Elastic Attention: Test-time Adaptive Sparsity Ratios for Efficient Transformers
Abstract: The quadratic complexity of standard attention mechanisms poses a significant scalability bottleneck for LLMs in long-context scenarios. While hybrid attention strategies that combine sparse and full attention within a single model offer a viable solution, they typically employ static computation ratios (i.e., fixed proportions of sparse versus full attention) and fail to adapt to the varying sparsity sensitivities of downstream tasks during inference. To address this issue, we propose Elastic Attention, which allows the model to dynamically adjust its overall sparsity based on the input. This is achieved by integrating a lightweight Attention Router into the existing pretrained model, which dynamically assigns each attention head to different computation modes. Within only 12 hours of training on 8xA800 GPUs, our method enables models to achieve both strong performance and efficient inference. Experiments across three long-context benchmarks on widely-used LLMs demonstrate the superiority of our method.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What this paper is about (in simple terms)
Imagine reading a very long book. Sometimes you need to read every word carefully, and sometimes it’s fine to skim. LLMs work the same way: “attention” is how they read. Full attention (reading every word against every other word) is accurate but slow and expensive. Sparse attention (skimming most words, focusing on a few) is faster but can miss details.
This paper introduces Elastic Attention, a way for an LLM to decide, at test time, how much to “read carefully” and how much to “skim,” based on the input and the task. It adds a tiny “router” that acts like a traffic cop, telling different parts of the model when to use full attention and when to use sparse attention—so the model stays fast without losing important information.
What questions the researchers asked
- Can a model automatically choose how much to skim or read carefully for different tasks and inputs, without manual tuning?
- Can we make this work by adding only a small piece to a pretrained model, keeping the original model unchanged?
- Will this dynamic strategy be both fast and accurate on real long-context tasks (like long document Q&A, summarization, or reasoning)?
How the method works (explained with analogies)
Transformers and “attention heads”
- A Transformer model uses many small “attention heads.” Think of them as multiple tiny spotlights scanning a text. Each head looks for connections between words.
- Full Attention (FA): every word checks every other word—very thorough, very costly when the text is long.
- Sparse Attention (SA): each head focuses on fewer, most relevant words—much faster, but riskier if you miss important details.
What’s new: the Attention Router
- The Attention Router is a tiny add-on module (like a smart traffic cop) that:
- Looks at the current input.
- For each attention head, decides whether it should use FA (read carefully) or SA (skim).
- This lets the model adapt its overall “sparsity” (how much it skims) based on the task and input, on the fly.
- The base model’s weights stay frozen; only the tiny router is trained. That makes training faster and safer.
Two kinds of tasks the model sees
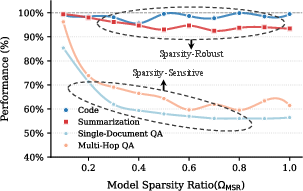
- Sparsity-robust tasks: don’t need very detailed reading (like some summarization). These can use more skimming (more SA).
- Sparsity-sensitive tasks: need precise details (like answering specific questions). These need more careful reading (more FA).
Training tricks (simple version)
- During training, the router practices making yes/no decisions (FA or SA for each head) using techniques that help it learn hard choices smoothly. You can think of it as “soft deciding” during practice and “hard deciding” during real use.
- The researchers also wrote optimized code so that heads using FA and heads using SA can run together efficiently in one pass.
What they found and why it matters
Here are the main takeaways from tests on several strong LLMs (like Qwen3-4B/8B and Llama-3.1-8B) and long-context benchmarks (LongBench, RULER, LongBench-V2):
- The model adapts its reading style to the task:
- For tasks like summarization, it uses more sparse attention (more skimming) to go faster.
- For detailed question answering or reasoning, it uses more full attention to stay accurate.
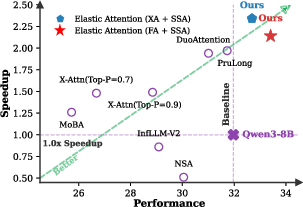
- Better speed–accuracy balance:
- Compared to other methods that fix the attention mix, Elastic Attention often scores higher or similar while being faster, especially on very long inputs.
