XR-1: Towards Versatile Vision-Language-Action Models via Learning Unified Vision-Motion Representations
Abstract: Recent progress in large-scale robotic datasets and vision-LLMs (VLMs) has advanced research on vision-language-action (VLA) models. However, existing VLA models still face two fundamental challenges: (i) producing precise low-level actions from high-dimensional observations, (ii) bridging domain gaps across heterogeneous data sources, including diverse robot embodiments and human demonstrations. Existing methods often encode latent variables from either visual dynamics or robotic actions to guide policy learning, but they fail to fully exploit the complementary multi-modal knowledge present in large-scale, heterogeneous datasets. In this work, we present X Robotic Model 1 (XR-1), a novel framework for versatile and scalable VLA learning across diverse robots, tasks, and environments. XR-1 introduces the \emph{Unified Vision-Motion Codes (UVMC)}, a discrete latent representation learned via a dual-branch VQ-VAE that jointly encodes visual dynamics and robotic motion. UVMC addresses these challenges by (i) serving as an intermediate representation between the observations and actions, and (ii) aligning multimodal dynamic information from heterogeneous data sources to capture complementary knowledge. To effectively exploit UVMC, we propose a three-stage training paradigm: (i) self-supervised UVMC learning, (ii) UVMC-guided pretraining on large-scale cross-embodiment robotic datasets, and (iii) task-specific post-training. We validate XR-1 through extensive real-world experiments with more than 14,000 rollouts on six different robot embodiments, spanning over 120 diverse manipulation tasks. XR-1 consistently outperforms state-of-the-art baselines such as $π_{0.5}$, $π_0$, RDT, UniVLA, and GR00T-N1.5 while demonstrating strong generalization to novel objects, background variations, distractors, and illumination changes. Our project is at https://xr-1-vla.github.io/.


Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
XR-1 in Simple Terms
This paper is about teaching robots to understand what they see, what we say, and how to move—at the same time. The researchers built a system called XR-1 that helps different kinds of robots learn useful skills from many kinds of data, including regular human videos on the internet, and then use those skills to do real-world tasks like picking up objects, stacking things, opening doors, and more.
What problem are they trying to solve?
Robots struggle with two big issues:
- Turning camera images (which are huge and detailed) into very precise movements (like moving a gripper by a centimeter).
- Learning from many different sources (different robot bodies and human videos) that don’t match each other perfectly.
The Big Questions (in Everyday Language)
The paper asks:
- How can a robot learn movements that match what it sees, even if the data comes from different places (robot demos and human videos)?
- How can this learning work across many different kinds of robots with different arms, hands, and joints?
- Can this approach help robots perform better and generalize to new tasks, new objects, and new environments?
How XR-1 Works
To make this understandable, think of XR-1 as teaching robots a shared “language” that describes both what changes in a scene (vision) and how to move (motion). Once a robot knows this language, it can learn faster from all sorts of videos and apply that knowledge to different robots and tasks.
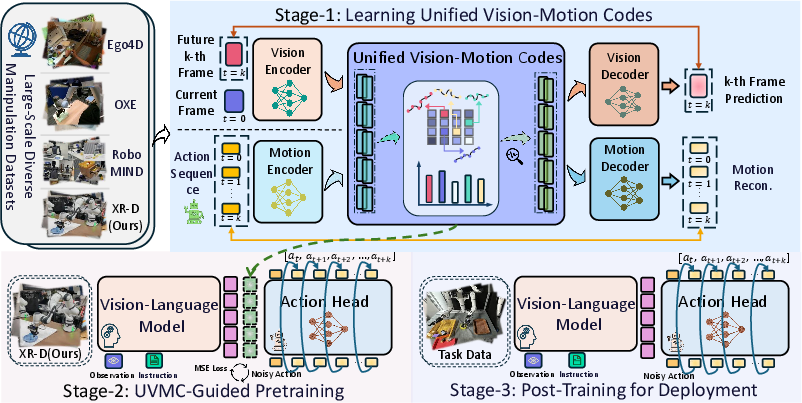
Core idea: Unified Vision-Motion Codes (UVMC)
- Imagine you watch a short video of a cup being moved and you also see the robot’s joint movements that made it happen. XR-1 turns both the visual change and the movement into small, discrete “codes” (like short words) that describe what’s happening.
