- The paper introduces ReasoningBank, a framework that distills generalizable reasoning patterns from both successful and failed agent experiences.
- It employs Memory-aware Test-Time Scaling (MaTTS) to enhance exploration, achieving up to 34.2% improvement in success rate and 16.0% fewer interaction steps.
- The closed-loop memory design enables agents to evolve self-improvement strategies, demonstrating robust generalization across diverse real-world benchmarks.
ReasoningBank: Scaling Agent Self-Evolving with Reasoning Memory
Motivation and Problem Statement
The paper introduces ReasoningBank, a memory framework designed to address the limitations of current LLM-based agent systems in persistent, real-world environments. Existing agents typically fail to leverage accumulated interaction history, resulting in repeated errors and missed opportunities for self-improvement. Prior memory mechanisms either store raw trajectories or focus solely on successful routines, lacking the abstraction of transferable reasoning strategies and neglecting the instructive value of failures. ReasoningBank is proposed to distill generalizable reasoning patterns from both successful and failed agent experiences, enabling agents to continuously evolve and improve their strategic capabilities.
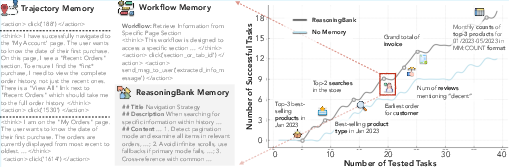
Figure 1: ReasoningBank induces reusable reasoning strategies, making memory items more transferrable for future use. This enables agents to continuously evolve and achieve higher accumulative success rates than the ``No Memory'' baseline on the WebArena-Admin subset.
ReasoningBank Architecture and Memory Induction
ReasoningBank operates as a closed-loop memory system. Experiences from agent-environment interactions are distilled into structured memory items, each comprising a title, description, and content. These items abstract away low-level execution details, focusing on high-level reasoning steps, decision rationales, and operational insights. The agent retrieves relevant memory items for each new task using embedding-based similarity search, integrates them into its system prompt, and, upon task completion, constructs new memory items from both successful and failed trajectories. These are consolidated into ReasoningBank, forming an evolving repository of actionable principles.
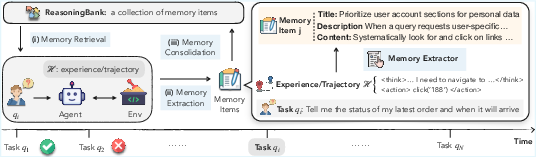
Figure 2: Overview of ReasoningBank. Experiences are distilled into structured memory items with a title, description, and content. For each new task, the agent retrieves relevant items to interact with the environment, and constructs new ones from both successful and failed trajectories. These items are then consolidated into ReasoningBank, forming a closed-loop memory process.
The extraction of memory items leverages LLM-as-a-judge for self-supervised labeling of trajectory outcomes. Successful trajectories yield validated strategies, while failed ones provide counterfactual signals and guardrails. This dual-source induction is a key differentiator, enabling the agent to learn not only from successes but also from its own mistakes.
Memory-Aware Test-Time Scaling (MaTTS)
Building on ReasoningBank, the paper introduces Memory-aware Test-Time Scaling (MaTTS), which synergizes memory with test-time scaling to accelerate and diversify agent learning. Rather than scaling by breadth (more tasks), MaTTS scales by depth, allocating more compute to each task to generate diverse exploration trajectories. MaTTS is instantiated in two modes:
- Parallel Scaling: Multiple trajectories are generated for the same query, and self-contrast across these trajectories curates reliable memory by identifying consistent reasoning patterns and filtering out spurious solutions.
- Sequential Scaling: The agent iteratively refines its reasoning within a single trajectory, using intermediate notes as valuable signals for memory induction.
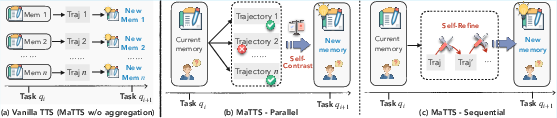
Figure 3: Comparison of (a) vanilla TTS and MaTTS with (b) parallel scaling, where self-contrast across multiple trajectories curates reliable memory, and (c) sequential scaling, where self-refinement enriches memory with intermediate reasoning signals.
MaTTS establishes a positive feedback loop: high-quality memory steers exploration toward promising paths, while diverse experiences generated by scaling forge even stronger memory. This positions memory-driven experience scaling as a new dimension for agentic systems.
