A Percolation Model of Emergence: Analyzing Transformers Trained on a Formal Language
Published 22 Aug 2024 in cs.LG and cs.AI | (2408.12578v2)
Abstract: Increase in data, size, or compute can lead to sudden learning of specific capabilities by a neural network -- a phenomenon often called "emergence''. Beyond scientific understanding, establishing the causal factors underlying such emergent capabilities is crucial to enable risk regulation frameworks for AI. In this work, we seek inspiration from study of emergent properties in other fields and propose a phenomenological definition for the concept in the context of neural networks. Our definition implicates the acquisition of general structures underlying the data-generating process as a cause of sudden performance growth for specific, narrower tasks. We empirically investigate this definition by proposing an experimental system grounded in a context-sensitive formal language and find that Transformers trained to perform tasks on top of strings from this language indeed exhibit emergent capabilities. Specifically, we show that once the language's underlying grammar and context-sensitivity inducing structures are learned by the model, performance on narrower tasks suddenly begins to improve. We then analogize our network's learning dynamics with the process of percolation on a bipartite graph, establishing a formal phase transition model that predicts the shift in the point of emergence observed in our experiments when changing the data structure. Overall, our experimental and theoretical frameworks yield a step towards better defining, characterizing, and predicting emergence in neural networks.
The paper proposes a percolation model to explain emergent capabilities in transformers, linking abrupt performance jumps to structured phase transitions.
It employs formal language experiments with bipartite graphs to simulate grammatical and type constraint acquisition, revealing task-specific scaling laws.
Empirical results confirm distinct phases in grammar, relative constraint, and descriptive generalization, offering predictive insights into neural emergence.
A Percolation Model of Emergence in Transformers Trained on Formal Languages
Introduction and Motivation
This work develops a principled framework for understanding the emergence of distinct capabilities in deep neural networks, particularly Transformers, through the lens of phase transitions and percolation theory. The authors propose a phenomenological definition of emergence in neural networks by connecting abrupt improvements in task performance to the sudden acquisition of specific, generalizable data structures. They combine rigorous formal language experiments with a predictive theory inspired by percolation on random bipartite graphs, yielding new insights into when, why, and how "emergent" behaviors arise in neural LLMs.
Formal Language Experimental System
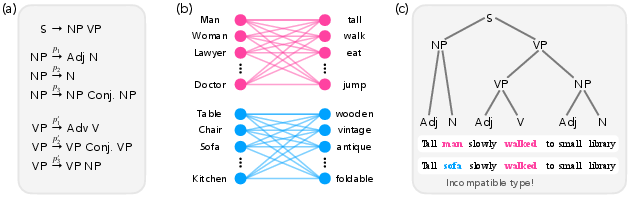
The experimental setup is based on Transformers trained on a synthetic, minimally context-sensitive formal language. The language is constructed with a probabilistic context-free grammar (PCFG) and additional "type constraints" encoded in a bipartite graph, restricting which entities (e.g., subjects, objects) may be associated with which properties (e.g., descriptors, verbs). This yields a data-generating process where only valid combinations of entities and properties are permitted, closely analogizing real-world linguistic compositionality and selectional restrictions.
Figure 1: Grammar and type constraints are instantiated by a PCFG and a type-constraint bipartite graph, jointly determining legal sentences and token co-occurrences.
The model is trained via autoregressive language modeling to perform three primary tasks:
Free Generation: Produce sentences consistent with both the grammar and type constraints.
Unscrambling: Restore shuffled sentences to grammatical and semantically valid orderings.
Conditional Generation: Compose valid sentences given specific entities or properties as constraints.
Emergence: Phenomenological Definition and Metrics
The central definition employed is that a capability C is emergent if, as data/compute/parameters scale:
There is a nonlinear improvement in performance on at least one dedicated metric for C.
There are simultaneous improvements across multiple related tasks.
These jumps coincide with the model acquiring a general data structure, such as the grammar or type-constraint graph underlying the training distribution.
"Order parameters" are operationalized as grammaticality and type check evaluations: rapid improvements in these are hypothesized to drive nonlinear changes in downstream ability.
