- The paper presents a framework that enables LLM agents to dynamically decide when to plan by weighing planning benefits against computational and stability costs.
- It introduces a two-stage training process—supervised fine-tuning followed by reinforcement learning—that improves sample efficiency and reduces behavioral instability.
- Experimental results in synthetic and Minecraft-inspired environments show that intermediate planning frequencies yield superior outcomes compared to always-plan or never-plan strategies.
Dynamic Planning for LLM Agents: Learning When to Allocate Test-Time Compute
Introduction and Motivation
The paper addresses the challenge of efficient test-time compute allocation for LLM-based agents in sequential decision-making environments. While explicit reasoning and planning (e.g., via ReAct or chain-of-thought prompting) can improve agent performance, always planning at every step is computationally expensive and can degrade performance due to behavioral instability, especially in long-horizon tasks. Conversely, never planning limits the agent's ability to solve complex problems. The central contribution is a conceptual and algorithmic framework for dynamic planning, enabling LLM agents to learn when to plan, balancing the benefits of explicit reasoning against its computational and behavioral costs.
Conceptual Framework for Dynamic Planning
The authors formalize the planning decision as a cost-benefit analysis within a partially observable MDP. The agent's behavior is decomposed into three conceptual policies: a decision policy ϕθ (when to plan), a planning policy ψθ (how to plan), and an acting policy πθ (how to act given a plan). All are realized within a single, monolithic LLM, with the decision to plan made implicitly by the model's output format (i.e., whether it emits a <plan> token at the start of its response).
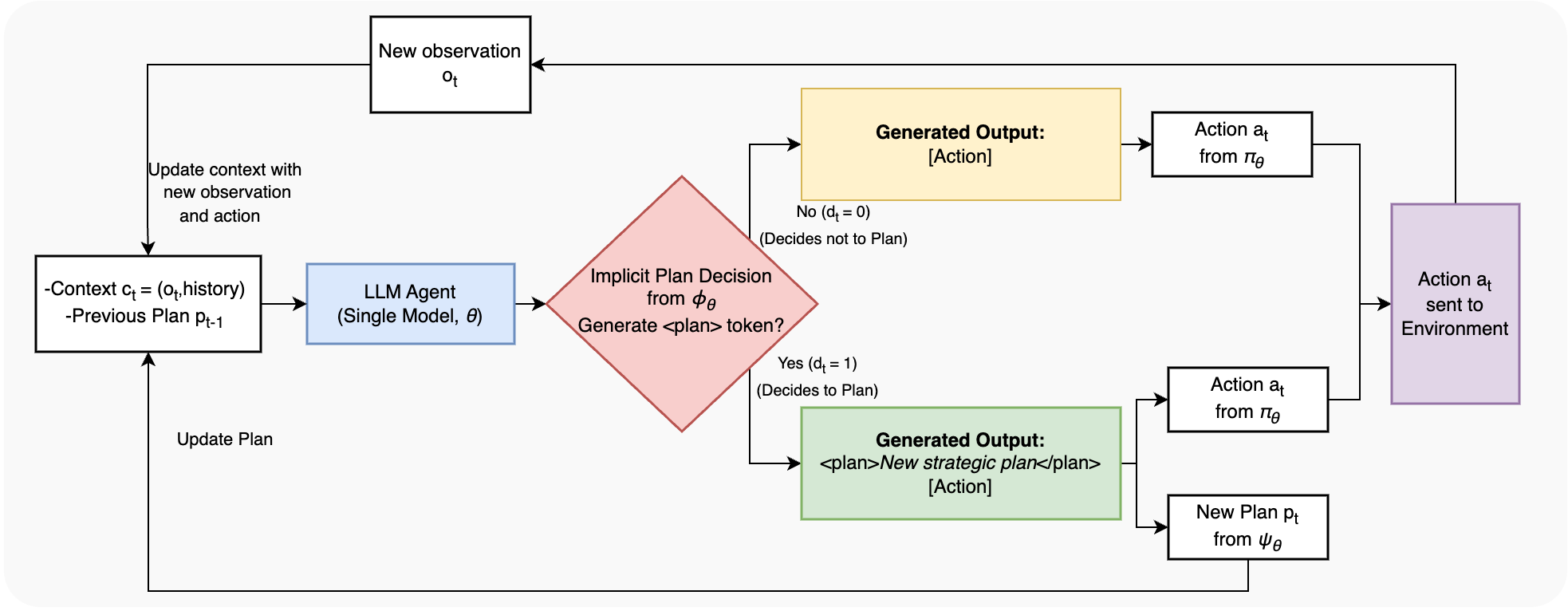
Figure 1: The dynamic planning agent architecture, where a single LLM implicitly realizes decision, planning, and acting policies via its output format.
