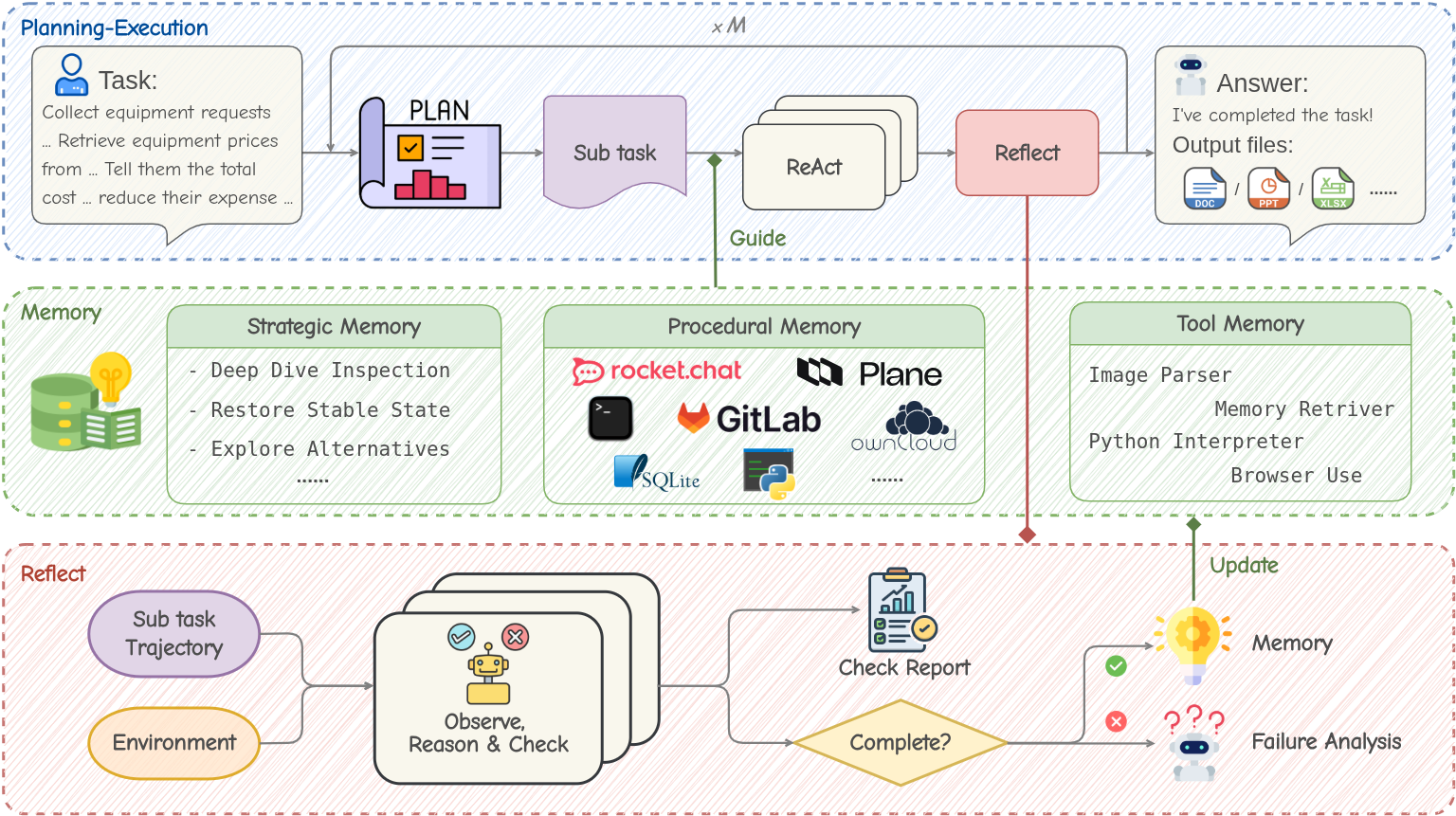
- The paper presents the MUSE framework that integrates a Memory Module, Planning-Execution Agent, and Reflect Agent to facilitate continuous self-evolution.
- The framework achieves state-of-the-art performance on the TAC benchmark, demonstrating significant improvements in long-horizon task completion.
- The experience-driven design enables effective avoidance of failed strategies and zero-shot generalization, ensuring robust and adaptive task handling.
Learning on the Job: An Experience-Driven Self-Evolving Agent for Long-Horizon Tasks
Introduction
The paper presents the MUSE framework, which aims to overcome static test-time limitations of LLMs in handling real-world long-horizon tasks. Existing LLM agents typically lack the capacity for continuous evolution from accumulated knowledge due to their static pretrained nature. This research proposes MUSE as a solution, equipping agents with a hierarchical Memory Module designed for constant self-improvement through structured experience accumulation, which allows the system to dynamically evolve.
MUSE Framework Overview
MUSE leverages a closed-loop, experience-driven framework composed of a Memory Module, a Planning-Execution (PE) Agent, and a Reflect Agent. The Memory Module, pivotal in the system, is responsible for storing procedural knowledge, strategic patterns, and tool-use guidance. It facilitates agents' ability to plan and execute long-horizon tasks without relying solely on static pretrained models.
- Planning-Execution Agent: This component decomposes complex tasks into sub-tasks and iteratively attempts resolution by leveraging accumulated procedural memories.
- Reflect Agent: After task attempt, this component evaluates the task execution trajectory, refining the knowledge base and facilitating continuous agent evolution.
Key Components of MUSE
Memory Module
The Memory Module is structured into three distinct layers:
- Strategic Memory: Focuses on high-level behavioral paradigms drawn from dilemmas encountered and their solutions.
