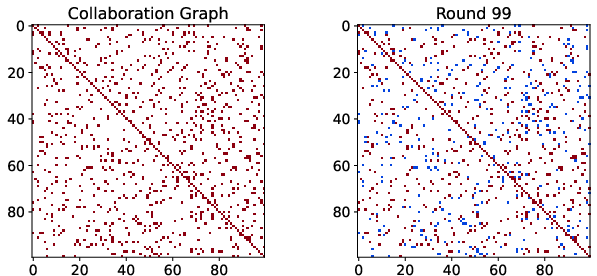
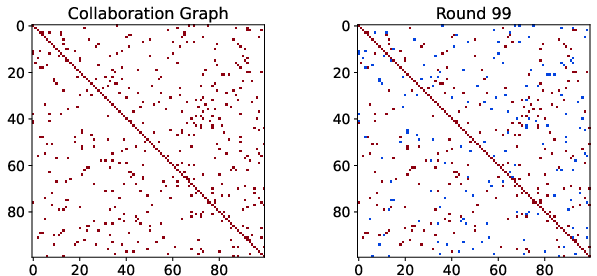
Figure 1: B_c=10
Furthermore, to ensure practicality amidst communication constraints, the authors define a Batched Greedy Graph Construction (BGGC), which efficiently manages resource usage during initial graph setup by batching model updates (Figure 2).
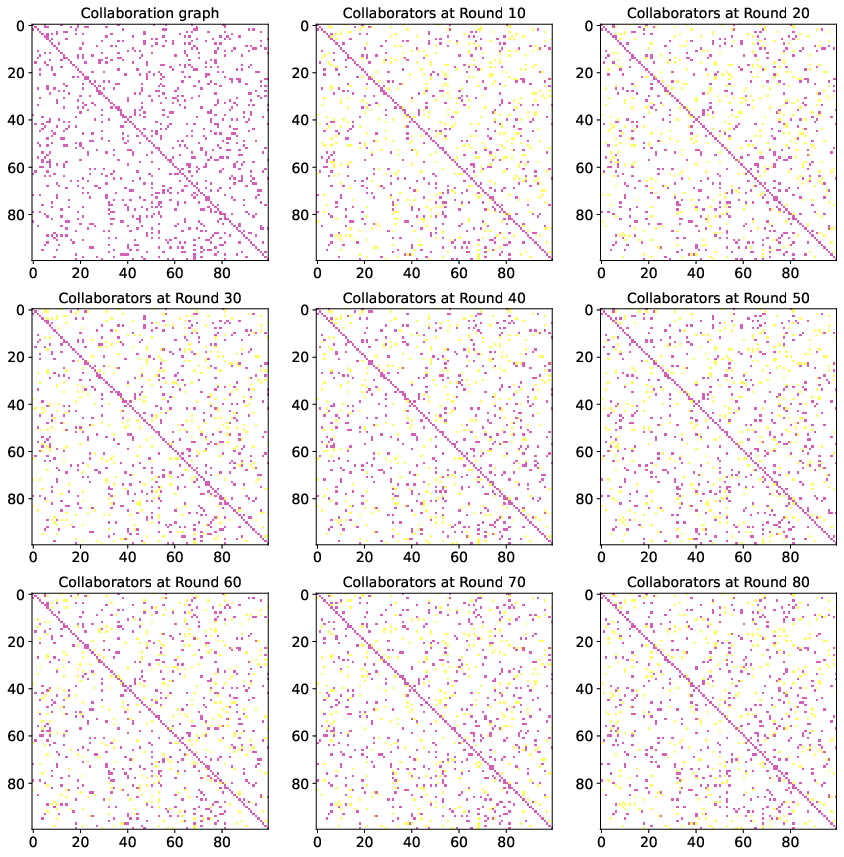
Figure 2: Our collaboration graph with constraint B_c=10 on CIFAR10 dataset with 100 clients.
Experimental Evaluation
The paper conducts extensive experiments on datasets such as CIFAR10, FEMNIST, and CINIC10, showcasing that DPFL consistently outperforms state-of-the-art personalized methods (Figure 3). DPFL achieves notable success in adapting models to client-specific data while maintaining lower variance across models, thus improving general personalization quality (Figures 5 and 6).