The planning advantage Aplan(ct) is defined as the expected improvement in value from generating a new plan versus continuing with the current plan. The explicit cost of planning, Cplan, includes computational cost (token generation), latency, and instability (behavioral noise from excessive replanning). The agent is trained to plan only when the expected benefit outweighs these costs.
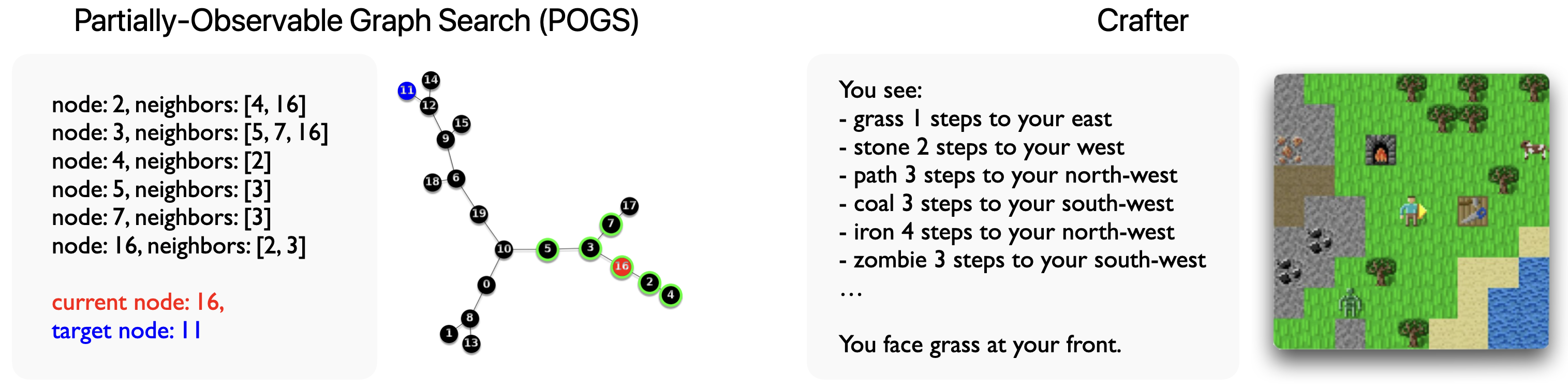
Experimental Environments
Two environments are used to evaluate the framework:
Training Methodology
The training pipeline consists of two stages:
- Supervised Fine-Tuning (SFT): The LLM is primed on synthetic data containing diverse planning behaviors, including explicit natural language plans at varying frequencies. This stage exposes the model to the structure and utility of planning.
- Reinforcement Learning (RL): The SFT-primed model is further fine-tuned via PPO to maximize task rewards, with an explicit penalty for planning cost (token generation). The RL objective encourages the agent to learn the optimal, context-dependent planning frequency.
