- The paper introduces PRAXIS, a post-training procedural memory module that improves AI agent accuracy (from 40.3% to 44.1%), reliability, and efficiency.
- The paper details a dual-faceted retrieval method that indexes environmental and internal states to dynamically recall effective procedural traces.
- The paper demonstrates that PRAXIS scales across diverse models, offering practical benefits for applications like web automation and adaptive agent control.
Real-Time Procedural Learning From Experience for AI Agents
Introduction and Motivation
This paper introduces PRAXIS (Procedural Recall for Agents with eXperiences Indexed by State), a lightweight post-training procedural memory architecture for AI agents. The central problem addressed is the deficiency in existing LLM-based and multimodal agent systems regarding their capability to acquire and utilize procedural knowledge from real-time experience after deployment. While advances in retrieval-augmented architectures have enhanced factual recall in agents, real-world domains such as web browsing require robust, dynamic adaptation to shifting environments and task specifications—challenges that are not sufficiently addressed by static rule-based SOPs or context-limited retrieval of factual information.
Procedural knowledge in this context refers to the state-dependent policies—sequences of actions contingent on both the external environment and internal agent objective. Encoding, retrieving, and applying such procedural traces in real-time is essential for effective long-horizon agentic control in dynamic, partially observable environments such as browsers, reflected in the motivation for PRAXIS.
Methodology: State-Dependent Procedural Memory
PRAXIS is designed to plug into agentic architectures such as Altrina and augment action selection modules with a non-parametric, episodic memory. Each procedural memory trace is indexed by (1) environmental state before action, (2) internal agent state (such as current sub-goal), (3) action taken, and (4) resulting post-action environment state. Memories are dynamically generated by the agent either during self-supervised trial-and-error or via expert demonstration.
PRAXIS employs a dual-faceted retrieval algorithm for memory recall. For a given agent state, it computes similarity metrics between the current environment and historical states via visual and DOM feature overlap, as well as internal state embeddings. Top-k matches exceeding a similarity threshold are surfaced, and their action-result pairs are incorporated into the action selection context to bias the agent toward previously successful trajectories under analogous conditions.
This retrieval mechanism is robust to partial observability and supports efficient scaling of context breadth. The method does not require parameter updates or fine-tuning of the underlying foundation model, making it highly compatible with closed API-based systems.
Experimental Setting and Benchmark
The study evaluates PRAXIS within the Altrina agent framework on the REAL benchmark [garg_real_2025]. REAL offers deterministic clones of prominent websites and a diverse set of 112 practical tasks, enabling reproducible measurement of agent performance. Altrina, which natively supports VLM-based perception and node-based architectural scaffolding, is benchmarked in action selection with and without the procedural memory module.
The benchmark assesses key deployment metrics: task completion accuracy, reliability (mean success rate across repetitions), and efficiency (average steps to completion). Evaluations are repeated over five runs and across multiple foundation model backbones.
Empirical Results
Improvement in Accuracy
Across all tested VLM backbones, PRAXIS yields statistically measurable gains in both mean and best-of-$5$ accuracy on the REAL benchmark. Mean accuracy is increased from 40.3% to 44.1% with procedural memory, and best-of-$5$ accuracy rises from 53.7% to 55.7%. These gains indicate that state-indexed retrieval of procedural exemplars provides reusable priors that significantly improve agent behavior in complex, task-diverse, and stateful environments.
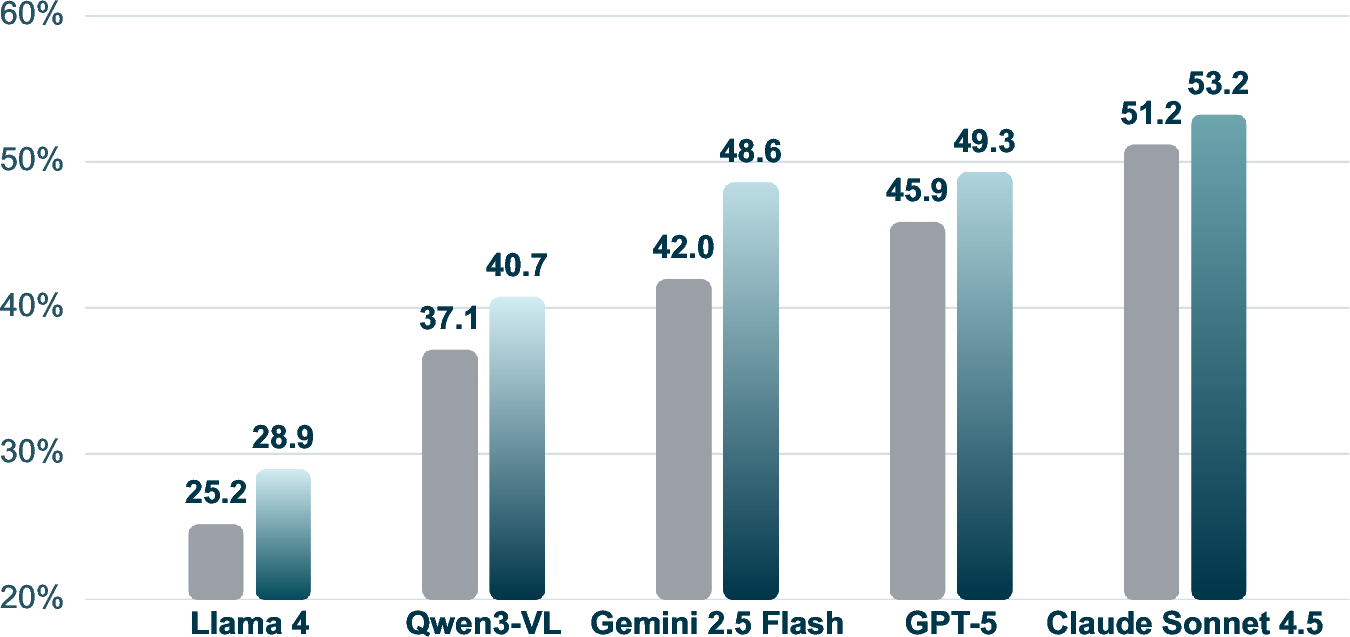
Figure 1: Performance on REAL benchmark for different models with and without procedural memory.
