- The paper introduces a novel speculative context sparsity framework that leverages a distilled LM for global KV token retrieval, reducing retrieval head parameters by over 90%.
- The paper uses an asynchronous prefetch mechanism and elastic loading strategy to cut KV cache transfers by up to 90% and achieve a 24.89× speedup in cloud deployments.
- The paper employs adaptive memory management to dynamically optimize GPU utilization and maintain near full-attention accuracy on LongBench and LongWriter benchmarks.
Speculative Context Sparsity for Efficient Long-context Reasoning in LLMs
Introduction and Motivation
Long-context reasoning in LLMs exacerbates the computational and memory burdens due to the quadratic cost of self-attention over extended Key-Value (KV) caches. Although test-time scaling in autoregressive generation enhances LLM performance, the practical deployment of long-context agents is constrained by the exponential growth in KV cache memory and associated retrieval latency. Existing KV optimization frameworks, while effective in static long-context input scenarios, exhibit up to 60% synchronization overhead and >80% performance degradation with small increases in task length during dynamic long-context reasoning, compounded by complex layer-wise retrievals and non-adaptive offloading policies.
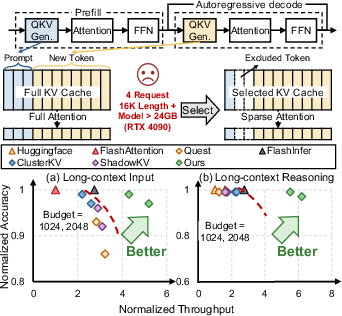
Figure 1: (a)(b) Pareto frontiers on KV cache selection in long-context input and reasoning scenarios.
Algorithmic Paradigm: Leveraging Distilled LM for Retrieval
The central insight in "SpeContext: Enabling Efficient Long-context Reasoning with Speculative Context Sparsity in LLMs" (2512.00722) is the tight homology between the information focus of a distilled LLM (DLM) and its original teacher LLM. By conceptualizing both KV retrieval and knowledge distillation as information alignment problems, the authors propose using a DLM as a predictive retrieval algorithm for important tokens, sidestepping computationally expensive layer-wise retrieval and preprocessing. Mutual information and data processing inequality analyses substantiate that a well-trained DLM preserves near-equivalent informational focus on contextually relevant tokens, satisfying the alignment required for high-fidelity retrieval.
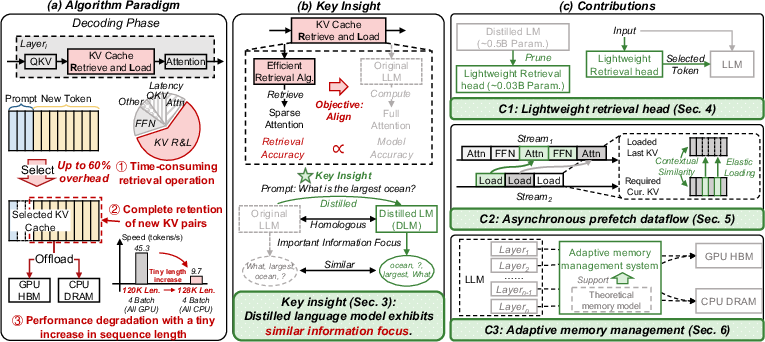
Figure 2: Overview of SpeContext: algorithmic and system-level contributions, and highlighting the DLM’s focus similarity.
The design eliminates granular KV selection per layer, instead performing a global, head-level selection of critical tokens using DLM's attention weights. Experimental results indicate >90% parameter reduction in the lightweight retrieval head and comparable retrieval accuracy.
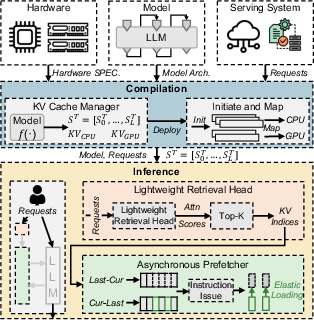
Figure 3: Architecture of SpeContext, demonstrating how requests are processed using an adaptive memory management system and asynchronous prefetcher.
System Design: Asynchronous Prefetch and Elastic Loading
SpeContext imposes strong decoupling of computation and memory access, leveraging an asynchronous prefetch KV dataflow enabled by the predictive capabilities of the DLM-based retrieval head. This architectural shift allows KV cache retrieval and loading to occur in parallel with LLM inference, eliminating the sequential dependency that dominates latency in previous designs.
To further minimize data transfer, the system exploits the observed >80% overlap rate in selected tokens between adjacent generations, implementing an elastic loading strategy that updates only the delta in selected KV positions. This method achieves up to 90% reduction in KV cache transfers, leading to dramatic speedups in both cloud and edge deployments.
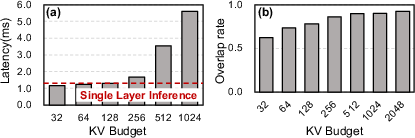
Figure 4: (a) Prefetch latency as a function of KV budget; (b) overlap rate between adjacent generations with varying KV budgets, showing high similarity.