- It learns these codes with a tool called a “dual-branch VQ-VAE.” Don’t worry about the name—think of it as two translators:
- One translator watches pairs of frames (now and a bit later) and summarizes the visual change (like “the cup moved right”).
- The other translator looks at the robot’s actions and body positions over the same time and summarizes the motion (like “move joint A by this much, close gripper”).
- Both translators use the same dictionary of codes. This shared dictionary forces the “what you see” codes and the “how you move” codes to match up.
- The system also nudges the vision-codes to stay aligned with the motion-codes, like keeping movie subtitles in sync with the audio. This “alignment” keeps vision focused on movement-relevant details (not distractions like background or lighting).
Why this matters: Human videos usually don’t include robot actions, but they do show visual changes. By learning a shared code, XR-1 can still learn useful movement ideas from human videos and apply them to robots.
The three-stage training plan
To make the most of this idea, XR-1 trains in three steps:
- Learn the shared codes (UVMC)
- Self-supervised learning on a mix of robot data and huge piles of human videos.
- Goal: build a strong, shared “vision–motion” dictionary of codes.
- Pretrain a general robot policy with UVMC guidance
- A vision-LLM (the kind that understands images and instructions) is trained to predict the UVMC codes and actions from what it sees and the instruction it gets.
- This injects the learned “movement language” directly into the model, making action prediction easier and more stable.
- Fine-tune for specific robots and tasks
- Finally, the model gets sharpened on the target robot’s own data so it can perform reliably in the real world.
A quick analogy
- Stage 1: Build a shared alphabet and vocabulary for “changes you see” and “moves you make.”
- Stage 2: Teach a student to read and write with that vocabulary across many books (robots and tasks).
- Stage 3: Coach the student for a specific exam (a particular robot and set of tasks).
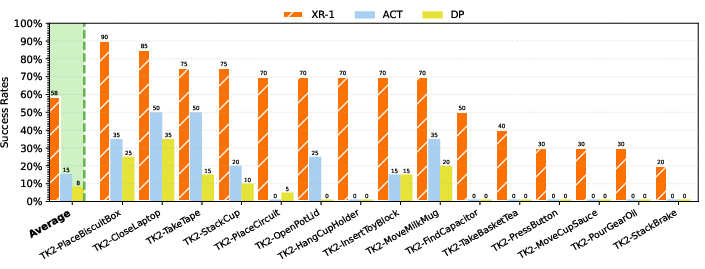
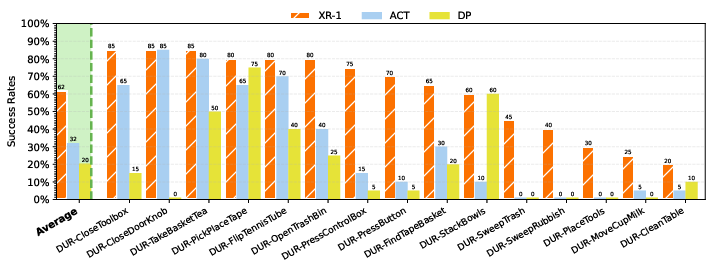
What They Found (Results)
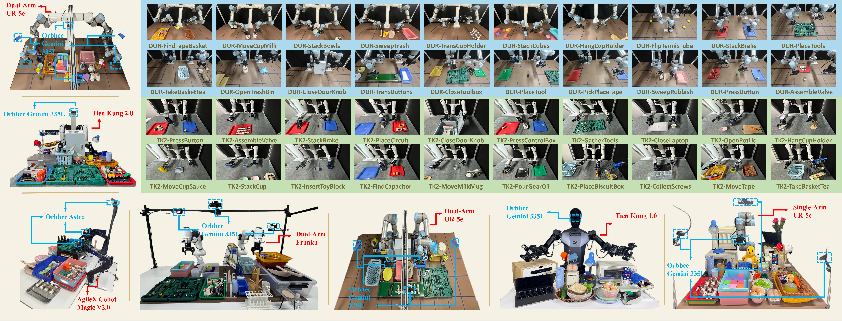
The researchers tested XR-1 in over 14,000 real robot runs on 6 different robot setups and more than 120 tasks. Here’s what stood out:
- It beat strong existing methods (like π0.5, π0, RDT, UniVLA, and GR00T-N1.5) on many challenging tasks, including two-arm manipulation, deformable objects, long sequences, and contact-heavy moves.
