- The paper introduces a scalable framework for precise knowledge editing in LLMs using latent, entity-specific representations.
- It details a novel methodology incorporating an Edit Scope Indicator, a new knowledge block generator, and a KB replacer for targeted internal updates.
- Empirical evaluations show probe accuracies peaking at 80%, demonstrating efficient, large-scale edits while maintaining overall model performance.
Latent Knowledge Scalpel: Precise and Massive Knowledge Editing for LLMs
The paper "Latent Knowledge Scalpel: Precise and Massive Knowledge Editing for LLMs" (LKS) presents an innovative approach to editing factual knowledge in LLMs. The challenges of retaining outdated or incorrect information within LLMs lead to the need for efficient and targeted knowledge updates without extensive retraining. The proposed method, LKS, addresses this by modifying internal representations, focusing on entity-specific knowledge blocks within LLMs.
Introduction to LKS
The conceptual foundation of LKS is based on the possibility of treating internal representations of LLMs as manipulable entities similar to natural language. This research demonstrates that operations typically reserved for natural language, such as entity replacement, can be applied directly to internal entity representations, termed knowledge blocks (KBs). The knowledge editing process employed by LKS is especially geared toward accommodating a vast number of simultaneous edits, overcoming the limitations of prior model editing techniques that suffer from overfitting or computational inefficiency.
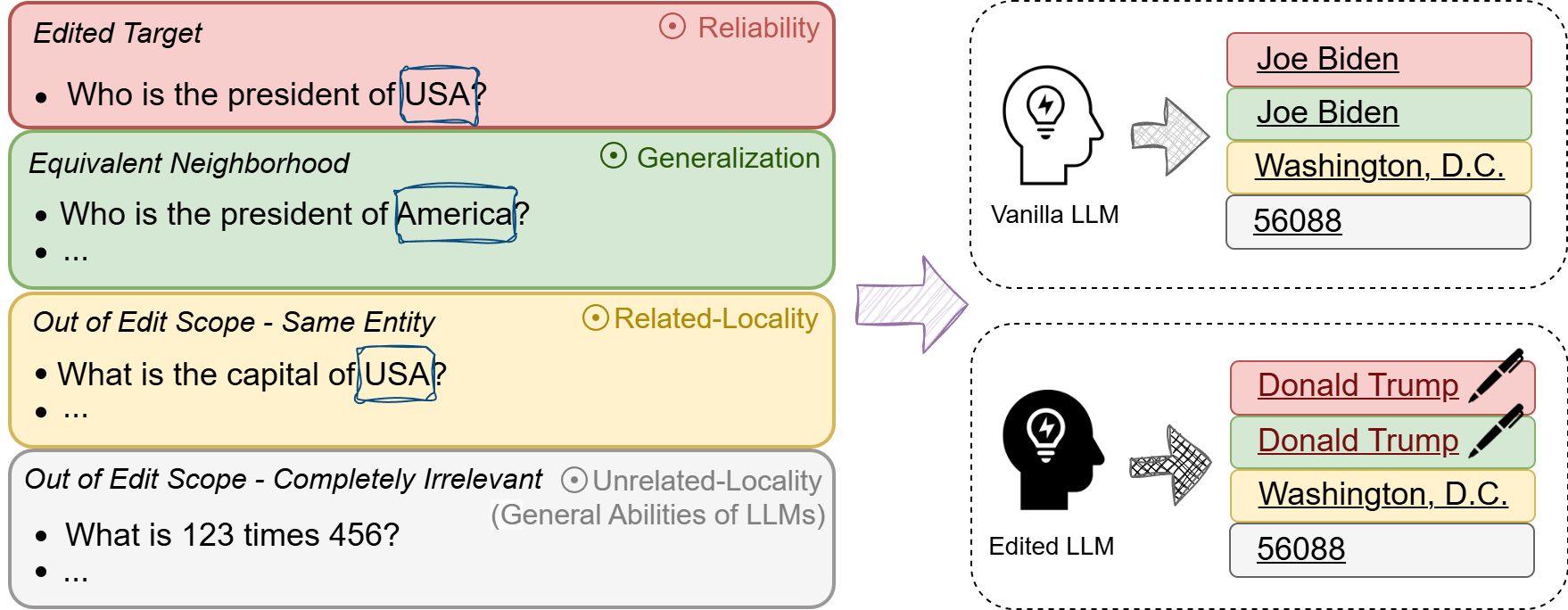
Figure 1: Illustration of model editing. Model editing modifies specific knowledge with minimal impact on unrelated inputs.
