- The paper's main contribution is introducing LEXA, which decomposes tasks into goal discovery and achievement using world models and imagined rollouts.
- It leverages a recurrent state space model (RSSM) to process high-dimensional images and optimizes separate explorer and achiever policies for enhanced performance.
- Experimental results across visual domains demonstrate significant improvements over traditional unsupervised methods such as SkewFit.
Discovering and Achieving Goals via World Models
Introduction
The paper "Discovering and Achieving Goals via World Models" investigates a novel approach for artificial agents to solve diverse tasks in complex visual environments without supervision by introducing Latent Explorer Achiever (LEXA). This approach decomposes the problem into discovering new goals and learning to achieve them, leveraging a world model to train both an explorer and an achiever policy using imagined rollouts. This methodology offers significant improvements over existing unsupervised goal-reaching strategies by focusing on foresight exploration and zero-shot goal achievement.
Latent Explorer Achiever (LEXA) Framework
LEXA is an unsupervised RL agent designed to discover and achieve a plethora of goals by internally modeling its environment. It employs a Recurrent State Space Model (RSSM) to process high-dimensional input images, predict future states, and facilitate training of two distinct policies: the explorer and the achiever.
World Model
The world model in LEXA uses RSSM, which includes components like an encoder, posterior, dynamics, and image decoder to encapsulate the environment efficiently. This model is trained through maximizing the evidence lower bound (ELBO) and utilizes compact state representations for planning, reducing the prediction errors typically accumulated when performing predictions directly in the image space.
Explorer Policy
The explorer policy within LEXA is designed to locate surprising and informative environment states by using imagined trajectories as opposed to dangerously exploring in reality. It optimizes exploration rewards by estimating the epistemic uncertainty of ensemble transition functions, using variance as a proxy for potential information gain.
Achiever Policy
Contrary to relying on previous data driven by hindsight relabeling, the achiever policy maximizes a goal-reaching reward based on a distance function computed in the latent space or by predicting temporal distances by imagined rollouts. This policy uses a goal image sampled from the replay buffer to train in imagination, allowing for clear unsupervised goal-reaching without additional retraining.
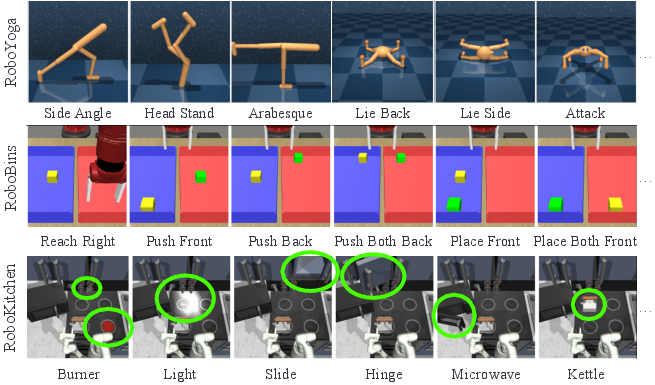
Figure 1: We benchmark LEXA across four visual control environments. A representative sample of the test-time goals is shown here.
Experimental Results
The experimental evaluation demonstrates LEXA's capability to outperform prior work in both existing benchmarks and a newly proposed, more challenging benchmark across four domains: RoboYoga, RoboBins, RoboKitchen, and visual control environments.
Benchmarks and Results
- RoboYoga: LEXA demonstrates superior performance using cosine distances in directly controllable environments, handling task complexity effectively by leveraging latent space assessments.
- RoboBins: In environments requiring interaction with separate objects, the temporal distance function outperforms cosine distances by focusing on manipulation sequences, revealing exceptional task success rates compared to previous approaches.
- RoboKitchen: LEXA's ability to handle diverse object interactions in environments like RoboKitchen highlights its sophisticated exploration and policy execution abilities, succeeding in tasks that prior methodologies fail to address adequately.
- Prior Benchmarks: LEXA outperforms existing methods, even on simpler benchmarks like SkewFit, showcasing its robustness and flexibility in complex goal-reaching scenarios.
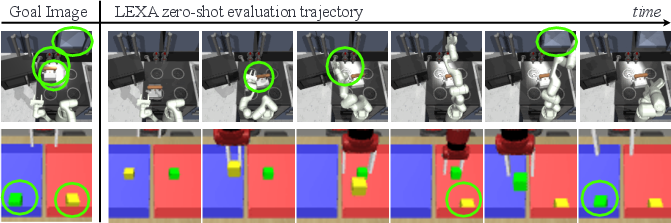
Figure 2: Successful LEXA trajectories. When given a goal image from the test set, LEXA's achiever is used in the environment to reach that image.
Component Analysis
Ablation studies signify the importance of each component within LEXA. Notably, the separation of explorer and achiever policies improves goal discovery and task fulfillment, while negative sampling accelerates learning. Training in imagination further boosts policy stability and overall success rates.
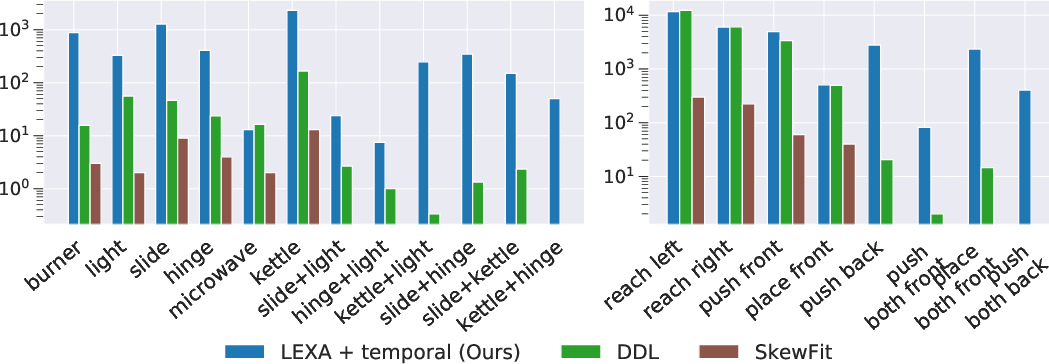
Figure 3: Coincidental goal success achieved during the unsupervised exploration phase. The forward-looking explorer policy of LEXA results in substantially better coverage compared to SkewFit, a popular method for goal-based exploration.
Implications and Future Work
LEXA advances the capabilities of unsupervised RL by adopting model-based foresight for goal exploration, removing the need for explicit supervision, and performing well in non-trivial environments. Future work may center around scaling LEXA to real-world applications, investigating diverse goal input modalities like language descriptions, and further improving the component methodologies for enhanced performance.
Conclusion
In conclusion, LEXA represents a significant step in unsupervised RL, offering a robust and scalable solution for achieving diverse goals in complex environments. Its innovative use of world models for exploration and policy training provides a promising framework for future breakthroughs in autonomous agent research and applications.