- Strong performance on very long contexts:
- On tests that push the model to read extremely long inputs (up to hundreds of thousands of tokens), the adaptive approach stays accurate and efficient.
- Minimal overhead and quick training:
- The router is tiny (adds a small number of parameters per layer).
- They trained it in about 12 hours on 8 high-end GPUs, without changing the original model’s weights.
- Consistent head behavior:
- Some heads consistently prefer careful reading (full attention)—these behave like “retrieval heads” that fetch crucial facts.
- Others consistently prefer skimming (sparse attention), saving time.
Why this matters: It means we don’t have to pick one fixed setting for all tasks. The model can decide how to allocate its “attention budget” per input, making it both smarter and more efficient in real-world use.
How they tested it (simple summary of the approach)
- They integrated the Attention Router into existing models without altering the original model’s parameters.
- They trained only the router on a mix of tasks that need detailed reading (like multi-hop question answering) and tasks that are okay with skimming (like summarization and code completion).
- They evaluated on:
- Real-world long-text tasks (LongBench).
- Length stress tests (RULER), which check how well the model handles very long inputs.
- Long reasoning tasks (LongBench-V2).
- They compared against several strong baselines that also try to make attention more efficient.
What this could change in the future
- More flexible long-text AI: Models that can read long documents, books, or logs more efficiently, deciding when to skim and when to focus—just like humans do.
- Lower cost and energy use: Faster processing means cheaper and greener AI, especially for long contexts.
- Easier deployment: Because the base model stays frozen and only a tiny module is added, companies can plug this into existing systems with minimal hassle.
- Better performance on mixed workloads: In the real world, tasks vary a lot—this approach helps the same model handle all of them more reliably.
In short, Elastic Attention gives Transformers a smart, flexible way to manage their attention, making them faster when possible and careful when needed.
Knowledge Gaps
Unresolved Gaps, Limitations, and Open Questions
Below is a concise list of concrete gaps and open problems left by the paper that future work could address:
- Test-time adaptation scope: The method adapts sparsity “during the prefill stage,” but it is unclear whether routing adapts during decoding (streaming generation). Evaluate token-by-token or step-wise adaptation in the decode phase and its effect on latency/quality.
- Task-regime assumption: The binary categorization into sparsity-robust vs. sparsity-sensitive tasks may be too coarse. Study inputs with mixed or position-dependent sensitivity and whether finer-grained or continuous regimes improve outcomes.
- Router input construction: The router pools Key states over a truncated portion of the sequence, but the pooling window, truncation policy, and layer selection are under-specified. Systematically ablate pooling strategies (window size/position), using Q vs. K vs. V, and single-layer vs. multi-layer representations.
- Unsupervised task identification: Training uses task-dependent target sparsities t (e.g., t_rob=1.0, t_sen=0.7) derived from task labels. Develop methods to infer or adapt targets without task labels (e.g., uncertainty-aware penalties, meta-learning, or reinforcement objectives).
- Objective–metric mismatch: The training constraint optimizes model sparsity ratio (MSR), while compute/memory savings align better with effective sparsity ratio (ESR). Investigate ESR-based or joint MSR/ESR regularization and compare compute-quality trade-offs.
- Constraint handling and stability: Lagrange-multiplier optimization lacks convergence/stability analysis and constraint-satisfaction reporting. Study collapse modes (all-FA or all-SA), schedule sensitivity, and provide diagnostics for constraint violations.
- Generalization to OOD tasks/domains/languages: Training data (0.74B tokens, specific tasks) may not cover diverse domains or languages. Evaluate robustness under domain shift, multilingual settings, and novel long-context tasks.
- End-to-end latency and throughput: Speed comparisons focus on a fused kernel vs. a Torch sequential baseline. Provide end-to-end latency/throughput under realistic batching, including router overhead, and compare against state-of-the-art kernels (FlashAttention-3, xFormers, TensorRT-LLM, vLLM).
- Memory and KV-cache footprint: The paper does not quantify VRAM/KV-cache savings or overhead under different sparsity settings and sequence lengths. Measure memory usage vs. baselines across batch sizes and lengths (including 256K+ contexts).
- Multi-GPU/distributed inference: Results target single-GPU deployment. Assess scalability with tensor/pipeline parallelism, per-head heterogeneous modes under multi-GPU, and communication/launch overhead.