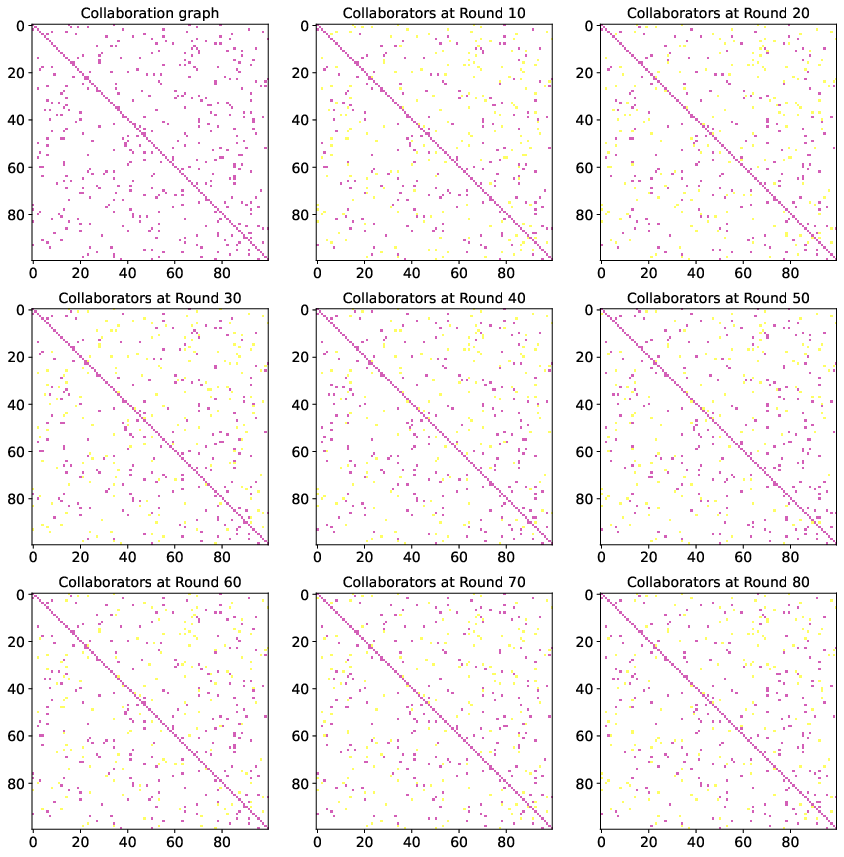
Figure 3: Our collaboration graph with constraint B_c=5 on CIFAR10 dataset with 100 clients.
Contrast with Other Methods
DPFL is contrasted against other personalized methods and baselines in terms of test accuracy and variance among local models (Figure 4 and 4). The algorithm effectively minimizes the drawbacks of conventional personalized approaches by avoiding reliance on a pre-defined global model and offering nuanced client collaboration dynamics tailored to maximize individual client gains.
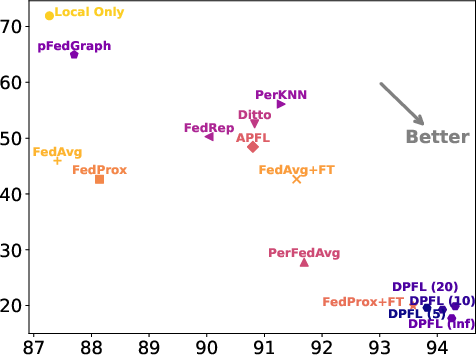
Figure 4: Comparison of our method with other personalized methods on the FEMNIST dataset in terms of variance between local models.
Implications and Future Work
This research provides insights into achieving efficient personalized learning in decentralized environments. By embracing the combinatorial selection of collaborators, DPFL minimizes global model drift and enhances personalization. Future research may explore adaptive models adjusting to varying client capabilities and investigate the implications of more dynamic and complex network topologies in federated scenarios.
Conclusion
In summary, "Decentralized Personalized Federated Learning" (2406.06520) introduces a transformative approach to addressing non-IID data challenges and communication constraints in FL. The DPFL method, leveraging greedy algorithms and collaboration graphs, significantly improves personalized model training, paving the way for more effective decentralized and privacy-preserving machine learning strategies.