Empirical Results
Zero-Shot Planning Frequency Analysis
Zero-shot experiments with Llama-3.3-70B-Instruct reveal a non-monotonic relationship between planning frequency and performance. Both in POGS and Crafter, intermediate planning frequencies ("Goldilocks" zone) outperform both always-plan (ReAct-style) and never-plan baselines. Excessive planning leads to increased backtracking and behavioral instability, while insufficient planning limits task progression.
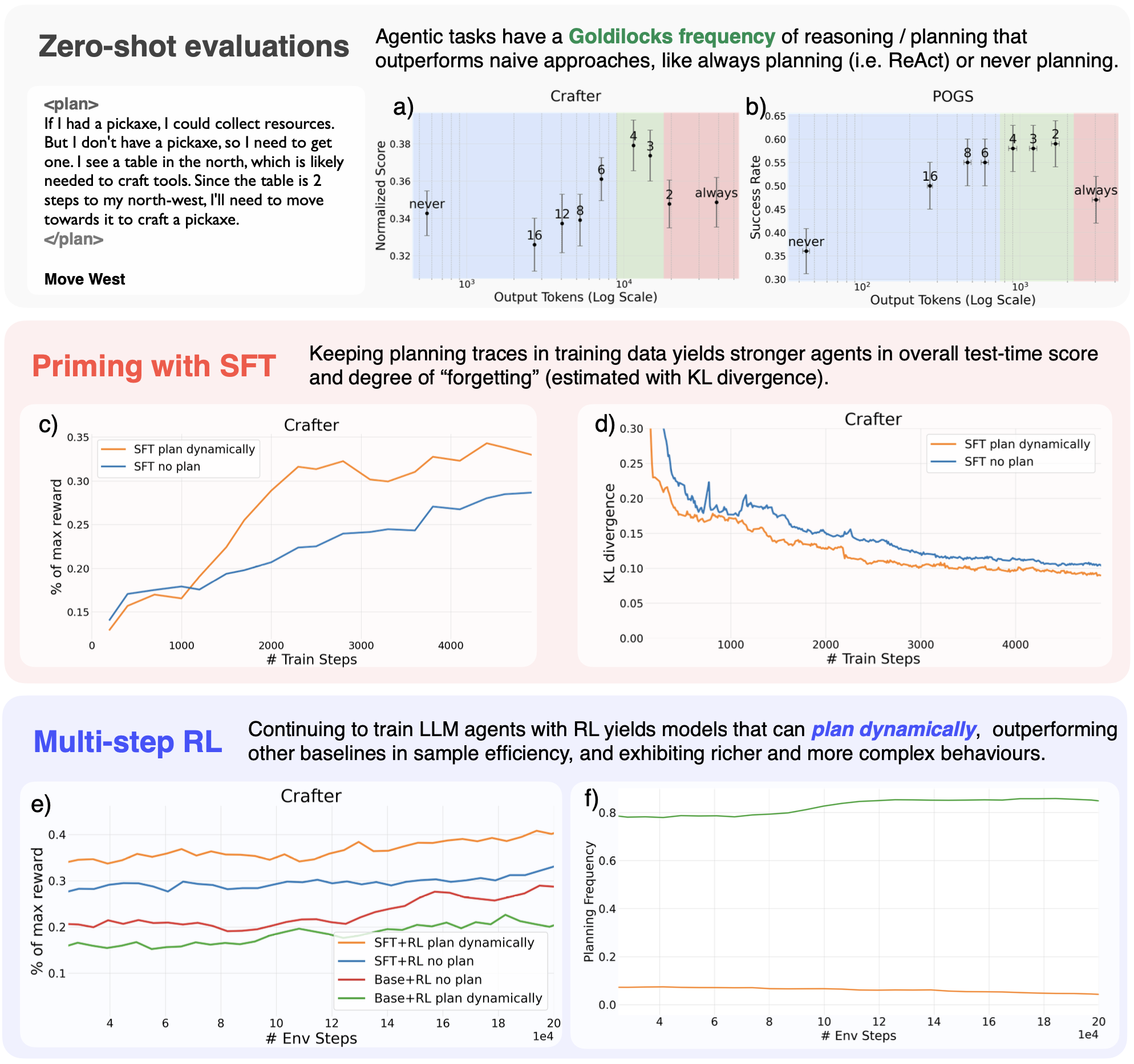
Figure 3: Dynamic planning strategies across environments and training stages, highlighting the optimal "Goldilocks" planning frequency and the superior sample efficiency of SFT+RL planning agents.
