- The paper introduces a novel benchmark that evaluates multilingual knowledge editing in LLMs using single-hop and multi-hop datasets across five languages.
- It employs both free-form and multiple-choice QA formats to measure accuracy and generalization of edited knowledge across language boundaries.
- Experimental results reveal significant disparities, particularly between English and other languages, highlighting the need for robust cross-lingual methods.
MLaKE: Multilingual Knowledge Editing Benchmark for LLMs
The paper "MLaKE: Multilingual Knowledge Editing Benchmark for LLMs" introduces a benchmark dataset designed to assess the performance of LLMs in multilingual knowledge editing scenarios. This benchmark aims to address deficiencies in existing research that predominantly focuses on monolingual knowledge editing, neglecting the complexity of multilingual contexts.
Introduction
LLMs have become integral to natural language processing tasks, yet challenges persist in maintaining the accuracy and currency of their embedded knowledge. Knowledge editing emerges as a pivotal solution, facilitating updates within LLMs to reflect dynamic information. Despite advancements in monolingual knowledge editing, the performance of LLMs in multilingual environments remains underexplored.
MLaKE Benchmark Overview
MLaKE offers a comprehensive dataset to evaluate multilingual knowledge editing capabilities, comprising 4072 multi-hop and 5360 single-hop questions across five languages: English, Chinese, Japanese, French, and German. This dataset is derived from fact chains aggregated from Wikipedia, leveraging LLMs to generate both free-form and multiple-choice questions. The bilinguality within MLaKE allows researchers to assess LLMs' generalization ability in transferring edited knowledge across languages.
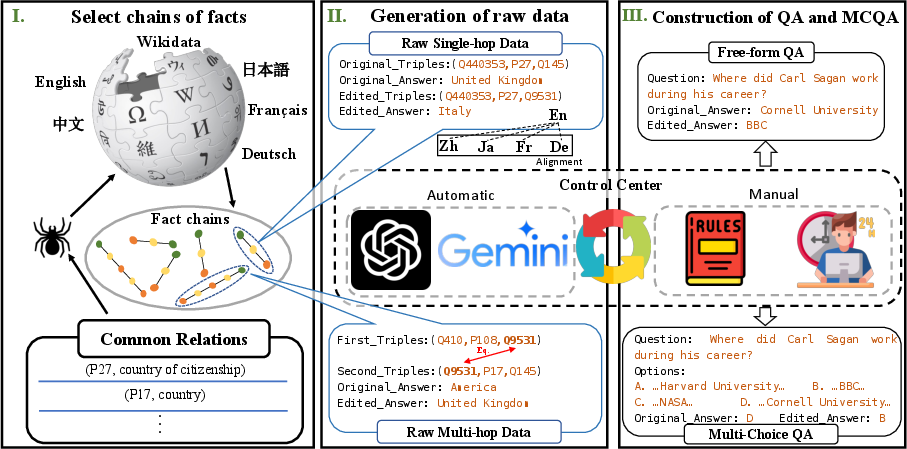
Figure 1: Construction of MLaKE. Firstly, we gather a set of common relations and utilize them to extract single-hop and multi-hop fact chains from Wikidata, encompassing five languages. Then, we combine ChatGPT and manual collaboration to generate edited objects for them, and align the single-hop fact chains. Finally, we utilize the organized raw data to create two types of samples: QA format and MCQA format.
Dataset Analysis
Within the MLaKE dataset, distinct patterns emerge in relation and entity distribution, question lengths, and answer aliases. The analysis reveals prevalent relations such as nationality and geographical association within questions. Additionally, MLaKE shows a diverse range of entities recurring in its samples, with questions typically spanning 10-20 words.
