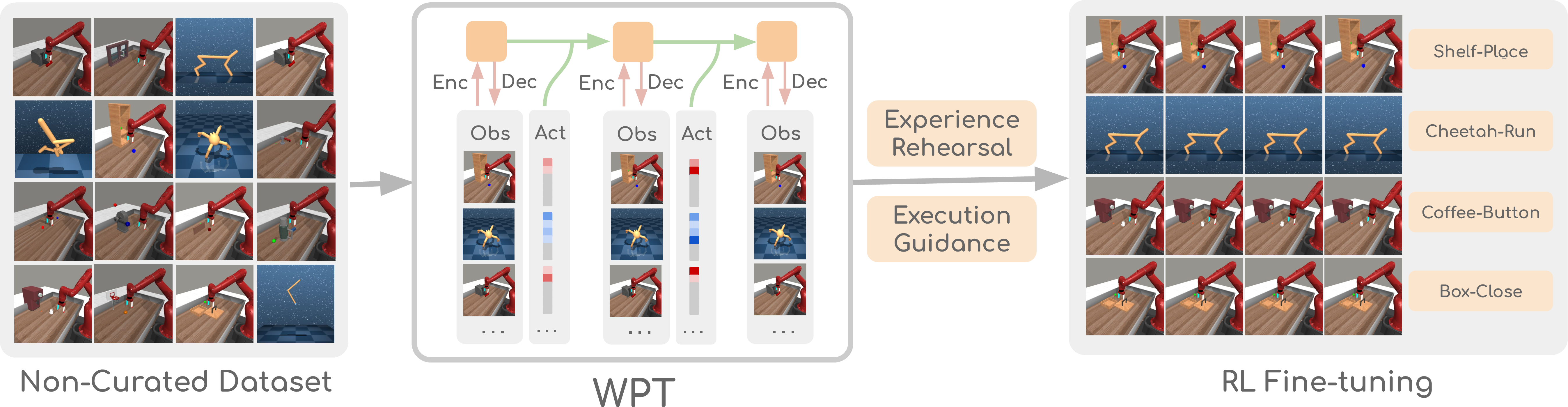
- The paper introduces a novel method to pre-train a multi-embodiment world model using non-curated data, eliminating the need for costly curated datasets.
- The paper demonstrates that integrating retrieval-based experience rehearsal with execution guidance significantly enhances sample efficiency and stabilizes fine-tuning.
- The paper's experiments reveal a 35% performance boost over baselines in continuous control tasks, highlighting its potential for fast task adaptation in robotics.
Generalist World Model Pre-Training for Efficient Reinforcement Learning
This paper introduces a novel approach to reinforcement learning (RL) that leverages non-curated offline data to improve sample efficiency and enable fast task adaptation. The core idea revolves around pre-training a generalist world model (WPT) on a diverse dataset comprising reward-free, non-expert, and multi-embodiment data. This pre-trained world model is then fine-tuned using online interaction, augmented by retrieval-based experience rehearsal and execution guidance, to achieve superior RL performance across a wide range of tasks. The approach addresses a critical gap in existing methods that often require curated datasets with expert demonstrations or reward labels, which are costly and limit their practical applicability.
Methodology: WPT with Experience Rehearsal and Execution Guidance
The WPT framework consists of two primary stages: multi-embodiment world model pre-training and RL-based fine-tuning.
Multi-Embodiment World Model Pre-training: The authors train a single, multi-task world model on non-curated offline data. This is achieved using a recurrent state space model (RSSM) with modifications to handle diverse data sources. The key modifications include removing task-related losses, padding actions to unify action spaces across different embodiments, and scaling the model size. The model is trained to minimize a loss function that combines pixel reconstruction and latent state consistency, enabling it to learn the dynamics of multiple embodiments.
RL-Based Fine-tuning: In the fine-tuning stage, the agent interacts with the environment to collect new data, which is used to learn a reward function and fine-tune the world model. The policy is trained using imagined trajectories generated by rolling out the policy within the world model. To address challenges in hard-exploration tasks, the authors introduce two key techniques:
Experimental Results: Sample Efficiency and Task Adaptation
The WPT framework was evaluated on 72 pixel-based continuous control tasks covering locomotion and manipulation with different action spaces, hard exploration, high dimensions, and complex dynamics. The results demonstrate that WPT significantly outperforms existing methods in terms of sample efficiency. Specifically, WPT achieves 35.65\% and 35\% higher normalized scores compared to DrQ v2 and Dreamer v3, respectively, under a limited sample budget of 150k samples (Figure 2).