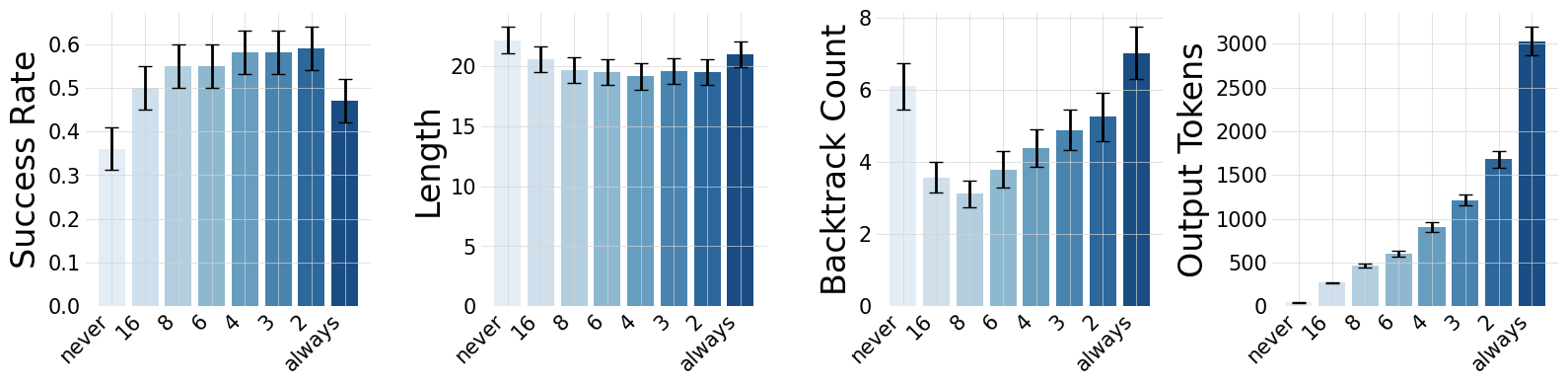
Figure 4: Planning frequency affects exploration in POGS; intermediate planning yields higher success and efficiency, while always-plan agents exhibit increased backtracking (Cnoise).
SFT Priming
SFT with explicit plans (dynamic planning) yields higher task progression and lower KL divergence from the base model compared to SFT on action-only data, despite identical action supervision. This suggests that explicit plan supervision provides semantic grounding and regularization, facilitating more effective imitation learning.