- Sparse pattern coverage: Only SSA and XAttention are evaluated. Test additional patterns (block-sparse, Longformer, Ring/Sliding variants, attention with learned blocks) and quantify how the router interacts with pattern choice.
- Binary per-head routing: The router makes a discrete FA/SA choice per head. Explore multi-level or continuous per-head sparsity (e.g., variable SA thresholds/block sizes) and investigate whether routing softens or schedules sparsity over time.
- Cross-layer coordination: Routing decisions appear independent across layers. Examine coordinated routing (e.g., layer-wise budgets, head grouping, or shared constraints) and its impact on stability and efficiency.
- Interpretability and calibration: No diagnostics for when routing is uncertain or likely wrong. Develop confidence measures for routing, fallback-to-FA policies under uncertainty, and tools to debug head-level decisions.
- Handling regressions on sparsity-robust tasks: The method underperforms some baselines on summarization/code, partly due to higher sparsity. Devise mechanisms to automatically reduce sparsity for such inputs without task labels, and quantify benefits vs. cost.
- Failure-case analysis: FA–XA underperforms on Qwen3-8B without a root-cause study. Investigate architecture-specific interactions (e.g., GQA/MQA configs, head counts, rotary settings) and hyperparameter sensitivities.
- Scaling to larger models: Only 4B/8B models are studied. Test feasibility and benefits for ≥30B/70B models, MQA-heavy architectures, and different head dimensions; report router parameter/latency scaling and kernel portability.
- Decoding-time cache policies: Interactions with attention sinks, cache eviction, and sliding windows are not analyzed. Evaluate routing under long dialogues and streaming with cache management strategies.
- ESR estimation fidelity: ESR assumes fixed SA pruning ratios, which may be inaccurate for adaptive patterns (e.g., sink-based or content-based SA). Implement accurate runtime ESR measurement and relate it to actual FLOPs/memory savings.
- Router architecture exploration: Ablations focus on MLP width. Compare with deeper routers, attention-based routers, cross-layer feature aggregation, and normalization/regularization choices; analyze accuracy–overhead trade-offs.
- Initialization and priors: The router is trained from scratch; leveraging prior retrieval-head knowledge or curriculum learning might stabilize training and improve final routing. Evaluate such initializations.
- Energy efficiency: Report tokens/sec per Watt and total energy vs. baselines to verify that sparsity translates into real energy savings, not just kernel-level speedups.
- Broader evaluation coverage: Extend beyond English and the selected benchmarks to code-intensive, multi-hop legal/biomedical, and multimodal long-context tasks; assess robustness across metrics (faithfulness, calibration, hallucination).
- Kernel availability and portability: Clarify fused-kernel support across GPU generations (A100/H100/consumer), frameworks, and inference stacks. Provide reproducible builds and measure portability overheads.
- Constraint tightness and target gaps: The non-tight constraints lead to attained sparsity deviating from targets. Quantify the gap and study adaptive target tightening or learned targets to match performance/computation budgets.
- Feature choice for routing: The router uses only K states. Compare using joint Q/K/V, early attention maps, or lightweight statistics (e.g., entropy, gradient proxies) vs. their overhead to improve routing quality.
Practical Applications
Overview
The paper introduces Elastic Attention, a lightweight, trainable “Attention Router” that dynamically assigns each attention head to full attention (FA) or sparse attention (SA) at test time. This enables LLMs to adapt their effective sparsity based on the input/task, improving throughput and reducing memory while preserving accuracy—especially for long-context workloads. It requires no backbone weight changes, adds minimal per-layer parameters, and comes with a fused kernel to efficiently execute mixed-mode heads in a single pass. The method is validated on multiple long-context benchmarks and LLMs (Qwen3 series and Llama-3.1-8B-Instruct), demonstrating consistent performance–efficiency gains.
Below are actionable applications derived from these findings, organized by time horizon. Each item includes target sectors, potential tools/workflows/products, and key assumptions/dependencies that affect feasibility.
Immediate Applications
The following applications can be piloted or deployed now with modest engineering effort, leveraging the router module, mixed FA/SA execution, and the fused kernel as described.
