- The paper presents ESG, a pipeline-conscious scheduling algorithm that enhances SLO hit rates by 61–80% while reducing costs by up to 187% through efficient GPU sharing.
- It employs a dual-bladed A*-search strategy and Application-Function-Wise job queues to optimize configuration spaces and minimize cross-function communication overhead.
- ESG_Dispatch dynamically assigns jobs based on data locality and resource availability, resulting in lower latency and improved resource utilization in heterogeneous environments.
Introduction
The paper introduces a novel scheduling algorithm, ESG, designed to improve the efficiency and cost-effectiveness of DNN workflows on serverless platforms that utilize shareable GPUs. This work addresses the significant challenges associated with scheduling in heterogeneous computing environments by treating shareable GPUs as primary scheduling factors. ESG employs advanced search techniques to optimize the resource allocation and SLO (Service Level Objective) fulfillment, significantly outperforming existing methods.
System Architecture and Design
ESG is implemented within the serverless framework of OpenWhisk, which serves as the underlying architecture for function execution. OpenWhisk is a distributed platform that automates resource scaling and task scheduling. The Controller component, which handles task scheduling and resource allocation, is central to ESG's functionality.
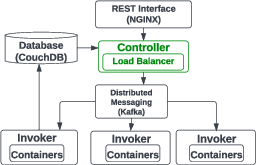
Figure 1: OpenWhisk architecture. Controller is where scheduling happens.
To address the inherent complexity of serverless environments augmented by GPU sharing, ESG introduces Application-Function-Wise (AFW) job queues. This mechanism allows for precise resource allocation by grouping jobs that share the same function and application context. ESG's scheduling strategy is driven by workflow optimizations that minimize cross-function communication overhead and adaptively configure resource allocations.
ESG Algorithm
ESG consists of two core algorithms: ESG_1Q and ESG_Dispatch.
ESG_1Q Algorithm
ESG_1Q constructs scheduling configurations using an optimality-guided approach inspired by A*-search, enhanced with a dual-bladed pruning strategy. This enhancement expedites the exploration of potential configurations by eliminating suboptimal paths early in the search process.
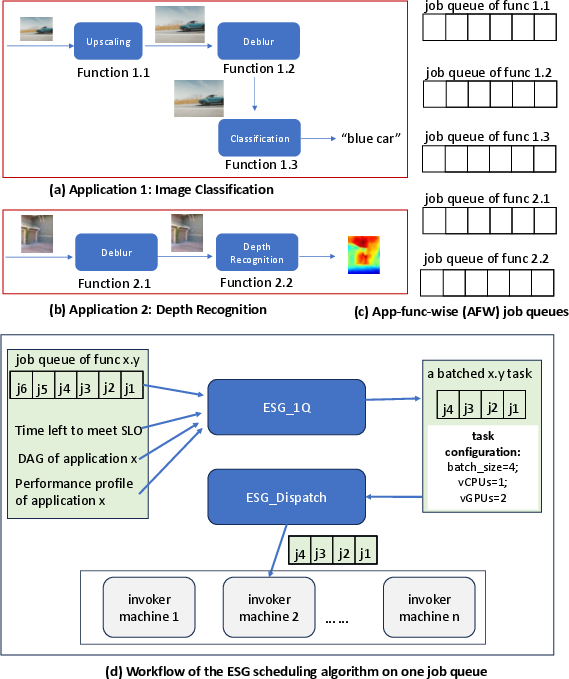
Figure 2: The app-func-wise (AFW) job queues of two example ML-based applications, and the ESG algorithm workflow in handling one job queue.
By leveraging dual-blade pruning, ESG_1Q effectively manages the vast configuration spaces introduced by the combination of batch sizes, vCPU, and vGPU assignments, thereby aligning execution timings closely with SLO requirements and minimizing resource utilization.

Figure 3: (a) Top: Example of the configuration space of a three-function application and two configuration paths in the space.
ESG_Dispatch Algorithm
ESG_Dispatch manages the dynamic assignment of jobs to worker nodes, prioritizing data locality and resource availability to minimize latency. It selectively attempts to execute functions on machines already containing prerequisite data to reduce data transfer times. This intelligent dispatch approach enhances performance by leveraging local data cache coherency.
Extensive evaluations across multiple workloads demonstrate ESG's capability to sustain high SLO hit rates while using fewer resources than state-of-the-art methods. ESG consistently reported SLO hit improvements ranging from 61% to 80% with cost savings between 47% to 187% compared to baseline techniques.
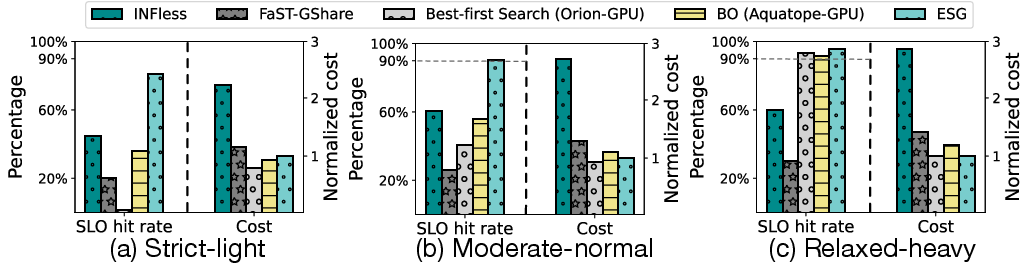
Figure 4: The average SLO hit rate and the cost (normalized to ESG cost) under different SLO and workload settings. The left y-axis is for the SLO hit rate and the higher is better. The right y-axis is for the cost and the lower is better.
Implementation Considerations
When deploying ESG, the architecture should ensure that computing nodes are equipped with hardware capable of supporting GPU partitioning techniques (e.g., NVIDIA MIG) to fully exploit GPU sharing capabilities. The algorithm's scalability is maintained through a dominator-based method that handles function grouping within workflow DAGs. This requires careful configuration to balance function stage sizes against real-time execution constraints.
Conclusion
ESG advances serverless scheduling practices by integrating GPU sharing directly into the optimization process, balancing efficiency and cost without compromising the quality of service. The algorithm's dynamic adaptation to resource status and workload variations makes it particularly suitable for large-scale ML inference tasks in heterogeneous cloud environments. As serverless computing continues to mature, ESG's innovations will form a foundation for subsequent developments in adaptive, resource-aware scheduling solutions.