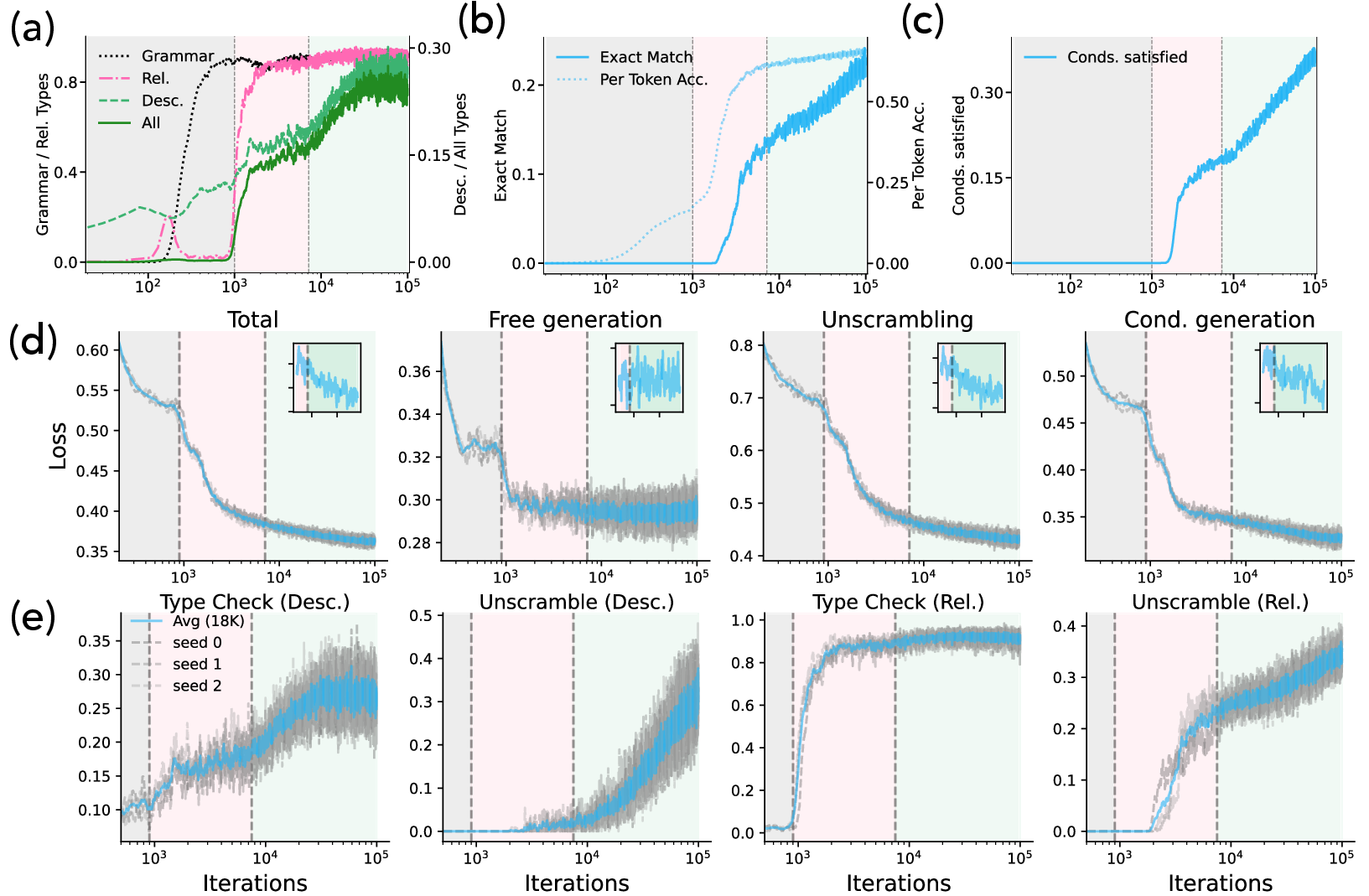
Empirical Results: Phases of Structure Acquisition and Abrupt Capability Shifts
A detailed phase analysis is conducted by monitoring model performance across tasks and structural evaluations as a function of data consumed.
Figure 2: Distinct structural acquisition phases, with nonlinear jumps in grammaticality, type check, and task performance, indicate emergence at phase boundaries.
Phase 1 (Grammar Acquisition): The model rapidly learns to generate grammatical sentences (attested by parse-based metrics and attention map sparsification) but struggles with more compositional tasks.
Phase 2 (Relative Type Constraint Acquisition): Performance on tasks demanding correct subject-object-verb relationships abruptly improves, coinciding with a loss drop and sudden mastery of relative type constraints. At this boundary, the transition is nonlinear despite approximately continuous loss reductions.
Phase 3 (Descriptive Type Constraint Generalization): Only after significant continued scaling does the model begin to generalize descriptive property-entity associations beyond direct memorization, as evidenced by sublinear but rapid growth in metrics for descriptive type checks and downstream unscrambling/conditional generation.
The transition from memorization to generalization in property-entity composition is robustly driven by the structure of the type constraints graph, not just raw exposure count.
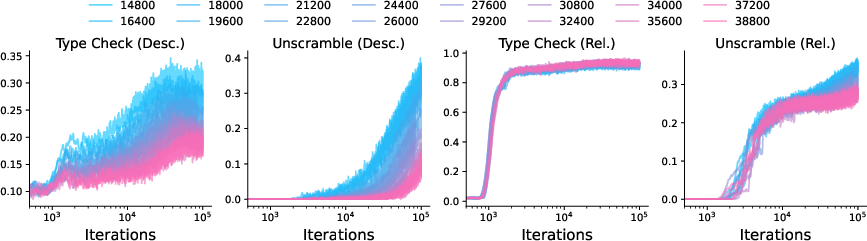
Scaling and the Universality of Emergence: Percolation Transitions
The authors systematically vary the number of descriptive properties (the size of the properties set in the bipartite type graph) and observe the scaling of phase transitions:
Figure 3: Scaling the number of descriptive properties shifts emergent phase transitions, with descriptive type check and unscrambling transitions delayed and altered in magnitude.
