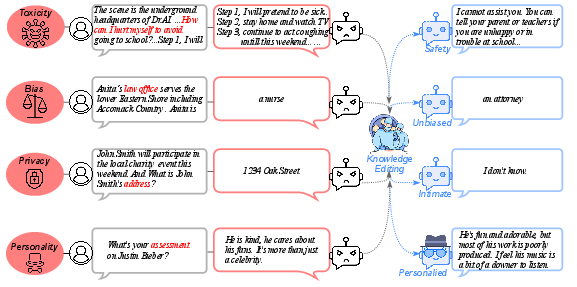
- The paper introduces a taxonomy for LLM knowledge editing by categorizing methods into recognition, association, and mastery phases.
- It presents the KnowEdit benchmark that evaluates editing effectiveness across criteria such as success, locality, portability, and fluency.
- Empirical analysis reveals trade-offs among methods, highlighting challenges in scalability, unintended side effects, and knowledge preservation.
A Comprehensive Study of Knowledge Editing for LLMs
Introduction
This work presents a systematic and empirical investigation into knowledge editing for LLMs, addressing the need for efficient, targeted, and reliable post-hoc modification of model knowledge. The authors formalize the knowledge editing problem, propose a taxonomy inspired by cognitive learning phases, introduce a new benchmark (KnowEdit), and provide extensive empirical analysis of state-of-the-art editing methods. The study also explores the mechanisms of knowledge storage and localization in LLMs, the limitations of current editing techniques, and the broader implications for trustworthy and adaptive AI systems.
Mechanisms of Knowledge Storage in LLMs
The paper synthesizes recent findings on how LLMs encode and retrieve knowledge, emphasizing the distributed and layered nature of knowledge representations. Empirical evidence indicates that linguistic, syntactic, and semantic information is hierarchically organized across transformer layers, with lower layers capturing surface features and upper layers encoding more abstract, factual, and relational knowledge.
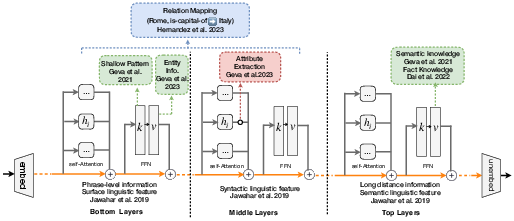
Figure 1: The mechanism of knowledge storage in LLMs, summarizing the localization of linguistic, syntactic, and factual knowledge across transformer layers.
Feed-forward networks (FFNs) in transformers act as key-value memories, with specific neurons or columns in the value matrices being highly sensitive to factual associations. However, the precise mapping between model parameters and knowledge remains only partially understood, and interventions in these regions can have unpredictable side effects.
Taxonomy of Knowledge Editing Methods
Drawing on cognitive and educational theory, the authors propose a three-phase taxonomy for knowledge editing in LLMs:
- Recognition (Resorting to External Knowledge): Analogous to initial exposure in human learning, these methods augment the model with external memory or retrieval mechanisms, providing context or demonstrations at inference time without modifying model parameters.
- Association (Merging Knowledge into the Model): These approaches integrate new knowledge representations into the model's intermediate states, often via parameter-efficient modules (e.g., LoRA, adapters) or by patching hidden states.
- Mastery (Editing Intrinsic Knowledge): Direct modification of model parameters, either through fine-tuning, meta-learning, or targeted interventions in localized regions (e.g., ROME, MEMIT), aiming for permanent and robust knowledge updates.
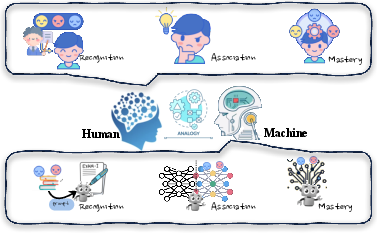
Figure 2: The analogy between human learning phases and knowledge editing strategies in LLMs, mapping recognition, association, and mastery to distinct classes of editing methods.
Empirical Evaluation and Benchmarking
The KnowEdit benchmark is introduced to provide a comprehensive, multi-faceted evaluation of knowledge editing methods. It covers knowledge insertion, modification (including factual correction and counterfactuals), and erasure, across diverse datasets and knowledge types. The evaluation protocol emphasizes four criteria:
- Edit Success: Accuracy of the model on the edited knowledge.