- LLM inference acceleration for long-context APIs (Software/Cloud)
- What: Reduce prefill time and memory for requests with long prompts (e.g., 64K–256K tokens) by dynamically adjusting sparsity per input during prefill.
- Tools/Products/Workflows:
- Runtime plugin for vLLM/TensorRT-LLM/Transformers to enable head-wise routing and mixed-mode kernels.
- Request-time policies (e.g., latency/cost targets) mapped to target sparsity bounds (Ω_MSR/Ω_ESR).
- Observability hooks reporting effective sparsity and latency.
- Assumptions/Dependencies:
- Availability of SA kernels (e.g., SSA, XA) and compatibility with GQA-based heads.
- Integration of the fused kernel into the serving stack; GPU backends (CUDA/Triton) mature enough for mixed-mode kernels.
- Router training on representative workloads to generalize across customer traffic.
- Cost-aware autoscaling and SLA tiers for LLM services (Software/Cloud/Finance)
- What: Offer “standard” vs “premium” tiers where the router enforces higher sparsity for cost-sensitive traffic and lower sparsity for accuracy-critical traffic.
- Tools/Products/Workflows:
- Per-request sparsity controllers that set non-tight bounds in the router objective (paper’s Lagrangian approach).
- Billing/reporting based on Ω_ESR (effective attended tokens), not just raw tokens.
- Assumptions/Dependencies:
- Product alignment around “attended tokens” metrics.
- Confidence that task-driven routing maintains accuracy within SLA bands.
- Enterprise RAG: dynamic compute allocation for summarization vs QA (Enterprise Software/Knowledge Management)
- What: In document retrieval and analytics, route more heads to FA for evidence-intensive QA; use higher sparsity for summarization or topic overviews.
- Tools/Products/Workflows:
- Integration with LangChain/LlamaIndex pipelines; router receives task hints (QA vs summarization) or infers them from the prompt.
- Benchmarked profiles for domain corpora to calibrate target sparsity.
- Assumptions/Dependencies:
- Correct categorization of prompts into sparsity-sensitive vs -robust regimes.
- Domain validation to ensure no loss of critical recall in compliance scenarios.
- Legal and finance document processing at scale (LegalTech/FinTech)
- What: Faster processing of long regulatory filings, contracts, or risk reports—using SA for summaries and FA for clause/evidence extraction passages.
- Tools/Products/Workflows:
- Batch processing services that dynamically tune Ω_MSR by document section (e.g., pre-identified “evidence-rich” sections).
- Assumptions/Dependencies:
- Human-in-the-loop verification for high-stakes tasks.
- Router retraining on domain data improves robustness to specialized terminology.
- IDE-integrated code assistants on large repositories (Software Engineering)
- What: Reduce latency for repo-scale context windows by routing heads to SA during general navigation/autocomplete, and to FA for precise refactor or bug localization queries.
- Tools/Products/Workflows:
- Editor plugins with router-aware modes; CI pipelines that enforce stricter (lower sparsity) modes for safety-critical reviews.
- Assumptions/Dependencies:
- Adequate long-context support in the underlying code LLM and SA kernel stability in IDE environments.
- Contact center and media analytics: real-time transcript summarization with precise follow-up QA (Customer Support/Media)
- What: Use streaming SA for ongoing call/meeting summarization; selectively route to FA for specific compliance checks or action-item extraction.
- Tools/Products/Workflows:
- Streaming pipelines that switch target sparsity on segment boundaries; monitoring of Ω_ESR vs real-time latency budgets.
- Assumptions/Dependencies:
- Stable streaming SA kernels; small overhead from router does not break real-time constraints.
- Education platforms: grading/faculty assistance for long essays vs fact-based checks (Education)
- What: Efficient grading summaries and feedback (high sparsity), then low-sparsity checks for plagiarism/evidence-backed claims.
- Tools/Products/Workflows:
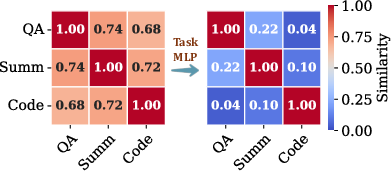
- LMS plugins that route tasks into sparse/precise modes automatically via the router’s task MLP.