- It handled “new stuff” well: new objects, distracting things moving around, different backgrounds, and changes in lighting.
- It transferred to robots it hadn’t seen during pretraining (new “robot bodies”), showing strong “cross-embodiment” skill.
- It showed good “out-of-the-box” performance (even before final fine-tuning) and adapted quickly to new tasks with very few examples (like 20 demos per task).
- Even a smaller version (XR-1-Light) benefited a lot from the UVMC approach, which is good news for people without huge compute.
They also ran ablations (turning parts off to test importance):
- Without the shared codes (UVMC), performance dropped a lot.
- Without the “keep vision and motion in sync” alignment, it also got worse.
- Using more pretraining data consistently improved performance.
Why This Matters
- Learn from human videos: Robots can finally use the vast amount of online videos (which usually don’t include action labels) because XR-1 aligns “what you see” with “how you move.”
- Works across many robots: The shared codes reduce the gap between different robot bodies, so skills transfer better.
- More reliable, more general: XR-1 is better at handling messy, real-world changes—exactly what home, hospital, and factory environments look like.
- Practical path forward: The three-stage recipe and the code-based alignment can be plugged into different robot models, making it a flexible blueprint for building generalist robots.
Short Takeaway
XR-1 gives robots a shared “movement language” that connects vision and action. By learning this language from both robot demos and human videos, then feeding it into a vision-language-action model, robots get better at precise control, adapt faster to new tasks, and work across different robot bodies and changing environments. This is a solid step toward versatile, helpful robots that understand instructions and reliably act in the real world.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
The paper leaves several important issues unexplored or insufficiently validated; addressing these would help future researchers assess, extend, and deploy XR-1 more reliably:
- Quantitative contribution of human video pretraining: no ablation isolating the effect of actionless human videos (e.g., w/o Ego4D, or varying human:robot data ratios) on downstream control performance.
- How cross-modal alignment transfers to human-only data: alignment is trained only where motion labels exist; no mechanism or study for aligning visual codes from human videos to motion space beyond shared codebook, nor weak/pseudo-label strategies for unpaired human data.
- Sensitivity to codebook design: no analysis of codebook size, dimensionality, initialization, update strategy, or dead-code prevalence and its impact on control accuracy and generalization.
- Alternative quantization schemes: no comparison of single VQ vs residual vector quantization, product quantization, Gumbel-softmax, or learned discrete-continuous hybrids for finer control granularity.
- Stability and utilization of codes: no metrics on code usage entropy, code collapse, mutual information between codes and actions, or whether motion decoder over-relies on observations/language instead of latent codes.
- Alignment objective choice: KL direction and weighting are fixed; no study of symmetric divergences (JS), Wasserstein/MMD alignments, contrastive InfoNCE, or scheduling of alignment strength across training.
- Definition of q(z) for VQ posteriors: unclear how distributions over codes are computed in a discrete deterministic VQ (e.g., soft assignments via distances); missing implementation details limit reproducibility of the KL alignment.
- Vision loss choice: future-frame reconstruction uses L1; no evaluation of perceptual loss, feature matching, masked modeling, or diffusion-based dynamics modeling to reduce blur and improve motion-relevant features.
- Horizon design: h-step temporal window is fixed; no study of horizon sensitivity, variable-step encoding, or multi-scale temporal codes for long-horizon manipulation.
- UVMC supervision in Stage-2: the VLM predicts continuous embeddings with MSE; no comparison to classification over code indices or contrastive objectives better aligned with discrete code structure.
- Inference-time use of UVMC: unclear whether UVMC tokens are used at inference or only as auxiliary pretraining targets; no ablation on keeping vs dropping UVMC pathways at deployment.
- Language grounding from human videos: Ego4D contains narrations/ASR, yet human-video pretraining appears text-free; unexplored gains and risks from pairing or aligning language with human visual dynamics.