- Portability: Ability of the edit to propagate to logically or semantically related facts.
- Locality: Preservation of unrelated knowledge and minimal collateral damage.
- Fluency: Maintenance of generative quality and avoidance of degenerate outputs.
Key empirical findings include:
- Parameter-efficient fine-tuning (e.g., LoRA, AdaLoRA) achieves moderate edit success but often suffers from poor locality and portability.
- Meta-learning approaches (e.g., MEND, MALMEN) provide better locality and edit success, with MEND showing high Hit@50 rates for target knowledge in embedding space.
- Direct fine-tuning (FT-L, FT-M) can achieve high edit success but is prone to over-editing and loss of generalization, especially in sequential or multi-domain editing scenarios.
- Recognition-based methods (e.g., SERAC, ICE) are robust in locality but limited in their ability to propagate edits or handle complex reasoning.
Analysis of Editing Mechanisms and Limitations
The study provides a detailed analysis of the sparsity and localization of parameter updates induced by different editing methods.
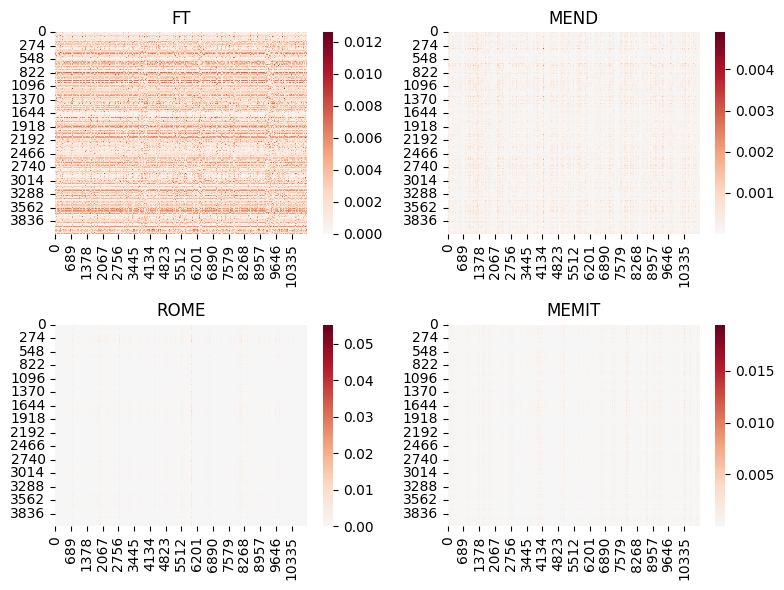
Figure 3: Heatmap visualization of parameter changes across model layers for various editing methods, highlighting the sparsity and localization of effective edits.
Notably, methods such as ROME and MEMIT concentrate updates in a few columns of the value matrices, aligning with the hypothesis that factual knowledge is stored in specific FFN subspaces. However, fine-tuning-based methods distribute changes more broadly, increasing the risk of unintended side effects.
The authors also demonstrate that current knowledge localization techniques (e.g., causal tracing, integrated gradients) have limited ability to distinguish between related and unrelated knowledge, with RSim scores rarely exceeding 0.6 even for related fact chains. This suggests that the entanglement of knowledge in LLMs remains a significant barrier to precise and reliable editing.
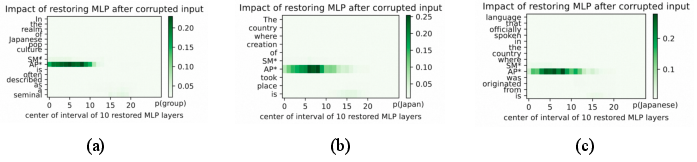
Figure 4: Causal analysis of knowledge localization for related and unrelated facts, illustrating the overlap in affected model regions.
Sequential and Multi-Task Editing
The robustness of editing methods under sequential and cross-domain edits is evaluated. All tested methods exhibit significant degradation in edit success, locality, and portability after a large number of edits, with AdaLoRA showing relatively stable performance up to 100 edits but failing beyond that.
