- The paper introduces Plan2Explore, a self-supervised RL agent that leverages ensemble disagreement and latent dynamics to maximize exploration efficiency.
- The method employs a recurrent state-space model with CNN encoders to predict latent states and reconstruct high-dimensional observations during planning.
- Empirical results demonstrate strong zero- and few-shot generalization on DM Control Suite tasks, outperforming prior self-supervised approaches.
Planning to Explore via Self-Supervised World Models: Technical Summary and Implications
Introduction and Motivation
The paper introduces Plan2Explore, a self-supervised RL agent designed to address two central challenges in model-based RL: sample-efficient exploration and rapid adaptation to unseen tasks. The method is motivated by the inefficiency of task-specific RL, which requires repeated environment interaction for each new task, and by the limitations of model-free intrinsic motivation approaches that compute novelty only retrospectively. Plan2Explore leverages planning in learned latent space to seek out expected future novelty, enabling the agent to build a global world model from high-dimensional observations (pixels) without access to extrinsic rewards during exploration.
Methodology
Latent Dynamics World Model
Plan2Explore builds on the latent dynamics model architecture of PlaNet, employing a recurrent state-space model (RSSM) with a CNN encoder for image observations. The model predicts future latent states, rewards, and reconstructs observations, trained jointly via the ELBO objective. This compact latent representation enables efficient parallel prediction of long-horizon trajectories.
Planning to Explore via Latent Disagreement
Exploration is driven by maximizing expected information gain, operationalized as ensemble disagreement in latent predictions. An ensemble of K one-step models predicts the next latent embedding ht+1 given the current latent state st and action at. The variance of the ensemble's predictions quantifies epistemic uncertainty, serving as the intrinsic reward for the exploration policy. The exploration policy is optimized in imagination using Dreamer, allowing for efficient policy learning without additional environment interaction.
(Figure 1)
Figure 1: The agent leverages planning in latent space to explore without task-specific rewards, building a global world model for rapid adaptation to multiple downstream tasks.
Zero- and Few-Shot Task Adaptation
After the exploration phase, the agent is provided with downstream reward functions and adapts to new tasks by training task policies in imagination using the learned world model. Zero-shot adaptation uses only the collected data, while few-shot adaptation incorporates a small number of task-specific episodes to further refine the policy.
Experimental Results
Zero-Shot Generalization
Plan2Explore demonstrates strong zero-shot performance across 20 DM Control Suite tasks from raw pixels, often matching or exceeding prior self-supervised methods and approaching the performance of Dreamer, which has access to task rewards during exploration. Notably, Plan2Explore outperforms Dreamer on the hopper hop task in the zero-shot setting.
(Figure 2)
Figure 2: Zero-shot RL performance from raw pixels; Plan2Explore achieves state-of-the-art results and is competitive with supervised Dreamer.
Few-Shot Adaptation
With only 1000 exploratory episodes and 100–150 task-specific episodes, Plan2Explore rapidly adapts to new tasks, matching or surpassing the performance of fully supervised agents. This highlights the data efficiency and transferability of the learned world model.
(Figure 3)
Figure 3: Few-shot adaptation performance; Plan2Explore adapts rapidly and matches supervised RL with minimal task-specific data.
Multitask Generalization
Plan2Explore's world model generalizes to multiple tasks within the same environment, unlike task-specific models (e.g., Dreamer trained on 'run forward'), which fail to transfer to other tasks such as running backward or flipping. This demonstrates the global nature of the self-supervised world model.
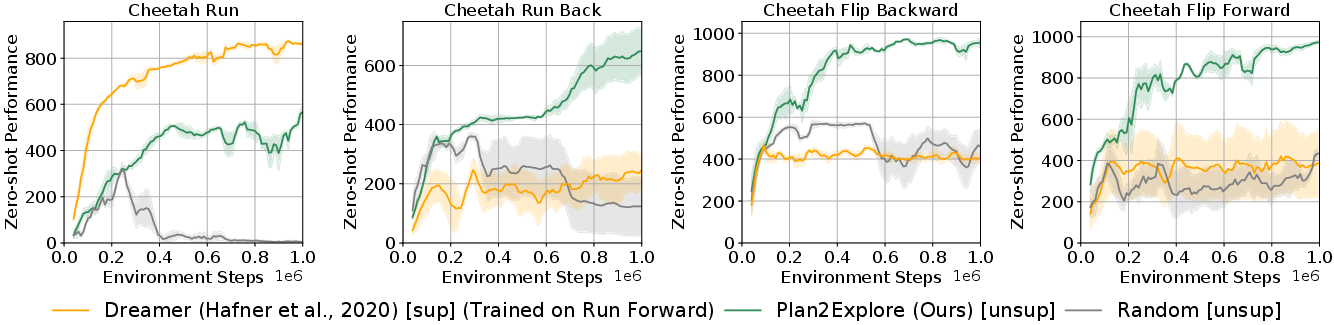
Figure 4: Task-specific models (Dreamer) fail to generalize, while Plan2Explore achieves strong zero-shot performance across multiple cheetah tasks.
Full Suite Evaluation
Comprehensive evaluation on all DM Control Suite tasks confirms that Plan2Explore consistently achieves state-of-the-art zero-shot performance among self-supervised agents, and is competitive with supervised RL.