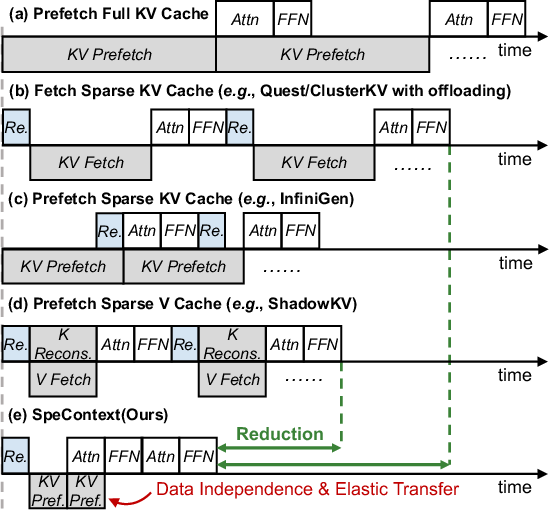
Figure 5: Elastic loading achieves lower KV transfer, allowing SpeContext to outperform prior methods in total throughput.
Adaptive Memory Management
Sequence length in reasoning tasks is dynamic and unpredictable, challenging preconfigured offloading strategies. SpeContext introduces a compilation-level adaptive memory management system based on a theoretical model of LLM, hardware, and workload parameters. By precomputing sequence length thresholds that dictate progressive offloading of KV cache from GPU to CPU as context grows, the system preserves maximal GPU utilization for as long as possible before offloading becomes necessary.
This approach avoids drastic throughput collapses when transitioning between memory tiers and adapts to inference demands on both resource-constrained edge GPUs and high-throughput cloud servers.
Empirical Results
SpeContext enters the accuracy-throughput Pareto frontier in both long-context input and reasoning benchmarks. On LongBench with Llama3.1-8B, SpeContext attains near full-attention accuracy even with modest (1024–2048) KV budgets.
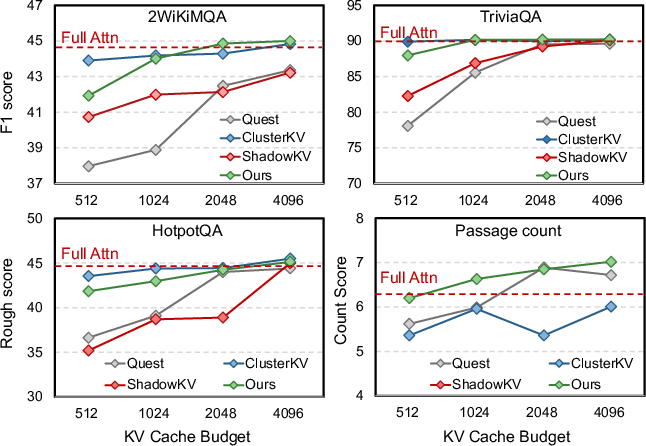
Figure 6: SpeContext maintains high accuracy in LongBench tasks across KV budgets.
On LongWriter, SpeContext’s average scores are essentially indistinguishable from full attention and competitive sparse attention baselines.
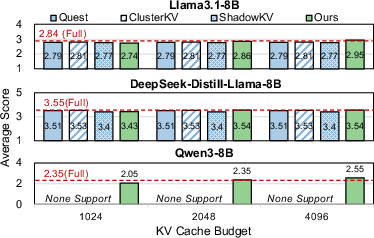
Figure 7: LongWriter benchmark scores validate minimal accuracy loss for SpeContext.
For throughput, SpeContext delivers up to 24.89× speedup over Huggingface full attention in multirequest cloud environments and 10.06× over eager baseline in edge settings, with only ~60MB retrieval head memory overhead and no retraining for new context lengths. Ablation studies identify the primary contributions: lightweight retrieval head (parameter reduction), asynchronous dataflow with elastic loading (KV transfer minimization), and adaptive memory management (robust GPU utilization).
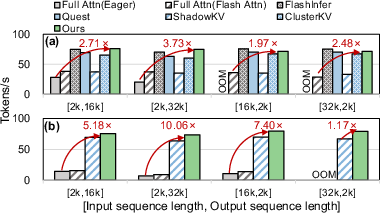
Figure 8: End-to-end throughput for cloud (a) and edge (b) deployments; SpeContext enables substantial speedups.
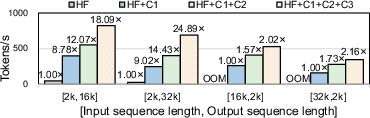
Figure 9: Ablation study quantifies the individual and combined effect of SpeContext’s innovations.
Implications and Future Directions
The speculative context sparsity paradigm reframes information retrieval in LLM inference as an alignment task that is tractable to lightweight, off-model prediction via DLMs. Practically, this yields dramatic improvements in agent throughput and cost efficiency for long-context reasoning, directly addressing inference bottlenecks in cloud-service and edge-deployment applications. Theoretically, the method advances the integration of information-theoretic principles in model-systems co-design and may generalize to other sparsity management and forward-prediction tasks within deep learning architectures. Immediate future work includes further compression of DLM retrieval heads, exploration of speculative retrieval for hierarchical or multi-modal attention, and the extension of adaptive memory management to distributed serving environments.
Conclusion
SpeContext achieves high-fidelity, efficient long-context reasoning in LLMs through a synergy of distilled-model-based retrieval, asynchronous system-level dataflow, and adaptive memory allocation. The presented paradigm successfully breaks the conventional trade-off between accuracy and throughput, establishing new bounds in resource-constrained LLM serving and laying methodological foundations for broader speculative and alignment-based approaches in neural system optimization.