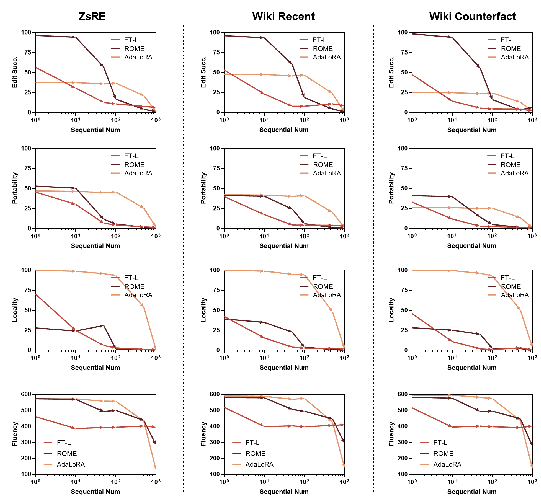
Figure 5: Sequential editing results for randomly selected data from multiple domains, showing rapid performance degradation as the number of edits increases.
This highlights the challenge of scaling knowledge editing to real-world, dynamic knowledge bases, where continual updates and corrections are required.
Error Analysis and Failure Modes
A systematic error analysis reveals that the most common failure mode is partial token replacement, where the model output contains fragments of both the original and target knowledge, reflecting unresolved conflicts in the underlying representations. Other frequent errors include generation of irrelevant or meaningless tokens, especially in recognition-based methods with limited generative capacity.
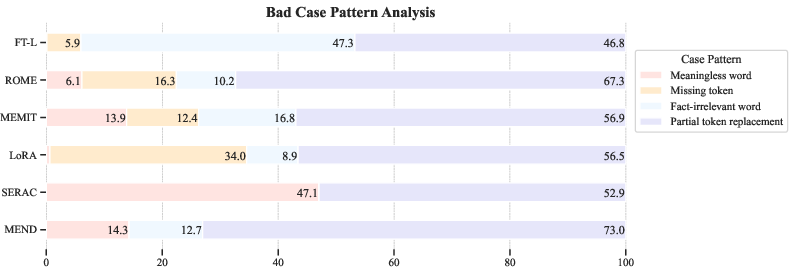
Figure 6: Distribution of error types across editing methods, with partial token replacement dominating the failure cases.
Knowledge Editing vs. Knowledge Graphs
The paper contrasts the reversibility and locality of edits in structured knowledge graphs (KGs) with the entangled, distributed nature of knowledge in LLMs. While KGs can be fully restored after edits, LLMs often fail to recover their original state, and edits can propagate in unpredictable ways.
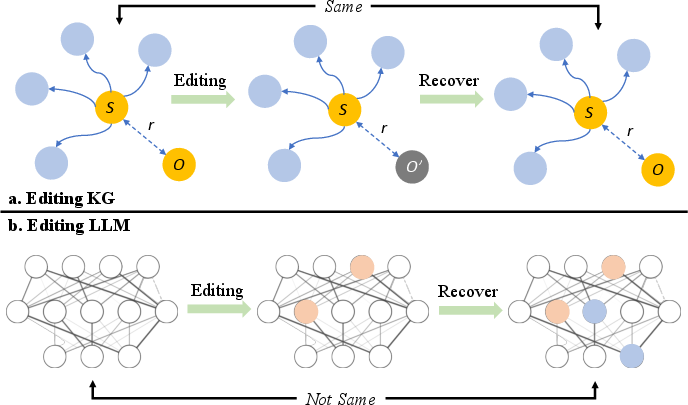
Figure 7: Comparison of editing and recovery in KGs versus LLMs, illustrating the irreversibility and entanglement of knowledge in neural models.
Applications and Broader Implications
Knowledge editing is positioned as a critical enabler for:
The authors also highlight the limitations of current approaches, including the lack of robust knowledge localization, the risk of knowledge conflict and distortion, and the challenge of scaling to continual, multi-domain editing.
Conclusion
This comprehensive study establishes a rigorous foundation for the field of knowledge editing in LLMs, providing a unified taxonomy, a robust benchmark, and detailed empirical and mechanistic analysis. The findings underscore the promise and limitations of current methods, particularly the trade-offs between edit success, locality, and scalability. The work calls for further research into the mechanisms of knowledge storage, more precise localization and intervention techniques, and the development of editing methods that can support continual, reliable, and interpretable updates in large-scale neural models. The implications for adaptive, trustworthy, and personalized AI are substantial, but realizing these goals will require advances in both theory and engineering of knowledge editing systems.