Empirical Foundation
Semantic and Syntactic Analysis
An in-depth empirical study was conducted to establish that a single entity's knowledge block within an LLM retains significant semantic information and follows a syntactic structure similar to natural language constructs. Probes designed to distinguish between factual and counterfactual internal representations confirmed the existence of semantic richness within a single KB, achieving probe accuracy exceeding 50% on average and peaking at 80%.
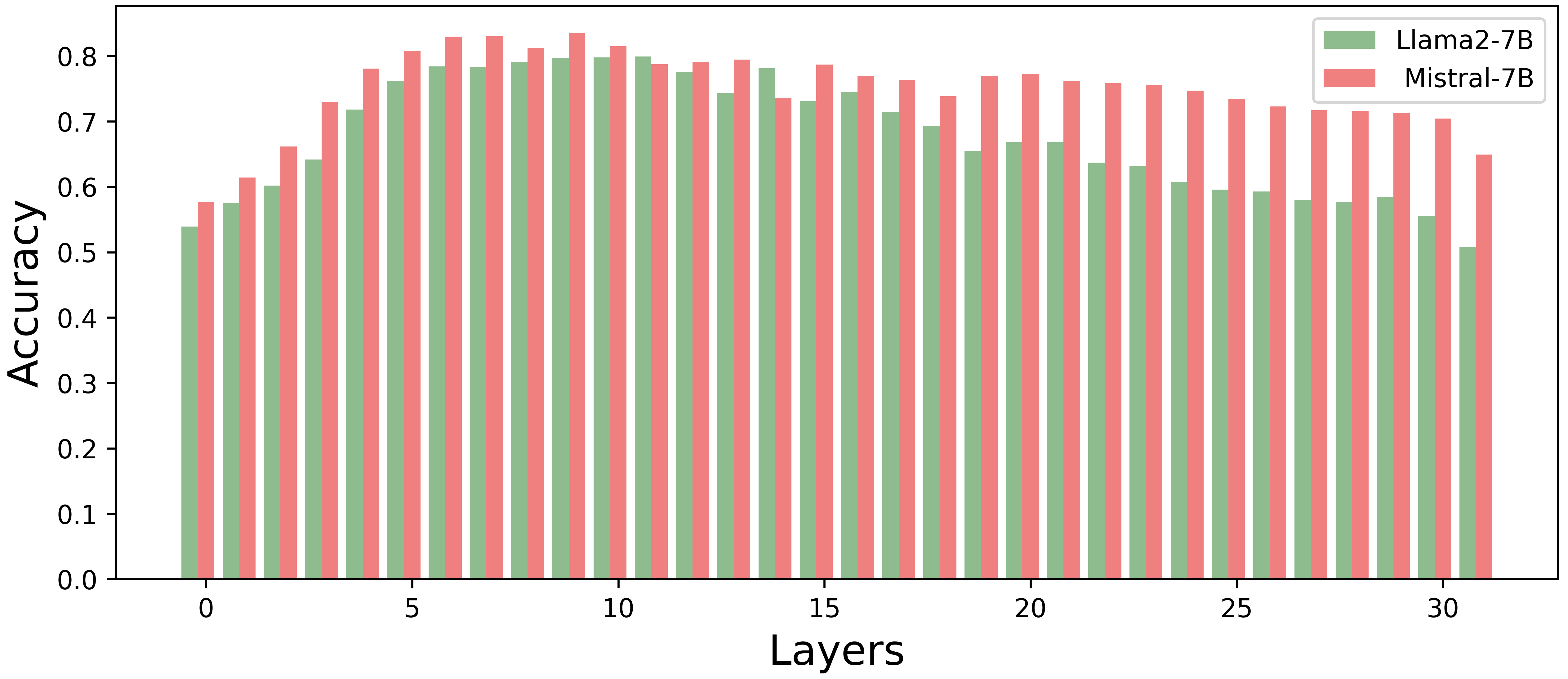
Figure 2: Probe accuracy for identifying factual knowledge across layers in Llama-2-7B and Mistral-7B. The results show that the probe accuracy exceeding 50\% on average and peaking at 80\%, demonstrating that a single entity KB retains semantic information.
Implications of Syntactic Consistency
The research extended to syntactic structuring, demonstrating that replacing entity names in internal representations mirrors the shifts seen in natural language processing. When specific entity KBs are swapped, for instance, the prediction of birthplace changes, suggesting that LLMs' internal structures retain a form accommodating such transformations.