- Assumptions/Dependencies:
- Clear policies around which tasks can tolerate sparsity; fairness and consistency audits for grading.
- Healthcare informatics (Healthcare)
- What: Summarize long EHR narratives efficiently; allocate more FA to tasks requiring precise extraction (e.g., medication changes, adverse events).
- Tools/Products/Workflows:
- On-prem inference nodes with router-integrated LLMs; clinical task tags mapped to sparseness targets.
- Assumptions/Dependencies:
- Rigorous clinical validation; privacy-preserving deployment; clear fallback to FA for ambiguous cases.
- On-device or desktop long-doc assistants (Consumer/Daily Life)
- What: Read and summarize large PDFs or long email threads locally with reduced memory/latency; use FA only for user queries demanding exact citations.
- Tools/Products/Workflows:
- Lightweight router checkpoints for 4B–8B models; fused kernels compiled for consumer GPUs.
- Assumptions/Dependencies:
- GPU/CPU backends that support the fused kernel; acceptable accuracy for consumer tasks with higher sparsity.
Long-Term Applications
These applications are promising but require further research, scaling, ecosystem support, or standardization before broad deployment.
- Hardware/compiler co-design for mixed-mode attention (Semiconductors/Systems Software)
- What: Native GPU/ASIC/Triton support for head-wise heterogeneous FA/SA with optimal scheduling and memory layouts.
- Tools/Products/Workflows:
- Vendor-provided kernels; compiler passes that fuse routing and attention efficiently; profiling tools exposing Ω_ESR at kernel granularity.
- Assumptions/Dependencies:
- Broad adoption by major inference frameworks; alignment with emerging block-sparse formats.
- Pretraining-time adaptive attention and per-token routing (AI Research)
- What: Train LLMs with routers from scratch, enabling finer-grained (per-token/per-layer) decisions beyond prefill-stage routing.
- Tools/Products/Workflows:
- Curriculum schedules for Gumbel-Softmax/STE; sparsity-aware pretraining loss with Lagrangian constraints; large-scale datasets with mixed task regimes.
- Assumptions/Dependencies:
- Stability of training with discrete routing; demonstrable gains across diverse tasks/languages.
- Multimodal and time-series transformers (Vision/Audio/Healthcare/Robotics)
- What: Extend routers to cross-modal attention (e.g., video-text, audio-text) and long time-series, conserving compute when modality cues are coarse but switching to FA for fine cross-modal grounding.
- Tools/Products/Workflows:
- Multimodal kernels that support mixed attention patterns; dataset-specific sparsity targets for segments (e.g., keyframes).
- Assumptions/Dependencies:
- Robustness of routing with modality-specific distributions; careful evaluation of modality-bridging accuracy.
- Ultra-long-context, fully sparse deployments at scale (Edge/Enterprise)
- What: Push XA–SSA-style all-sparse regimes to 8B+ models with reliable accuracy for 256K–1M token contexts (e.g., full repo or corpus analysis).
- Tools/Products/Workflows:
- Advanced SA strategies (block-sparse, learned patterns) and router policies that retain critical retrieval heads only where needed.
- Assumptions/Dependencies:
- Further gains in SA quality; better head specialization and interpretability to avoid recall loss.
- Energy- and carbon-aware scheduling and procurement policies (Policy/Energy/Cloud)
- What: Use Ω_ESR as a standardized metric for attended-token energy budgets; procurement guidelines that prefer adaptive-sparsity-capable models.
- Tools/Products/Workflows:
- Reporting pipelines from model servers to sustainability dashboards; policy templates for public-sector AI solicitations.
- Assumptions/Dependencies:
- Agreement on measurement standards (Ω_ESR, wall-clock savings, Joules/token); verification frameworks for third-party audits.
- AutoML for task categorization and target selection (MLOps/AutoML)
- What: Automatically infer task regimes (sparsity-robust vs -sensitive) and set per-task target sparsity bounds to meet quality/cost constraints.
- Tools/Products/Workflows:
- Meta-controllers that tune Lagrange multipliers and targets online; A/B frameworks to validate accuracy vs cost.
- Assumptions/Dependencies:
- Reliable online metrics for quality; guardrails to prevent under-allocation of FA on rare but critical inputs.