- Instruction generalization: no tests on paraphrases, unseen verbs, compositional instructions, or multilingual commands; language robustness remains unassessed.
- Embodiment coverage limits: tested mainly on industrial arms with parallel grippers; no evidence for transfer to dexterous multi-finger hands, variable gripper types, mobile manipulation with base control, or legged platforms.
- Action space unification: joint-position control is assumed; no explicit scheme for normalizing across different DoFs, joint limits, or kinematic trees, nor handling of discrete/continuous actuation heterogeneity.
- Proprioception scope: motion encoder uses joints and gripper only; no tactile/force/torque integration, which likely limits performance in contact-rich tasks; impact unquantified.
- Safety and constraint handling: no mechanisms for collision avoidance, force limits, or safe recovery; dual-arm coordination safety is not evaluated.
- Real-time performance: missing latency, throughput, control frequency, and hardware requirements for on-robot inference and Stage-1/2 training; compute/data efficiency remains unclear.
- Evaluation breadth and rigor: success rate only; no task time, path efficiency, smoothness, forces, or safety violations; no statistical tests, confidence intervals, or failure-mode taxonomy.
- Out-of-distribution stress tests: limited OOD scenarios; no occlusion, severe camera pose shifts, sensor noise, domain randomization, or camera failure tests.
- Multi-view fusion details: unspecified fusion architecture, calibration assumptions, and robustness to asynchronous or missing views; no ablations on number/placement of cameras.
- Planning vs control: long-horizon claims lack explicit evaluation of subgoal planning, re-planning under disturbances, or integration with high-level planners/CoT.
- Data governance and reproducibility: XR-D is in-house and apparently not public; replicability, dataset bias, and license constraints are unaddressed.
- Baseline comparability: some baselines use different frameworks (e.g., pi_0 JAX vs Lerobot); fairness and sensitivity to implementation choices not audited.
- Domain gap analysis: no quantitative study of appearance/motion statistics mismatch between human videos and robot data, nor techniques like viewpoint normalization or pose canonicalization.
- Cross-embodiment transfer protocol: limited leave-one-robot-out experiments; no systematic evaluation across a wider set of morphologies and DoF regimes.
- Hyperparameter sensitivity: missing sweeps for alignment weight, codebook size, h, dataset sampling weights, learning rates, or pretraining duration.
- Continual and life-long learning: how XR-1 adapts without catastrophic forgetting or with streaming task additions is not studied.
- Interpretability of UVMC: no analysis linking codes to motion primitives or skills; absence of tools to inspect, edit, or compose codes for controllable behavior synthesis.
- Robustness to dataset noise: no evaluation under noisy labels, mis-synced sensors, or weak demonstrations; impact of imperfect teleoperation not measured.
- Sim-to-real and simulation leverage: no use of simulators for scalable UVMC learning or transfer; potential benefits and pitfalls remain open.
- Ethical and privacy considerations: training on human videos (e.g., Ego4D) raises privacy concerns; dataset curation and consent practices are not discussed.
Practical Applications
Practical Applications Derived from XR-1 (Unified Vision-Motion Codes + Three-Stage VLA Training)
XR-1 introduces Unified Vision-Motion Codes (UVMC) learned via a dual-branch VQ-VAE with explicit vision–motion alignment and a three-stage training paradigm (self-supervised UVMC from human+robot data, UVMC-guided VLA pretraining, task-specific post-training). The framework is model-agnostic, supports cross-embodiment transfer, few-shot adaptation (≈20 demos), and robust performance under distractors/illumination changes. Below are actionable applications, grouped by deployment horizon.
Immediate Applications
The following applications can be piloted or deployed now with existing industrial arms, service robots, and academic setups using XR-1 or XR-1-Light.
- Multi-robot cell (brownfield) onboarding and re-tasking
- Sector: Manufacturing, Robotics Integration
- Use case: Rapidly deploy or repurpose tasks (press buttons, turn valves, stack, place, insert, sweep, open/close doors/covers) across heterogeneous arms (UR, Franka, dual-arm setups).
- Tools/workflow: XR-1 pretrain checkpoints + 20-shot on-site demos (Stage-3) + ROS/PLC interface; UVMC extractor for leveraging historic human/operator videos of line operation to warm-start Stage-1.