Empirical Results and Analysis
Experiments on WebArena, Mind2Web, and SWE-Bench-Verified benchmarks demonstrate that ReasoningBank consistently outperforms baselines (No Memory, Synapse, AWM) in both effectiveness (success rate) and efficiency (interaction steps). Notably, ReasoningBank achieves up to 34.2% relative improvement in success rate and 16.0% reduction in interaction steps. Gains are especially pronounced in generalization settings (cross-task, cross-website, cross-domain), where ReasoningBank's memory items enable robust transfer across diverse scenarios.
MaTTS further amplifies these gains. Increasing the scaling factor k in parallel and sequential modes leads to monotonic improvements in success rate, with ReasoningBank-equipped MaTTS outperforming vanilla TTS and memory-free scaling. Sequential scaling shows short-term advantage at small k, but parallel scaling dominates at larger scales due to sustained diversity in rollouts.
The synergy between memory and scaling is evident: high-quality memory enables stronger test-time scaling performance, and scaling yields better memory curation only when paired with robust memory mechanisms. Weak memory designs (e.g., Synapse, AWM) fail to harness the benefits of scaling, sometimes even degrading performance due to noise from redundant rollouts.
Emergent Behaviors and Failure Incorporation
ReasoningBank facilitates the emergence of increasingly sophisticated reasoning strategies over time. Memory items evolve from procedural rules to adaptive self-reflections and compositional strategies, mirroring the learning dynamics observed in RL-based systems.

Figure 4: A case study illustrating emergent behaviors in ReasoningBank through memory items.
Incorporating failure trajectories is shown to be critical. Unlike baselines that degrade or stagnate when failures are added, ReasoningBank leverages failures to distill preventative lessons, achieving higher success rates and more robust generalization.
Efficiency and Case Studies
Efficiency analysis reveals that ReasoningBank reduces unnecessary exploration, particularly on successful instances, with up to 2.1 fewer steps per task. This indicates that memory-driven agents reach solutions more efficiently by following effective reasoning paths rather than truncating failed attempts.
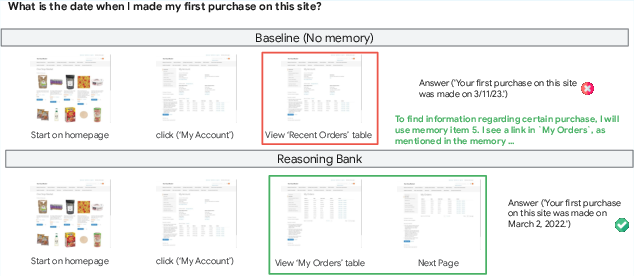
Figure 5: ReasoningBank enables the agent to recall and apply past reasoning hints, guiding it to the full order history and yielding the correct first purchase date, unlike the baseline that fails with only recent orders.

Figure 6: ReasoningBank improves efficiency by leveraging past reasoning hints, reducing the navigation from 29 steps to 10 steps compared to the baseline without memory.
Implementation Considerations
The ReasoningBank framework is intentionally minimal in retrieval and consolidation, relying on embedding-based similarity search and direct addition of new memory items. This isolates the effect of memory content quality. The system is compatible with more advanced memory architectures (episodic, hierarchical) and retrieval strategies, which could further enhance performance. The dependence on LLM-as-a-judge for correctness signals introduces potential noise, but empirical results indicate robustness to such imperfections.
Implications and Future Directions
ReasoningBank establishes memory-driven experience scaling as a practical and theoretically sound pathway for building adaptive, lifelong-learning agents. The framework's ability to distill and reuse reasoning strategies from both successes and failures, combined with memory-aware scaling, enables agents to self-evolve and exhibit emergent behaviors. Future work may explore compositional memory, advanced memory stacks, and more sophisticated retrieval/consolidation mechanisms. Integrating ReasoningBank with product-level memory services and learning-based controllers could yield scalable, deployable agentic systems across domains.
Conclusion
ReasoningBank advances the state of agent memory by abstracting and leveraging high-level reasoning strategies from both successful and failed experiences. Its integration with memory-aware test-time scaling (MaTTS) demonstrates strong empirical gains in effectiveness, efficiency, and generalization. The framework's closed-loop design and synergy with scaling mechanisms provide a foundation for self-evolving agentic systems, with significant implications for the development of adaptive, robust, and efficient AI agents in persistent real-world environments.