- Interpretability and safety auditing via head routing analytics (Governance/Safety)
- What: Use routing patterns as signals for which layers/heads are critical for retrieval; detect when the model downgrades to SA in high-risk contexts.
- Tools/Products/Workflows:
- Dashboards that visualize per-task head routing frequencies; alerts when routing deviates from validated profiles.
- Assumptions/Dependencies:
- Stable mapping between head roles and functionality across model updates; agreement on risk thresholds for forced FA.
- New billing and metering models for LLM APIs (Cloud/Finance)
- What: Charge by effective attention (Ω_ESR) rather than raw context length; offer discounts for highly sparse workloads.
- Tools/Products/Workflows:
- Metering that logs attended keys/values per request; customer-facing reports demonstrating cost–accuracy trade-offs.
- Assumptions/Dependencies:
- Customer acceptance; regulatory clarity on “differential quality” tiers; robust anti-gaming mechanisms.
- Robotics and real-time planning with long episodic memory (Robotics)
- What: Maintain long histories of sensor/action logs sparsely; temporarily switch to FA for precise planning or failure analysis windows.
- Tools/Products/Workflows:
- Router-aware policies integrated with real-time schedulers on edge GPUs; safety fallback to FA on anomalies.
- Assumptions/Dependencies:
- Deterministic timing guarantees with router overhead; validation on real-time constraints.
- Domain- and language-generalization studies (Academia)
- What: Evaluate if the two-regime assumption holds across languages, code, math, and specialized domains; identify datasets where routing must be more granular.
- Tools/Products/Workflows:
- Benchmarks that label task-level sparsity sensitivity; ablation suites measuring Ω_MSR/Ω_ESR vs accuracy.
- Assumptions/Dependencies:
- Availability of diverse, high-quality long-context datasets; consistent metrics for cross-domain comparisons.
Notes across applications:
- The method assumes modern LLMs with GQA-style attention and access to K/V states for routing.
- Router training requires representative data and target sparsity ranges (non-tight constraints); mis-specification can impact quality.
- Mixed-mode fused kernels are key for practical speedups; ecosystem support (CUDA/Triton/ROCm) may vary.
- For regulated sectors (healthcare, finance, legal), rigorous validation and conservative fallback to FA are essential.
- Reported gains were shown on Qwen3 and Llama-3.1-8B; results may vary on other backbones and languages without retraining.
Glossary
- Annealing: A schedule that gradually adjusts a temperature parameter to sharpen distributions during training. "we adopt a continuous relaxation scheme based on the Gumbel--Softmax~\citep{jang2016categorical} with annealing"
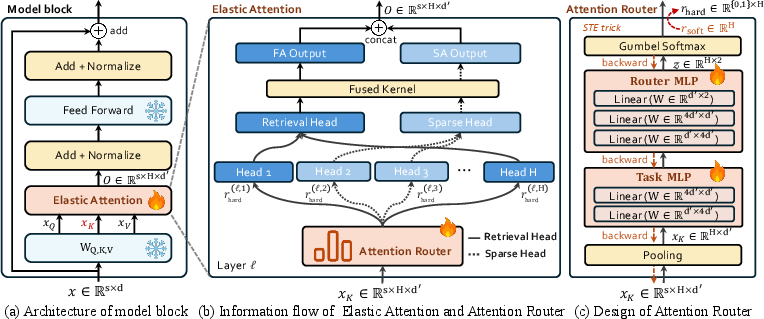
- Attention Router: A lightweight module that assigns each attention head to full or sparse computation based on input features. "The core of our approach is a lightweight Attention Router module integrated into existing transformer architectures."
- Block-sparse: An attention pattern where computations are restricted to selected blocks to reduce cost. "block-sparse~\citep{guo2024blocksparse} SA patterns."