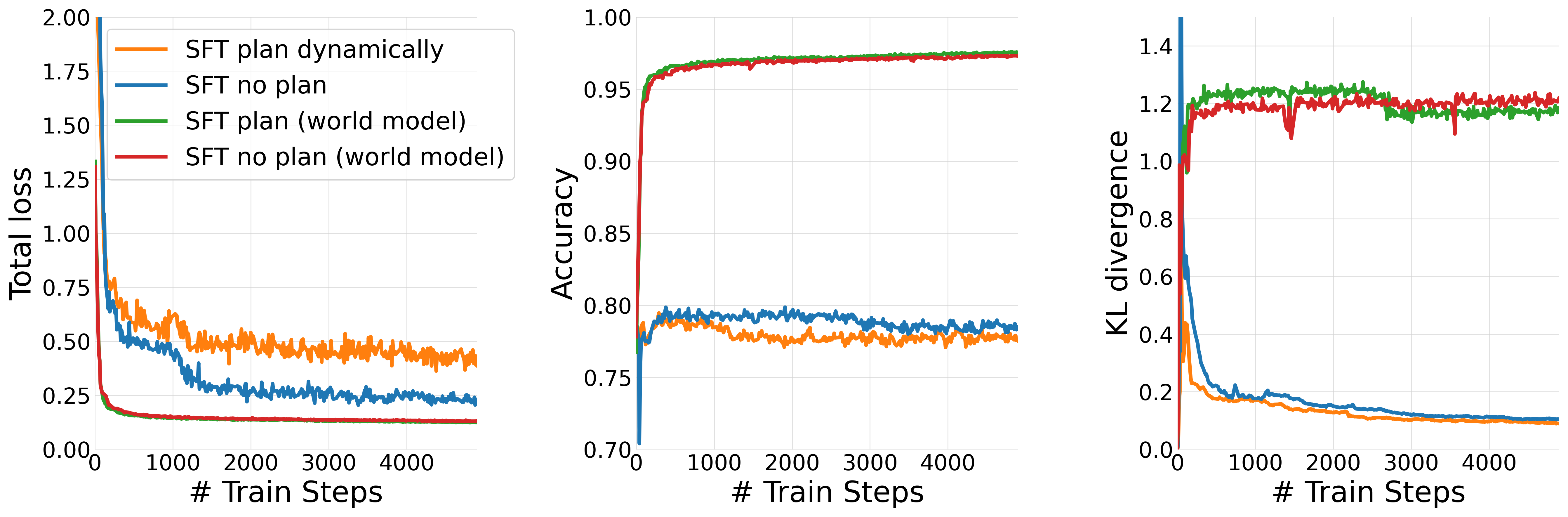
Figure 5: SFT training metrics show that models trained to plan dynamically have higher total loss (due to the harder modeling task) but lower KL divergence, indicating less disruptive fine-tuning.
RL Fine-Tuning
RL fine-tuning further amplifies the benefits of dynamic planning. SFT+RL plan dynamically agents are more sample efficient and achieve more complex objectives than non-planning baselines. These agents learn to plan at contextually appropriate times, execute multi-level plans, and replan adaptively in response to environmental changes.
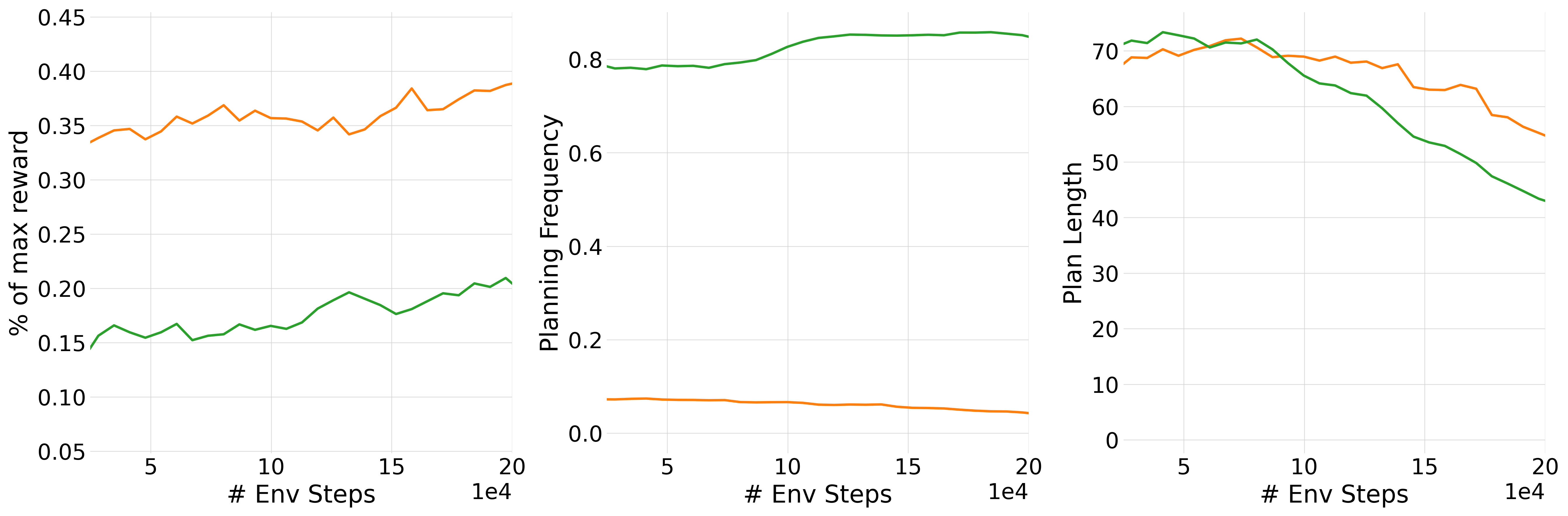
Figure 6: RL-trained agents become more efficient over time, reducing planning frequency and plan length while improving normalized score.