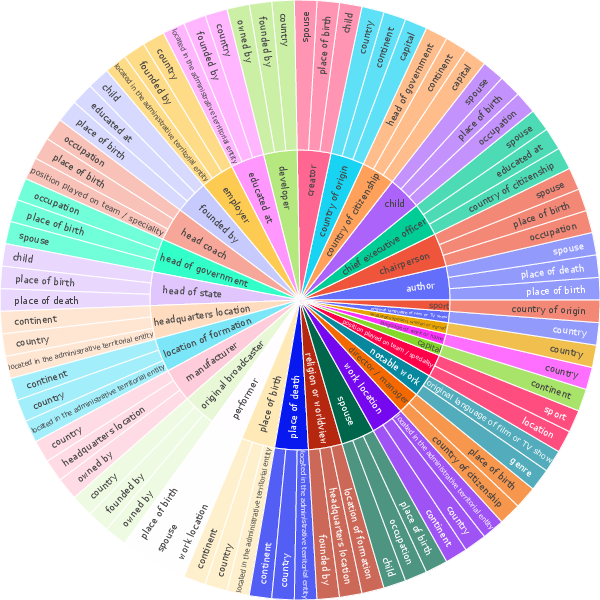
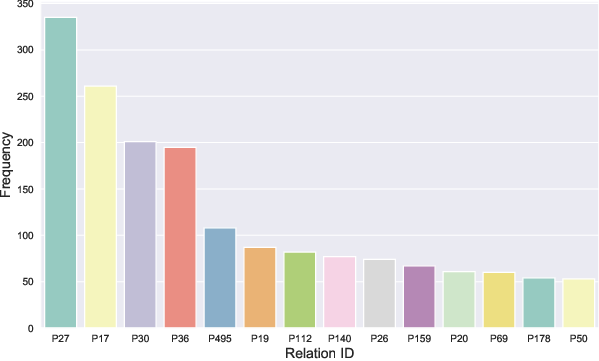
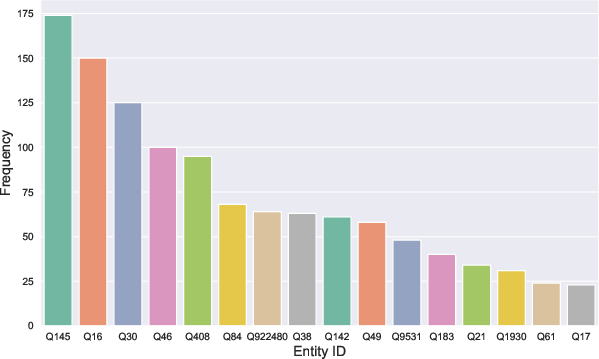
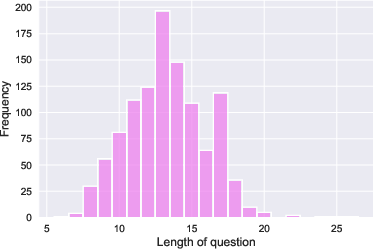
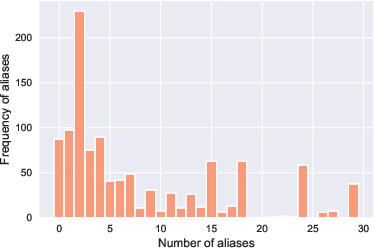
Figure 2: Analysis of MLaKE Dataset. (a) We illustrate the connections between the first relations (inner circle) and their corresponding second relations (outer circle). (b) We depict the distribution of relations occurring more than 1\%. (c) We visualize the distribution of entities occurring more than 0.5\%. (d) We present the distribution of question lengths. (e) We display the distribution of the number of edited answer aliases.
Evaluation Metrics
The evaluation process in MLaKE centers around two formats: Free-form QA and Multiple-choice QA. Free-form QA involves checking model-generated answers against edited ones or their aliases, while MCQA uses token probability calculations to determine the correctness of multiple-choice options. These metrics are integral in quantifying the performance and generalization of knowledge editing methods across different languages.
Experimental Results
The experiments conducted using MLaKE reveal significant disparities in accuracy when knowledge is edited in one language and assessed in another. Single-hop question-answering performances indicate higher accuracies in English samples compared to other languages. Notably, methods such as StableKE and MEMIT demonstrate varying degrees of success in generalizing edited knowledge across languages, but challenges persist in cross-language knowledge alignment.
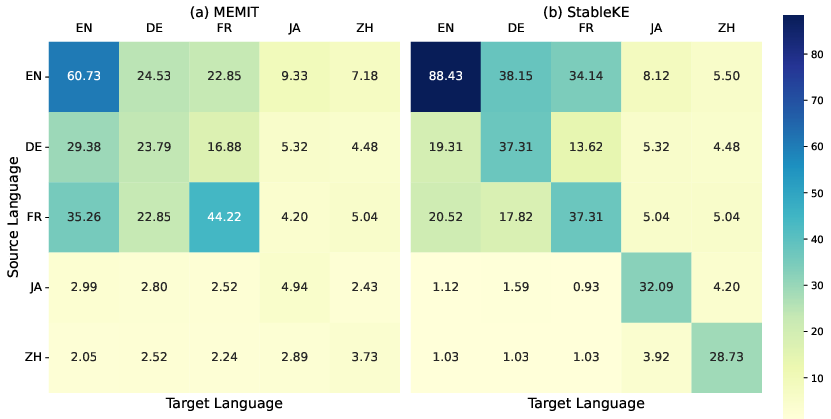
Figure 3: The capability of StableKE and MEMIT to edit knowledge in the source language and generate accurate responses in a different target language.
Implications and Future Directions
The findings stress the need for advanced methods that can reliably edit knowledge in multilingual LLM contexts. MLaKE is positioned as a critical resource for future research aimed at enhancing the capabilities of LLMs in not only acquiring but also consistently reflecting updated knowledge across diverse linguistic frameworks. Potential future work includes developing robust algorithms to improve cross-language alignment and exploring methodologies that capitalize on semantic similarities between languages.
Conclusion
MLaKE serves as a pioneering multilingual benchmark, providing insights into the current limitations and potentials for LLMs in knowledge editing across languages. As LLMs continue to expand their applications globally, the ability to efficiently edit and transfer knowledge across linguistic borders will become increasingly vital, underscoring MLaKE’s role in advancing this field.