LKS Methodology
LKS Architecture
LKS is structured around a few central components: the Edit Scope Indicator, New KB Generator, and KB Replacer. The Edit Scope Indicator employs fuzzy matching to determine the presence of entities within the editing scope. Upon detection, a simple neural network, trained to produce optimal knowledge blocks, generates new KBs that replace original representations within the LLM.
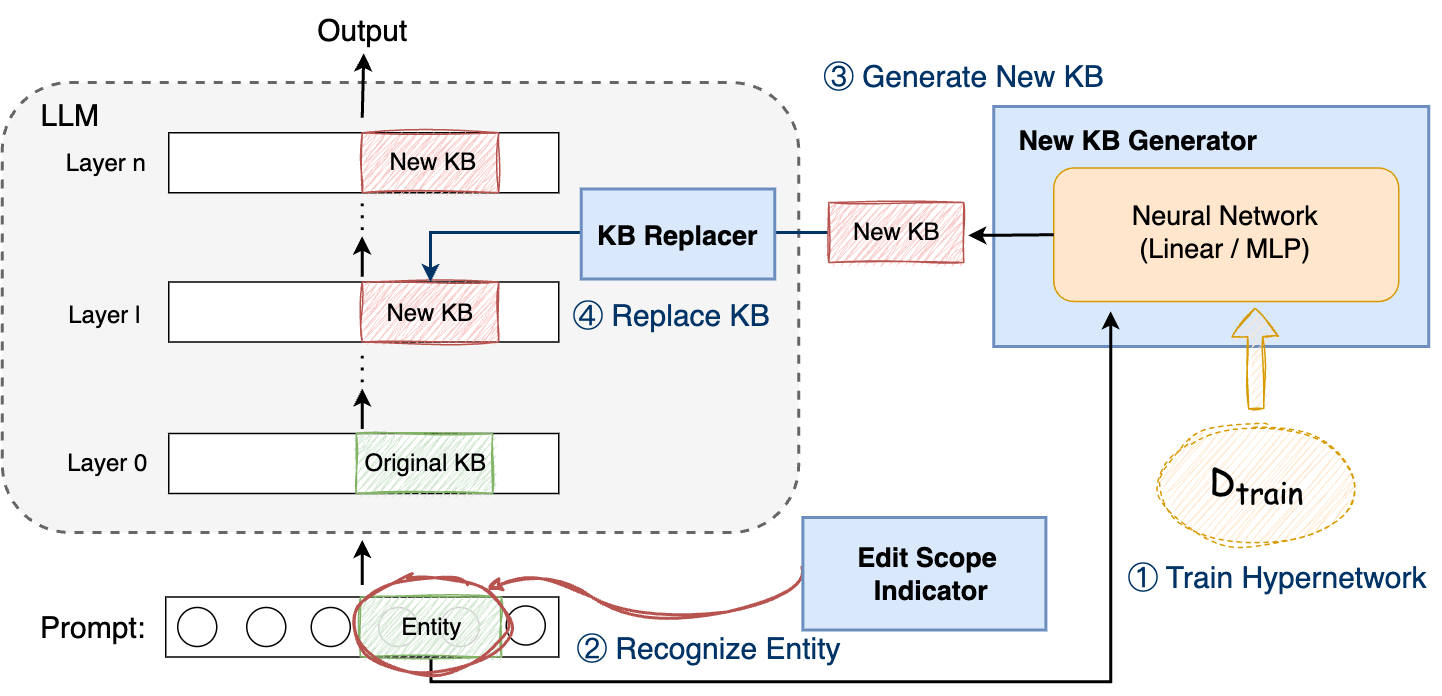
Figure 3: Architecture and Process of LKS.
Building Knowledge Blocks
The process of constructing new knowledge blocks involves extracting pertinent entity knowledge, updating it with target information, and compressing it through a neural network trained on the modified dataset. This results in the LKS being capable of rendering the edited outputs during forward propagation, aligning with target knowledge specifications.
Experimental Evaluation
Comprehensive experimental validation on the zsRE dataset and Counterfact dataset demonstrated LKS's clear advantages in reliability, generality, and locality. LKS maintained high edit performance, accurately executing up to 10,000 simultaneous edits while preserving the LLMs' general abilities across various datasets like GSM8K, SST2, and RTE.
