- The paper introduces an automated scheduler that optimizes multi-tenant DNN inference using ML-driven search to reduce latency and improve resource allocation.
- It leverages a unified intermediate representation and stream-level concurrency controls to manage operator execution across diverse models on GPUs.
- Experiments demonstrate 1.3-1.7x speed-ups over traditional methods, highlighting significant improvements in GPU utilization and performance.
Overview of Automated Runtime-Aware Scheduling for Multi-Tenant DNN Inference on GPU
The paper "Automated Runtime-Aware Scheduling for Multi-Tenant DNN Inference on GPU" presents a sophisticated scheduling framework designed to optimize neural network inference on Graphics Processing Units (GPUs) within multi-tenant scenarios. Multi-tenant inference involves running multiple Deep Neural Network (DNN) models simultaneously, a task that is becoming increasingly common in real-world applications such as autonomous vehicles and large-scale data centers. This paper proposes a resource-aware scheduler that automatically coordinates multi-level DNN inference on GPUs, addressing both graph-level operator scheduling and runtime-level resource management.
Problem Definition and Motivation
The burgeoning use of DNNs in practical applications has necessitated more efficient parallel computing approaches. The inherent complexity in multi-tenant DNN inference arises from the need to manage disparate model structures and operator execution orders while maintaining high resource utilization and minimizing latency. Traditional scheduling mechanisms, such as sequential execution using MPI processing and concurrent execution via NVIDIA's Multi-Stream technology, have shown deficiencies in efficiently transferring this complexity into GPU computation. Specifically, current methodologies suffer from significant resource under-utilization and contention overheads, factors that deeply affect performance.
The paper identifies two primary forms of resource contention: compute-bound and memory-bound operations, which must be managed effectively to improve GPU performance. Given the significant computational complexity tied to multi-tenant scenarios, scalable and automated scheduling systems are required to alleviate manual search burdens and to address the operator concurrency anomalies.
Proposed Scheduling Framework
Fine-Grained Problem Abstraction
The framework abstracts multi-tenant DNN inference scheduling as a concurrency control problem. By utilizing GPU streams and synchronization primitives (termed pointers), the model sequences are split into manageable stages that allow for precise control of operator concurrency across streams. This addresses both local operator contention and global model structure divergence:

Figure 1: Overview of Our Proposed Automated Scheduling Strategy Search Framework.
The scheduling strategy is designed around a unified Intermediate Representation (IR), where each model's operator sequence is assigned to a separate GPU processing stream. Synchronization barriers are inserted to create stages within each stream, allowing detailed control over the operator execution.
This structural representation of scheduling strategies leverages stream-level concurrency, stage splitting, and precise pointer integration to manage operator-level concurrency control. Transforming scheduling into an IR-based optimization problem facilitates automated ML-based search algorithms to identify optimal scheduling solutions.
Automated Scheduling Search
The scheduling search space is transformed to optimize the stream pointer index matrix through ML-based algorithms. Two search algorithms, namely random sampling and coordinate descent, are proposed to efficiently navigate this space. A profiling-based cost model enables runtime-aware performance evaluation, integral for translating the scheduling problem into a search task:

Figure 2: The automated scheduling search framework overview.
Experimental Analysis
Experiments demonstrate consistent acceleration improvements, ranging from 1.3 to 1.7 times compared to traditional libraries and scheduling techniques such as CuDNN, TVM, and NVIDIA's Multi-Stream execution. Notable improvements were observed in highly non-balanced model combinations, confirming the framework's ability to ensure balanced resource utilization across varied scenarios through optimized scheduling.
The framework also scaled effectively across different GPU platforms and multi-model scenarios, illustrating its robustness and adaptability. The profiling results indicate enhanced GPU utilization in terms of active warps per second, aligning with the speed-up metrics:
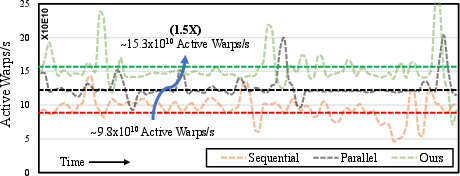
Figure 3: Enhanced GPU Utilization Statistics. The number of active warps per second shows that our schedule could yield continuously better SM utilization.
Conclusion
The proposed framework provides a comprehensive solution to multi-tenant DNN inference scheduling on GPUs by combining resource profiling with machine learning-driven automated search techniques. As the complexity of DNN models on parallel computing platforms continues to evolve, such frameworks will be vital for optimizing runtime efficiency and scaling applications across diverse hardware platforms. The research outlines significant advances in automated scheduling, contributing to future developments in optimized AI deployment strategies.