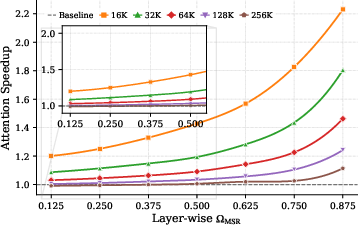
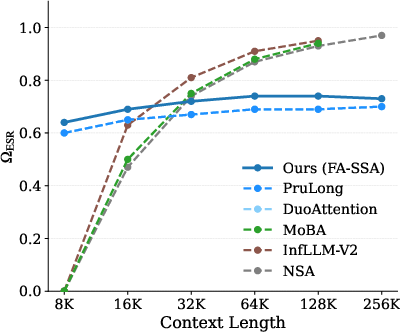
- Effective Sparsity Ratio (Ω_ESR): A measure of how many tokens are effectively pruned, combining head-level sparsity and per-head pruning patterns. "We report $\Omega_{\mathrm{ESR}$, as it provides a fair comparison of the effective proportion of attended tokens across different approaches."
- Full attention (FA): The standard attention mechanism that computes attention over all token pairs with quadratic complexity. "standard full attention~(FA) mechanisms~\citep{vaswani2017attention}"
- Fused attention kernel: A single kernel implementation that computes different head types together for efficiency. "we implement a fused attention kernel that jointly computes retrieval heads and sparse heads ``simultaneously''."
- Grouped Query Attention (GQA): An attention variant where multiple query heads share a set of key–value heads to reduce memory/computation. "Here we adopt grouped query attention (GQA)~\citep{ainslie2023gqa} definition instead of multi-head attention (MHA), as GQA is widely used in modern LLM architectures."
- Gumbel–Softmax: A continuous relaxation technique that enables differentiable sampling from categorical distributions. "we adopt a continuous relaxation scheme based on the Gumbel--Softmax~\citep{jang2016categorical}"
- Head-wise routing: Deciding per attention head whether to use full or sparse attention. "perform head-wise routing, dynamically assigning each attention head to either FA or SA computation mode"
- Hybrid heads: A design that mixes retrieval (full) and sparse heads in the same model to trade off cost and performance. "recent methods adopt a hybrid heads design that mixes retrieval and sparse heads within the same model"
- Lagrange multipliers: Trainable coefficients used to enforce sparsity constraints within a constrained optimization framework. "task-specific trainable Lagrange multipliers optimized via gradient ascent"
- Length extrapolation: The ability of a model to generalize to context lengths longer than seen during training. "aiming to examine model length extrapolation performance across different context length regimes."
- Mixture-of-Experts (MoE): An architecture with a gating mechanism that routes inputs to different expert modules. "operates in a manner analogous to a Mixture-of-Experts (MoE)~\citep{shazeer2017outrageously} gating mechanism"
- Model Sparsity Ratio (Ω_MSR): The fraction of attention heads operating in sparse mode within the model. "We use the $\Omega_{\mathrm{MSR}$ metric to calculate the predicted sparsity during training"
- Prefill stage: The initial phase of inference where key–value caches are computed before token-by-token decoding. "automatically adjust its overall sparsity during the prefill stage"
- Retrieval heads: Attention heads specialized for selecting relevant tokens from long contexts, typically using full attention. "Retrieval heads are a class of attention heads specialized in capturing contextually relevant tokens from long sequences"
- Sparse attention (SA): An attention mechanism that computes over a subset of tokens to reduce computational cost. "Sparse attention~(SA) mechanisms~\citep{child2019generating,zaheer2020big} represent an effective strategy for mitigating this limitation"
- Sparse heads: Attention heads that use sparse attention to lower computation by attending to fewer tokens. "Compared to the retrieval heads, sparse heads reduce computational cost by leveraging SA mode"
- Sparsity-robust tasks: Tasks whose performance remains stable over a wide range of sparsity levels. "sparsity-robust tasks (e.g., summarization)"
- Sparsity-sensitive tasks: Tasks that degrade significantly when sparsity increases beyond a threshold. "sparsity-sensitive tasks (e.g., question answering)"
- Straight-through estimator (STE): A gradient approximation technique that enables backpropagation through discrete decisions. "we employ a straight-through estimator (STE)~\citep{bengio2013estimating} trick for gradient propagation."
- Streaming Sparse Attention (SSA): A sparse attention pattern tailored for streaming or long sequences with efficient memory usage. "Streaming Sparse Attention (SSA)~\citep{streamingllm}"
- XAttention (XA): A sparse attention mechanism that selects tokens based on a thresholded criterion. "XAttention (XA)~\citep{xattention}"
Collections
Sign up for free to add this paper to one or more collections.