Enhancement of Reliability
Procedural memory also enhances reliability of agentic behavior. The mean per-task success rate over five runs is boosted from 74.5% to 79.0% averaged across all models, suggesting substantial reduction in undesirable stochastic variance and improved repeatability of agentic policies.
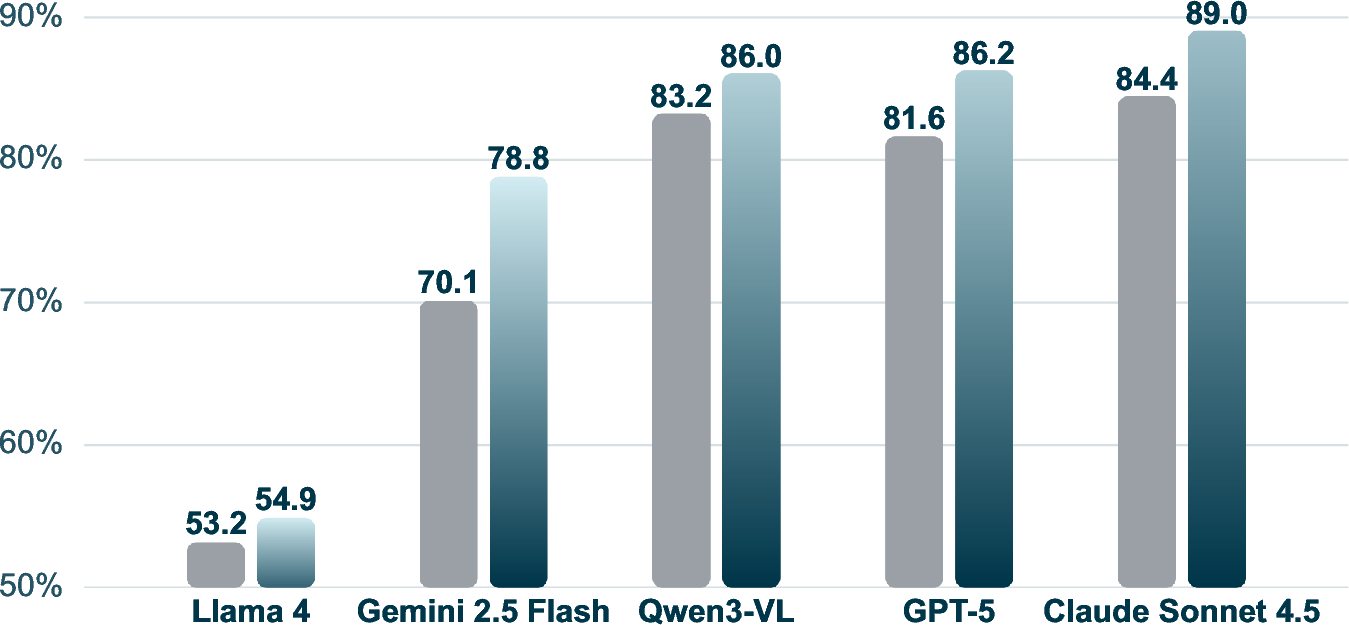
Figure 2: Agent reliability on REAL benchmark for different models with and without procedural memory.
Gains in Efficiency
Evaluations show that with procedural memory, the agents achieve successful task completion in fewer environment steps on average ($25.2$ to $20.2$), reflecting more targeted and effective action selection resulting from reusing correct past procedures. This effect persists across all model backbones.
Scaling with Retrieval Breadth
The study further ablates the retrieval breadth hyperparameter k and demonstrates that performance increases as k increases, up to a plateau. This suggests PRAXIS continues to provide useful context as memory breadth grows, although there can be context crowding beyond an optimal point.