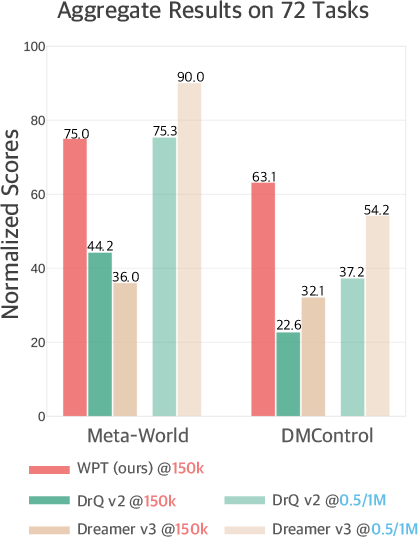
Figure 2: The aggregate performance on 50 manipulation tasks from Meta-World and 22 locomotion tasks from DMControl with pixel inputs, illustrating WPT's improved sample efficiency.
Moreover, the framework enables fast task adaptation, allowing the agent to continually adapt its skill to new tasks. In a continual learning experiment using an Ant robot, WPT significantly outperformed a standard continual learning baseline. These results highlight the potential of WPT for lifelong learning in robotic agents (Figure 3).
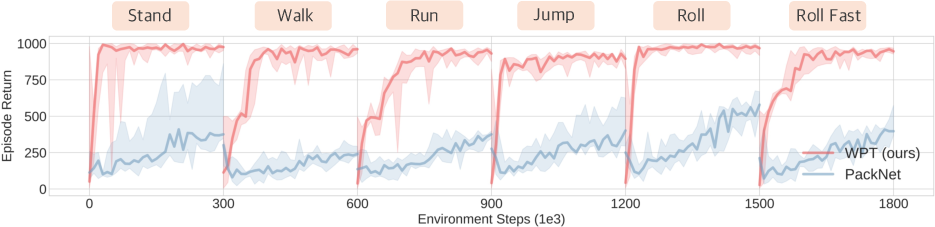
Figure 3: Performance comparison of WPT against a widely used baseline in a task adaptation scenario, showcasing WPT's ability to quickly adapt to new tasks.
Ablation studies were conducted to investigate the role of each component in the WPT framework (Figure 4). The results indicate that world model pre-training alone can be effective when the offline dataset consists of diverse trajectories. However, the combination of world model pre-training, retrieval-based experience rehearsal, and execution guidance is crucial for achieving strong performance across a wide range of tasks.
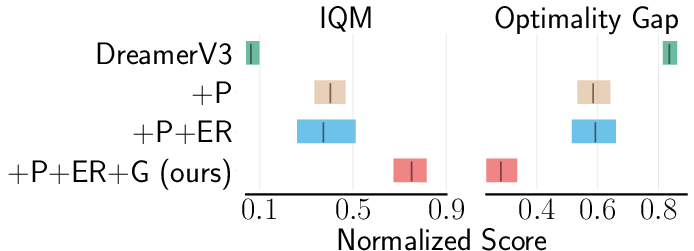
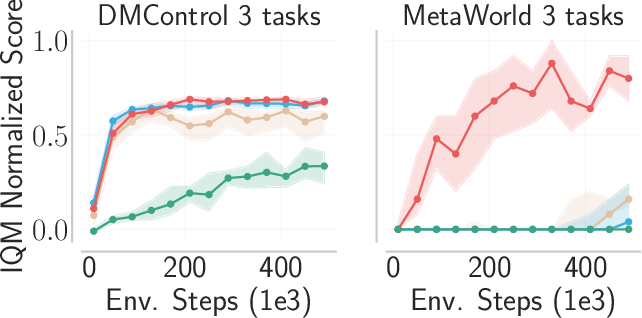
Figure 4: This ablation study shows the impact of each component of WPT, including world model pre-training, experience rehearsal, and execution guidance, on RL performance.
Implications and Future Directions
The WPT framework has significant implications for the field of RL, particularly in robotics and autonomous systems. By demonstrating the feasibility of leveraging non-curated offline data, this research unlocks a vast pool of readily available data for pre-training RL agents. This can significantly reduce the cost and effort associated with data collection, making RL more accessible for real-world applications. The ability of WPT to enable fast task adaptation also opens up new possibilities for lifelong learning agents that can continuously acquire new skills and adapt to changing environments.
Future research directions could focus on extending WPT to real-world applications, exploring novel world model architectures, and developing more sophisticated techniques for experience rehearsal and execution guidance. Additionally, investigating the use of self-supervised learning methods and advanced architectures could further improve the performance of world model pre-training.
Conclusion
The WPT framework presents a promising approach to efficient RL by effectively leveraging non-curated offline data. The combination of generalist world model pre-training, retrieval-based experience rehearsal, and execution guidance enables agents to achieve superior sample efficiency and fast task adaptation across a wide range of tasks. This research has the potential to significantly advance the field of RL and facilitate the development of more capable and adaptable autonomous systems.