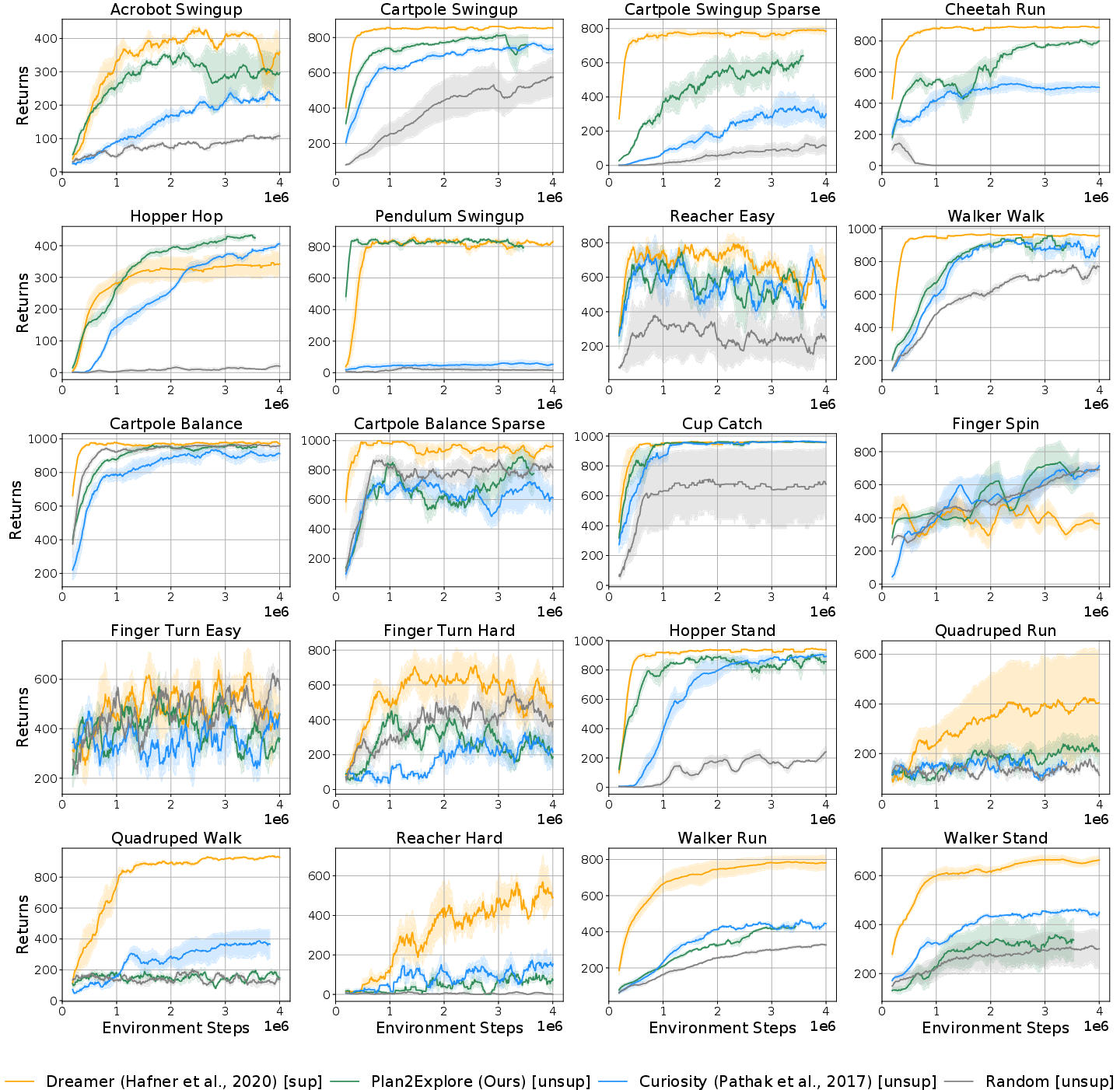
Figure 5: Zero-shot performance across all DM Control Suite tasks; Plan2Explore outperforms other self-supervised agents and approaches supervised Dreamer.
Theoretical Implications
The use of ensemble disagreement as an intrinsic reward is theoretically grounded in expected information gain, capturing epistemic uncertainty while being robust to aleatoric noise. This connection provides a principled justification for the exploration objective and aligns with optimal Bayesian experiment design. The empirical variance of ensemble predictions serves as a tractable proxy for mutual information between model parameters and future observations.
Practical Considerations
- Computational Efficiency: The ensemble of lightweight one-step models adds minimal overhead and can be trained in parallel. Planning in latent space enables efficient long-horizon rollouts.
- Scalability: The method scales to high-dimensional visual observations, unlike prior approaches restricted to low-dimensional state spaces.
- Deployment: Plan2Explore is suitable for real-world scenarios where task specifications are unknown during exploration and data collection is expensive.
- Limitations: Performance depends on the accuracy of the learned world model; environments with high stochasticity or partial observability may challenge model fidelity.
Implications and Future Directions
Plan2Explore advances self-supervised RL by enabling agents to build transferable world models through efficient, task-agnostic exploration. This paradigm supports rapid adaptation to new tasks with minimal additional data, suggesting a path toward scalable, general-purpose RL systems. Future work may explore:
- Extending latent disagreement to richer uncertainty quantification (e.g., Bayesian neural networks).
- Integrating hierarchical exploration strategies for compositional tasks.
- Applying the method to real-world robotics and autonomous systems with complex sensory inputs.
- Investigating robustness to non-stationary environments and domain shifts.
Conclusion
Plan2Explore presents a principled and practical approach to self-supervised exploration in model-based RL, leveraging planning in latent space and ensemble disagreement to efficiently build global world models from high-dimensional observations. The method achieves strong zero- and few-shot generalization across diverse tasks, outperforming prior self-supervised agents and approaching supervised RL performance. Theoretical grounding in information gain and empirical results suggest that planning to explore via self-supervised world models is a promising direction for scalable, generalizable RL.