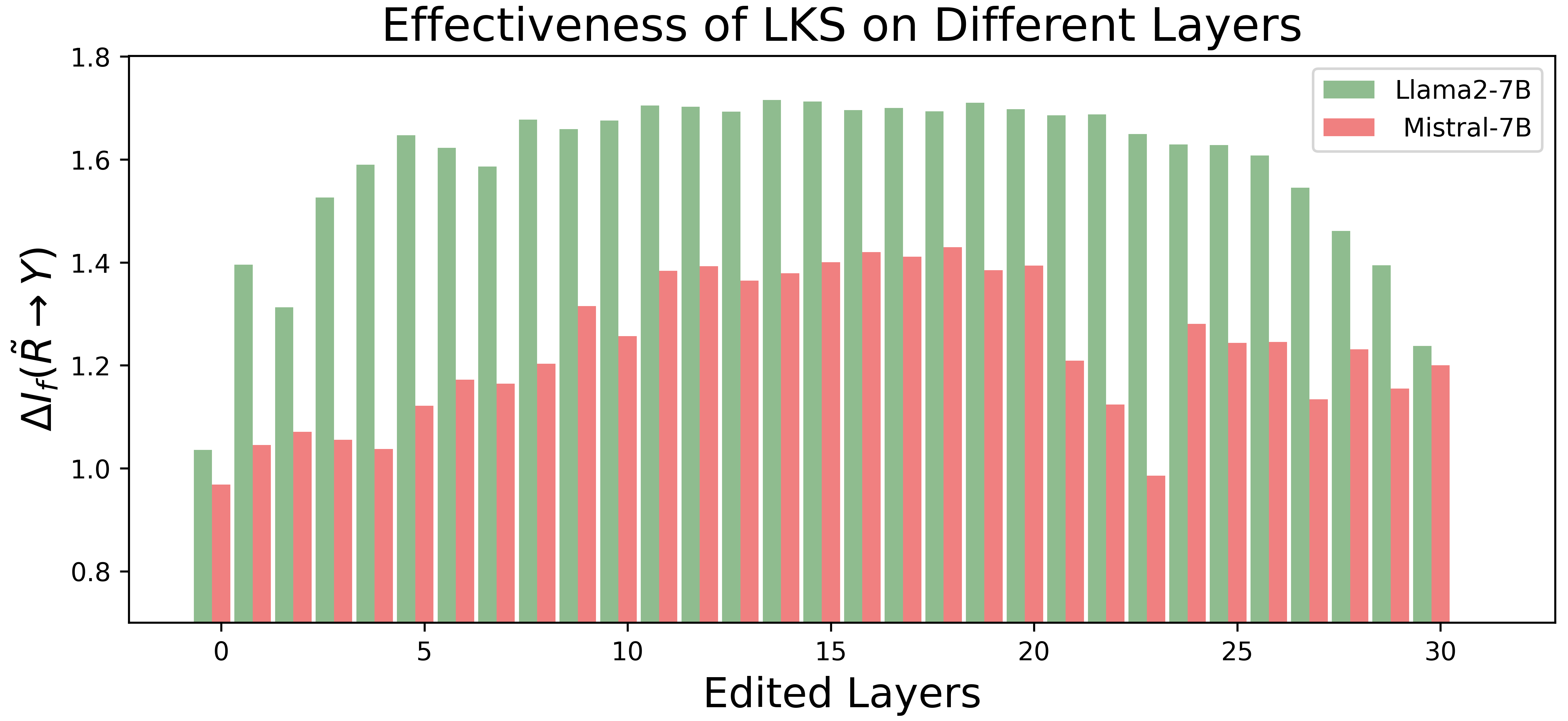
Figure 4: Effectiveness of LKS on different layers, measured by the information gain ΔIf(R~→Y).
Comparative Assessment
LKS was compared against several editing baselines (e.g., MEMIT, GRACE, and others), proving superior in efficiency, maintaining a balance between high edit reliability and preserving unrelated information intact.
Conclusions and Future Directions
LKS presents a technically sound and operationally efficient approach to editing latent knowledge within LLMs. By capitalizing on the latent semantic and syntactic properties embedded within LLMs, LKS provides a scalable solution to targeted knowledge edits. Future work may focus on optimizing the scope recognition mechanisms and extending the technique to other model architectures.
Conclusion
By manipulating latent knowledge structurally similar to how natural language is processed, LKS stands as a promising method for precise and large-scale LLM editing. Its empirical and applied successes suggest broad applicability in contexts requiring swift and extensive model updates, with minimal detriment to overall model performance.