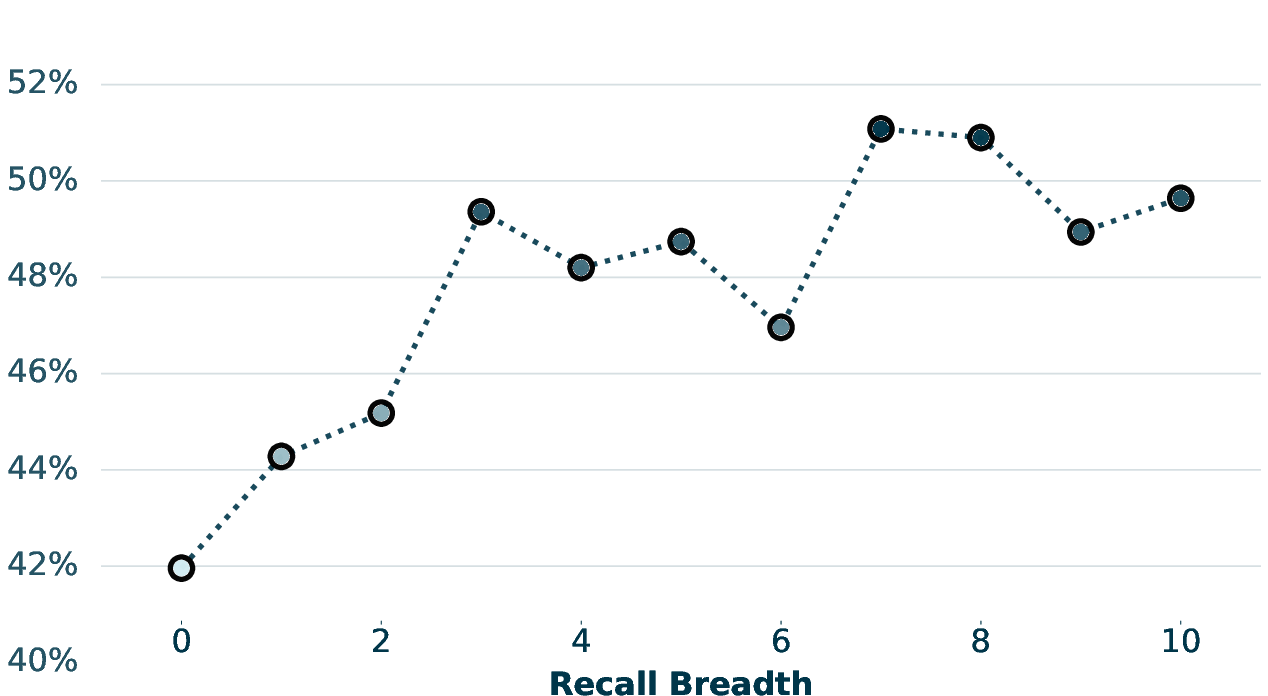
Figure 3: Performance as a function of retrieval breadth.
Discussion and Comparison with Prior Work
The critical advance of PRAXIS over factual memory systems such as Mem0 [chhikara_mem0_2025], Letta [packer2024memgptllmsoperatingsystems], and MemoryBank [zhong_memorybank_2023] is its explicit focus on stateful procedural recall rather than static fact retrieval. Unlike existing workflow memory approaches [wang_agent_2024, zheng_synapse_2024, zhao_expel_2023], PRAXIS directly indexes at the environment state granularity, breaking away from high-level trajectory abstraction in favor of precise, context-local recall suitable for visually grounded, high-entropy environments.
The methodology is also orthogonal to self-reflective, LLM-based improvement schemes such as Reflexion [shinn_reflexion_2023] and Self-Refine [madaan_self-refine_2023], which do not utilize environment state for retrieval and have limited applicability to non-textual, visual, and action-centric domains.
Empirically, the documented performance ceiling of 41% with conventional scaffolding on REAL emphasizes the necessity for robust procedural learning in agentic deployments [garg_real_2025]. PRAXIS provides a concrete and effective solution for this gap.
Implications and Future Directions
PRAXIS offers immediate practical value for deployments in rapidly changing environments where exhaustive pre-programming is infeasible and post-deployment learning is critical. By supporting incremental and personalized adaptation, it holds significant promise for enterprise automation, personalized assistants, and any domain where agent policies must be continuously aligned with evolving tasks and user preferences.
Theoretically, the work highlights the importance of tight coupling between environment state, agent intent, and experience replay for generalizable agentic control. Extensions of PRAXIS could incorporate richer, invariant state encoders, integrate adaptive or uncertainty-aware retrieval, and generalize to multi-modal digital or embodied settings. Moreover, incorporating user preference signals in the procedural memory could facilitate alignment with soft objectives beyond task completion, paving the way for more interactive and user-adaptive AI systems.
Conclusion
This paper delineates a principled approach to real-time procedural learning in AI agents via state-dependent procedural memory. PRAXIS demonstrates consistent, significant improvements in accuracy, reliability, and efficiency across several model architectures and establishes an extensible paradigm for post-training a posteriori procedural knowledge acquisition. The framework is a critical milestone toward general, robust, and adaptive agentic intelligence in complex, fast-evolving digital environments.