- Dependencies: Multi-view cameras; accurate robot-camera calibration; safety cage/collision monitoring; mapping XR-1 action head to plant controllers; task similarity to pretraining distribution.
- Few-shot task onboarding for high-mix, low-volume lines
- Sector: Manufacturing/Assembly, Electronics
- Use case: 15–20 demonstration trajectories per new SKU to attain usable success rates for pick–place, cable routing, fixture loading, fastener alignment, box packing.
- Tools/workflow: Teleoperation demo collection → Stage-3 fine-tune → validation; optional UVMC-guided curriculum (start with simple sub-tasks).
- Dependencies: Good-quality demonstrations; appropriate gripper/tooling; latency budgets for real-time control.
- Cross-embodiment fleet policy unification
- Sector: 3PL/Warehousing, Contract Manufacturing
- Use case: One policy servicing different arm models/end-effectors across sites, reducing per-cell retraining and maintenance effort.
- Tools/workflow: Stage-2 UVMC-guided pretraining on cross-embodiment datasets; standardized camera placement SOP; unified action interface adapters.
- Dependencies: Reasonable parity in end-effector capabilities; site-specific calibration.
- Robust bin-picking, sorting, and packing under visual distractors
- Sector: Logistics, E-commerce Fulfillment
- Use case: Handle clutter, moving distractors, lighting fluctuations, and novel SKUs.
- Tools/workflow: XR-1 inference with multi-view inputs; optional UVMC augmentation with unlabeled warehouse footage.
- Dependencies: Adequate lighting or HDR cameras; reachable workspace; verified suction/grasp planning.
- Language-driven operator-in-the-loop control
- Sector: Industrial Service, Facilities
- Use case: “Pick up the blue box and place it in slot B”; “Sweep trash into the dustpan”; “Open the cabinet and hang the cup.”
- Tools/workflow: XR-1 VLM interface exposed through HMI/voice; skill library backed by UVMC embeddings; supervised overrides.
- Dependencies: Speech/NLU pipeline; safety interlocks; environments consistent with instruction grounding.
- On-robot lightweight inference
- Sector: Mobile Manipulation, Field Service
- Use case: Deploy XR-1-Light (~230M params) on edge compute to execute routine tasks (door opening, knob turning, tool pickup).
- Tools/workflow: INT8/FP16 optimized inference; camera streams; ROS 2 nodes for UVMC token injection.
- Dependencies: Edge GPU/TPU; thermal/power constraints; action-rate matching to hardware.
- Lab automation for routine manipulations
- Sector: R&D Labs, Biotech (non-sterile tasks), Education
- Use case: Open/close containers, place samples, operate simple instruments (e.g., switches, trays, lids).
- Tools/workflow: Small data capture in lab + fine-tuning; UVMC pretraining on human lab videos (Ego4D-like).
- Dependencies: Safety and contamination policies; precise fixtures; compliance constraints.
- Cross-domain data leverage and dataset unification
- Sector: Academia, Robotics Software
- Use case: Train policies by mixing robot datasets and human videos without action labels via UVMC; reduce annotation cost.
- Tools/workflow: UVMC codebook training; dataset weighting (as in paper); model-agnostic Stage-2 integration with existing VLAs (e.g., Pi0, SwitchVLA).
- Dependencies: Data governance for human videos; compute for Stage-1 pretraining.
- Rapid benchmarking and curriculum learning
- Sector: Academia, Developer Tooling
- Use case: Use UVMC as intermediate targets to stabilize training and ablate visual/action alignment; run few-shot adaptation studies.
- Tools/workflow: XR-1 training recipes; evaluation harness; task packs for UR/Franka.
- Dependencies: Standardized multi-view capture; reproducible baselines.
- Safety-facing manipulation of physical controls
- Sector: Process Industries, Utilities
- Use case: Press emergency/maintenance buttons, turn valves, flip breakers under supervision.
- Tools/workflow: XR-1 with verified motion constraints; geofenced workspaces; kill-switch integration.
- Dependencies: Strict safety audits; force/torque monitoring; compliance with site standards.
- Data SOPs and governance patterns (immediate policy guidance)
- Sector: Policy, Compliance, Corporate Governance
- Use case: Establish SOPs for collecting robot + multi-view video data; retention, anonymization of human videos for UVMC training; benchmark sharing.