Human-Agent Collaboration
Post-RL, planning agents can be steered by human-written plans, achieving performance unattainable by autonomous agents. In Crafter, human collaboration enables the agent to complete the game by mining diamond, a feat not observed in any independent training run.

Figure 7: Human-agent collaboration in Crafter, where human guidance enables complex behaviors not seen in training.
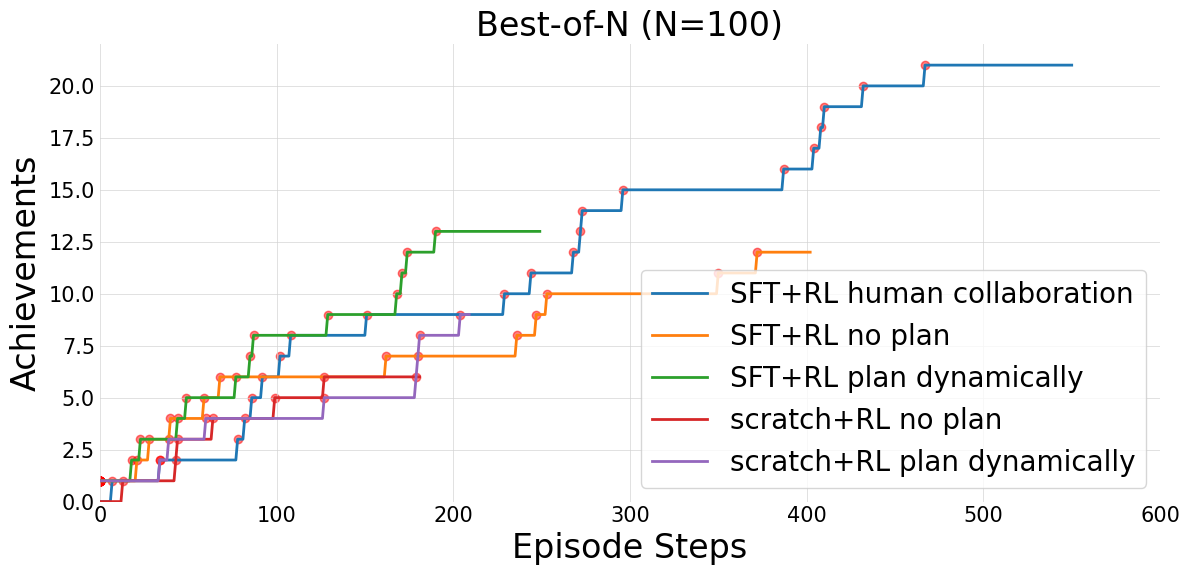
Figure 8: Best-of-N comparison on Crafter; human collaboration yields the strongest progression, followed by SFT+RL plan dynamically.