- Procedural Memory: Archives successful sub-task executions, forming a Standard Operating Procedures (SOP) base for task resolution.
- Tool Memory: Functions as the agent's "muscle memory" for individual tool use, offering immediate contextual feedback.
This module's design supports memory-laden LLM agnosticism, allowing the reuse of accumulated knowledge across different models seamlessly.
Methodology and Implementation
The MUSE process follows a loop of "Plan-Execute-Reflect-Memorize":
- Plan and Execute: Breaks down tasks and systematically navigates through them using procedural memory guides.
- Reflect and Memorize: Evaluates task execution for successful cases and failure analysis, continuously updating the memory database.
The framework's independence from LLM fine-tuning keeps the innate generalization capacity intact while improving performance through iterative task interaction.
Experimental Evaluation
The framework was rigorously tested on the TheAgentCompany (TAC) benchmark designed for long-horizon productivity tasks. The evaluation indicated:
Continuous Learning and Generalization
MUSE's capacity for continuous learning was validated through iterative training rounds, showing marked performance improvements. The memory mechanisms allowed the agent to effectively avoid previously failed exploration paths, resulting in efficient task completion.
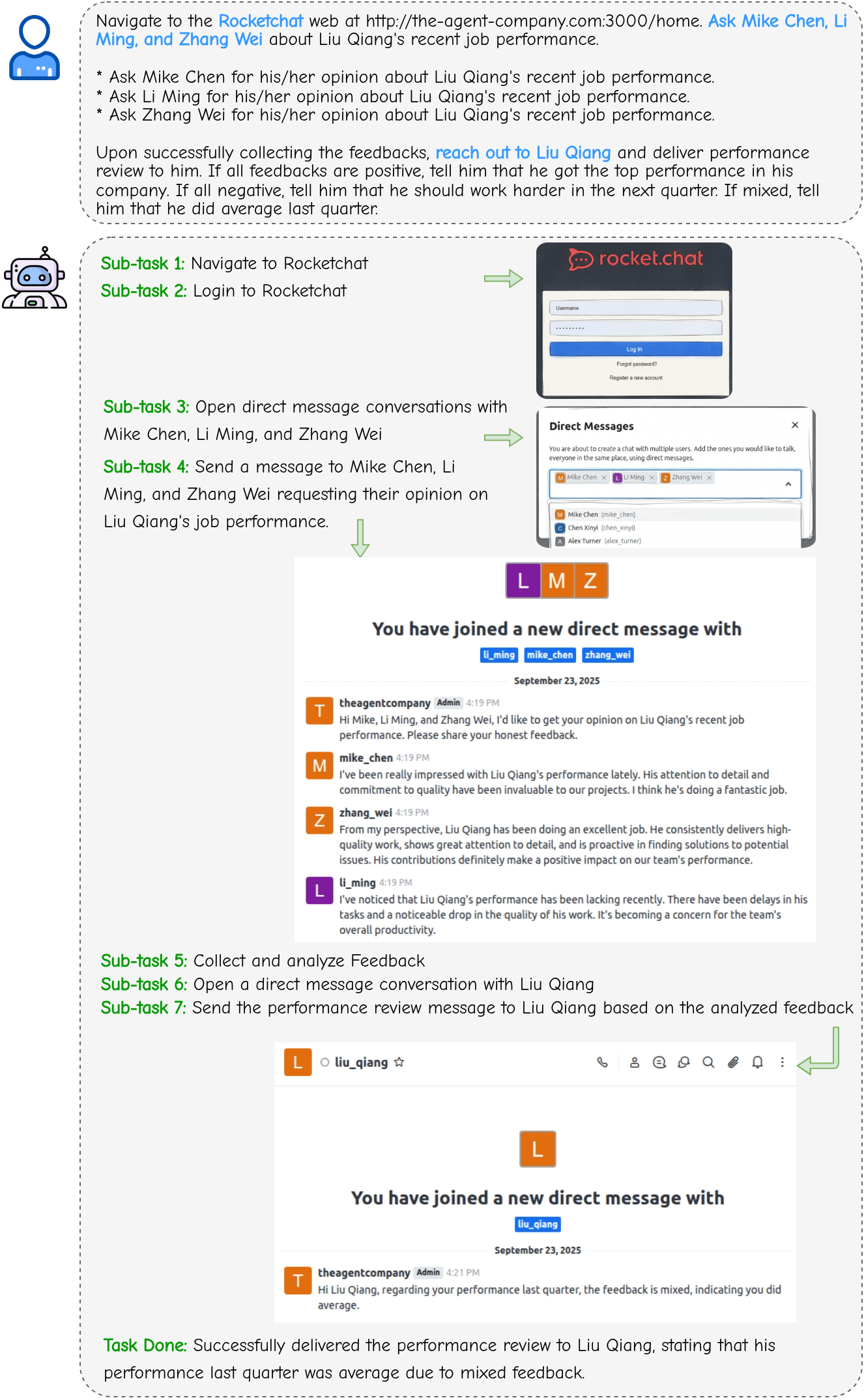
Figure 2: Case study on task ``hr-collect-feedbacks'' displaying MUSE's capability in processing task feedback collectively, as opposed to traditional sequential approaches.
Considerable evaluations on challenging task sets revealed MUSE's substantial superiority in handling previously unseen tasks, highlighting its robust generalization capabilities across different LLMs.
Conclusion
MUSE introduces a unique paradigm for deploying AI agents capable of self-evolution without finetuning. By enabling real-world productivity task automation through structured memory systems, MUSE presents a transformative leap in AI agent design. The results not only validate the efficacy of MUSE in long-horizon tasks but also illustrate a promising direction for developing future autonomous AI systems that learn and improve over time.