Grammar and relative type acquisition are largely invariant to increases in the number of properties; descriptive type check and associated task metrics are delayed and attenuated, indicating control by a distinct structural factor.
The performance curves, especially for descriptive type checks, demonstrate invariant geometric structure, supporting the existence of a universality class for these transitions.
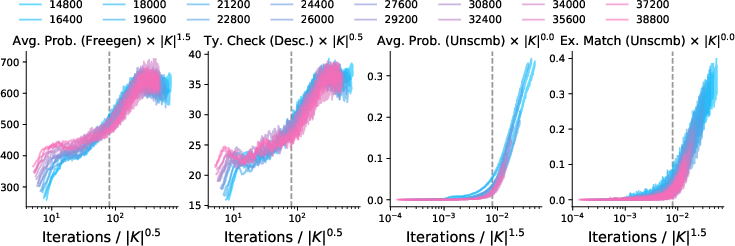
Theoretical Framework: Percolation on Bipartite Graphs
To explain these scaling laws, the authors build an explicit link to percolation theory. Generalization in the entity-property bipartite graph is modeled as the formation of a giant connected component as random associations are revealed during training. The critical edge density for this percolation transition scales as:
pc∼∣E∣∣K∣1
where ∣E∣ and ∣K∣ are the entity and property set cardinalities. Empirically, the iteration at which generalization sets in (e.g., descriptive type check improvement) is found to scale closely with ∣K∣ (fixing ∣E∣), which is consistent with the theoretical prediction.
Figure 4: When x-axes are rescaled by ∣K∣, transitions for descriptive type checks, mean valid property probability, and other metrics collapse, confirming percolation scaling governs emergence.
Strikingly, narrower task abilities (e.g., unscrambling descriptive sentences) exhibit their own robust but differently parameterized scaling, likely reflecting interactions with multiple acquired structures.
Structure Learning Dynamics and Generalization
The study further analyzes the adjacency matrix (entity-property co-occurrence) estimated by the model over training:
Figure 5: The empirical type constraint adjacency matrix densifies and approaches ground-truth as training proceeds, revealing class boundaries and supporting cluster-based generalization.
Rather than requiring complete enumeration of entity-property pairs, the model infers membership in latent concept clusters as soon as the empirical subgraphs percolate, enabling inference of unseen associations and driving performance above memorization bounds.
Robustness Across Scaling Regimes
Extensive experimental appendices demonstrate that the observed phase transitions and percolation scaling laws hold across a large range of number of entities, number of classes, class sizes, and data regimes. The precise scaling exponent for different tasks (e.g., descriptive type checks: ∼0.5, unscrambling descriptive: $1.5$–C0) is robust but task-dependent, suggesting task-specific circuit interactions.
Implications, Limitations, and Future Directions
Mechanistic Understanding of Emergence: The study precisely links abrupt capacity increases to the acquisition of general, reusable data structures, providing a concrete mechanism for so-called "emergent" abilities in neural systems.
Predictivity: The percolation model supports not just post hoc explanations but prospective predictions of when phase changes will occur with respect to data, model, or property scaling—a critical capability for safety and interpretability.
Separation of Structure Layers: Different types of structure (syntax, selectional constraints, latent clusters) can be disentangled and mapped to distinct emergent phases, informing interpretability and intervention strategies.
Universality Classes of Emergence: The geometric invariance and scaling observed point to the existence of universality classes for capability emergence, opening paths for analytical theory and transferability across modalities and architectures.
Caveats: The experiments focus on synthetic data and formal grammars, leaving open questions about transferability to large-scale, natural data/model systems. Extensions to multi-modal, hierarchical, or reinforcement domains will require additional machinery.
Conclusion
The paper establishes that emergent capabilities in Transformers arise via a sequence of phase transitions corresponding to the abrupt acquisition of key data-generating structures. By leveraging percolation theory on bipartite graphs, the authors motivate and validate scaling laws that predict when such transitions occur under data and property expansion. This work provides both conceptual clarity for the study of emergence and practical tools for analysis and prediction of capability jumps in neural systems, forming a theoretical basis for safety, interpretability, and informed scaling in AI models.
“Emergent Mind helps me see which AI papers have caught fire online.”
Philip
Creator, AI Explained on YouTube
Sign up for free to explore the frontiers of research
Discover trending papers, chat with arXiv, and track the latest research shaping the future of science and technology.Discover trending papers, chat with arXiv, and more.