Qualitative Analysis and Failure Modes
The agent demonstrates adaptive behaviors such as interrupting current plans to address critical needs (e.g., replanning to acquire food when health is low) and chaining multi-stage tactical plans. However, failure cases persist, such as executing plans without verifying all preconditions (e.g., attempting to craft without access to required resources), indicating a gap between plan generation and robust execution.
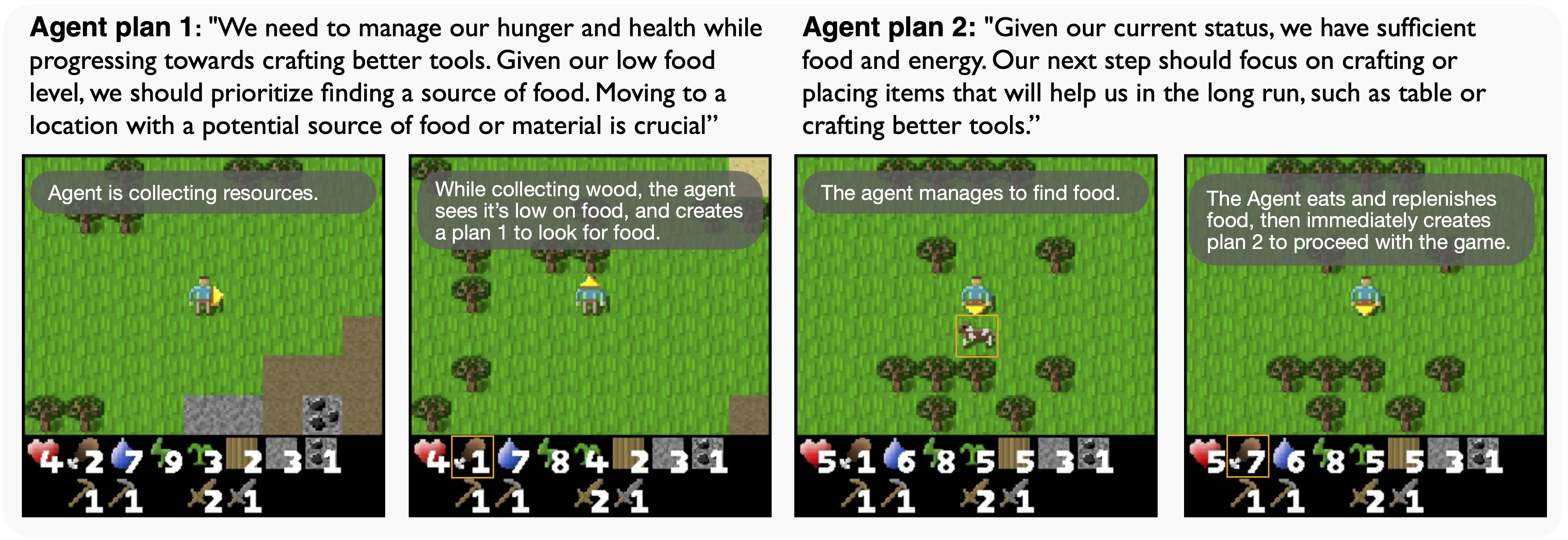
Figure 9: Autonomous replanning for survival, with the agent adaptively switching objectives in response to environmental changes.

Figure 10: Multi-stage tactical planning, with the agent chaining and adapting plans in response to threats.

Figure 11: Failure case where the agent's plan is correct in intent but fails in execution due to missing precondition checks.
Planning Cost Penalty Ablation
Ablation studies on planning cost penalties show that increasing the penalty reduces planning frequency and plan length, but normalized task performance remains largely unaffected after sufficient training. This suggests that, as agents become more proficient, much of the necessary reasoning becomes internalized, reducing reliance on explicit plan generation.
