- The paper introduces Contextual Experience Replay (CER), a framework using dynamic memory buffers to replay past experiences for self-improvement of language agents.
- It demonstrates significant performance gains in realistic web environments, improving VisualWebArena success rates by 31.9% and showing a 51.0% relative improvement on WebArena.
- CER integrates distillation and retrieval modules to balance stability and plasticity, allowing agents to preserve existing knowledge while acquiring new skills.
Contextual Experience Replay for Self-Improvement of Language Agents
Overview
The paper introduces Contextual Experience Replay (CER), a novel framework designed to enable LLM agents to improve themselves through accumulating and synthesizing past experiences. LLM agents struggle with complex tasks such as web navigation due to a lack of environment-specific knowledge. CER allows these agents to gather experiences dynamically, enhancing adaptability without requiring additional training.
Contextual Experience Replay (CER) Mechanics
CER operates by storing past experiences in a dynamic memory buffer and replaying them when faced with new tasks. The framework divides experiences into environment dynamics and decision-making patterns, helping agents retrieve relevant knowledge for improved task-solving performance.
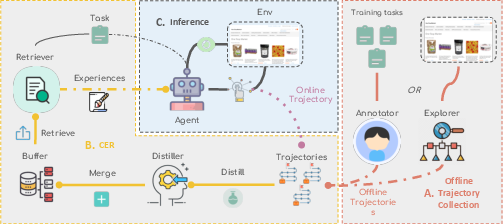
Figure 1: Overview of Contextual Experience Replay including offline and online settings.
The framework was evaluated on two benchmarks, WebArena and VisualWebArena. CER demonstrated significant improvements:
- VisualWebArena: Achieved a success rate of 31.9%, enhancing performance substantially with reduced token costs compared to tree search methods.
- WebArena: Showed a relative improvement of 51.0% over the GPT-4o baseline, achieving a success rate of 36.7%.
These results illustrate CER's potential to enhance agents' capabilities in realistic environments, showcasing compatibility with existing SOTA methods.
Distillation and Retrieval Modules
CER includes modules for distillation and retrieval. The distillation module extracts useful skills and dynamics from past trajectories, which are stored in memory. The retrieval module selects the most relevant experiences for the current task, strengthening the agent's decision-making process.
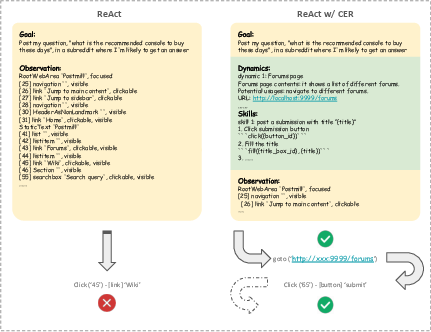
Figure 2: Compare ReAct baseline with ReAct + CER.
Stability and Plasticity
The framework ensures stability by preserving old knowledge and plasticity by acquiring new skills. Performance metrics demonstrated both improved stability and enhanced problem-solving capabilities across different task templates.
CER is compatible with various agents, including those utilizing advanced methods like tree search and sampling. Evaluations showed CER significantly improved performance when incorporated into existing agent systems, underscoring its potential for wide applicability.
Realistic Web Environments
WebArena and VisualWebArena provide challenging benchmarks reflecting real-world complexities, making them ideal for testing CER's effectiveness. The results offer robust evidence of CER's utility in practical applications.
Conclusion
CER provides a straightforward yet effective method for training-free self-improvement of LLM agents in complex web environments. Its ability to synthesize and replay contextually relevant experiences offers substantial improvements in adaptability and performance, pointing to promising applications for future autonomous agents. These findings suggest that leveraging past experiences is crucial for enhancing the capabilities of language agents in dynamic environments.