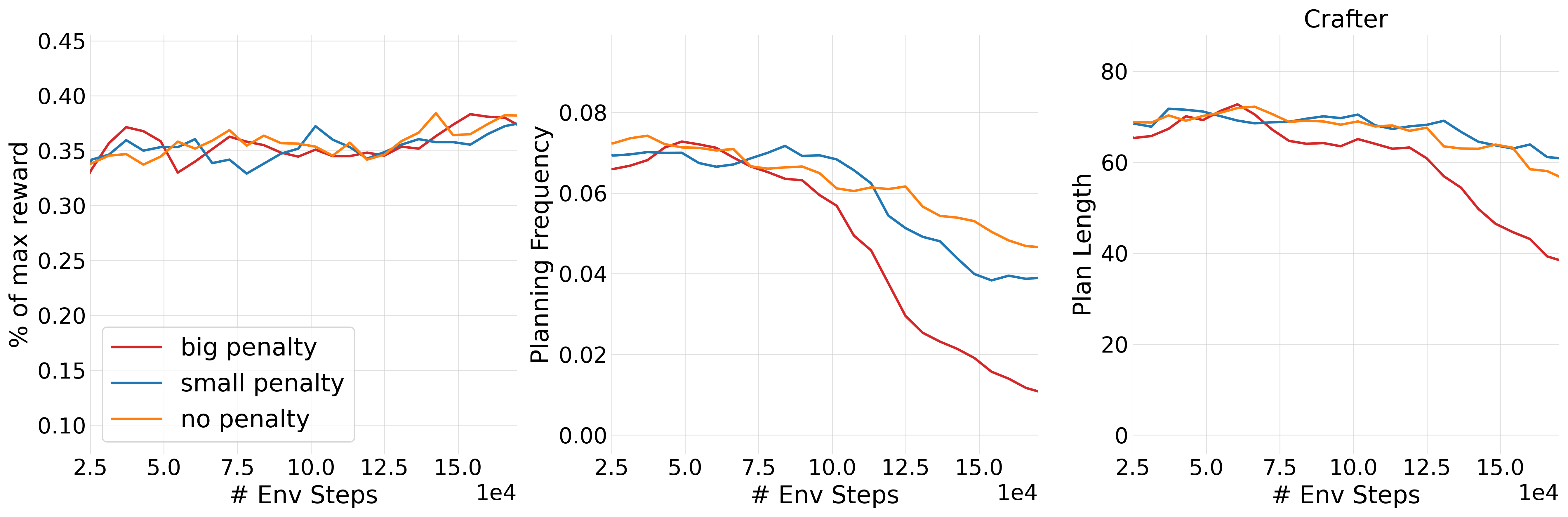
Figure 12: Training with different planning cost penalties; agents adapt by reducing planning frequency and plan length, but final scores are robust.
Implications and Future Directions
This work demonstrates that dynamic, learned allocation of test-time compute for planning is essential for efficient and effective LLM agents in sequential decision-making tasks. The findings challenge the prevailing use of always-plan (ReAct-style) strategies, showing that intermediate, context-dependent planning frequencies are superior. The two-stage SFT+RL methodology is critical for enabling this behavior, especially for models at moderate scale.
The ability to steer planning agents with human-written plans has significant implications for controllability and safety in agentic systems. However, persistent late-game bottlenecks and execution failures highlight the need for further advances in plan grounding, verification, and hierarchical skill acquisition.
Future research should investigate scaling these methods to larger models, more diverse environments, and more sophisticated compute allocation mechanisms. Integrating explicit plan verification, hierarchical planning, and richer forms of human-agent collaboration are promising directions.
Conclusion
The paper establishes that dynamic planning—learning when to allocate test-time compute for explicit reasoning—is critical for LLM agents in complex, sequential environments. Always-plan and never-plan strategies are both suboptimal; instead, agents must learn to plan at contextually appropriate times. The proposed SFT+RL pipeline enables this capability, yielding agents that are more sample efficient, more controllable, and better able to solve long-horizon tasks. These results have direct implications for the design of scalable, efficient, and safe agentic systems based on LLMs.