- Tools/workflow: Consent pipelines; data catalogs with dataset weights; privacy-preserving blurring.
- Dependencies: Legal approval (GDPR/CCPA); license compliance for web video use.
- Home/personal robotics pilot tasks (supervised)
- Sector: Consumer Robotics, Elder Support (pilot)
- Use case: Surface tidying, cup/mug relocation, cabinet opening/closing under caregiver supervision.
- Tools/workflow: XR-1-Light; caregiver voice commands; few-shot household demo capture.
- Dependencies: Strong safety barriers; reliable perception in clutter; insurance/regulatory acceptance.
Long-Term Applications
These require further research, scaling, safety validation, or regulatory approvals, but are natural extensions enabled by UVMC and cross-embodiment VLA learning.
- General-purpose household assistants
- Sector: Consumer Robotics
- Use case: Multi-room, long-horizon chores (laundry handling, dish loading, tool fetching) in diverse homes.
- Tools/workflow: Lifelong learning with UVMC from in-the-wild human videos; on-device adaptation; skill libraries.
- Dependencies: Robust navigation + manipulation integration; comprehensive safety; cost-effective hardware.
- Hospital and eldercare manipulation
- Sector: Healthcare
- Use case: Bedside item delivery, drawer operation, IV line management assistance (non-critical); instrument handover in sterile workflows (far horizon).
- Tools/workflow: Clinically certified variants; UVMC trained on medical SOP videos with strict privacy; shared autonomy.
- Dependencies: Regulatory certification (FDA/CE); fail-safe physical interaction; sterilization constraints; extensive validation.
- Autonomous maintenance and inspection
- Sector: Energy, Utilities, Oil & Gas
- Use case: Panel operation, valve turning, lever manipulation in plants and substations; nighttime/low-light robustness.
- Tools/workflow: Domain-adapted UVMC from archival plant footage; constrained action layers; remote audit logs.
- Dependencies: Harsh environment tolerance; ATEX-rated hardware; cybersecurity and network policies.
- Construction and field assembly
- Sector: Construction, Infrastructure
- Use case: Tool use (measuring, fastening), temporary fixture placement, cable routing in dynamic sites.
- Tools/workflow: Bimanual XR-1 variants + tool-change workflows; human video mining from site cams; site-specific codebooks.
- Dependencies: Dexterous end-effectors; terrain mobility; robust scene understanding; union/regulatory frameworks.
- Dexterous hand manipulation (high-DoF)
- Sector: Advanced Robotics, Prosthetics
- Use case: In-hand reorientation, cloth manipulation, fastening tasks; telemanipulation assistance for prosthetic training.
- Tools/workflow: Extend UVMC to hand-centric proprioception/actions; tactile sensing integration; diffusion/auto-regressive hybrid heads.
- Dependencies: Large-scale dexterous datasets; high-fidelity sensing; sim2real gap closure.
- “Learn from watching” on production lines
- Sector: Manufacturing
- Use case: Robots learn new steps by observing human workers’ videos; auto-propose action plans for oversight approval.
- Tools/workflow: UVMC alignment from human-only videos → robot policies; human-in-the-loop review tools.
- Dependencies: Detailed task segmentation; action grounding without labels; worker privacy and consent.
- Agricultural manipulation
- Sector: Agriculture
- Use case: Fruit/vegetable picking and sorting in varied lighting and foliage; tool-assisted cuts or twists.
- Tools/workflow: Domain pretraining with UVMC on farm video; seasonally adaptive fine-tunes; robust grippers.
- Dependencies: Crop-specific end-effectors; gentle contact control; weatherproofing.
- Disaster response and remote intervention
- Sector: Public Safety, Defense
- Use case: Clearing debris, turning valves, opening doors in unstructured, dark, dusty environments via language commands.
- Tools/workflow: Teleoperation fallback; XR-1 with strong OOD robustness; UVMC pretraining on synthetic disaster scenarios + web videos.
- Dependencies: Ruggedized platforms; low-latency comms; safety in unknown contact dynamics.
- Cross-fleet cloud learning and “skill store”
- Sector: Software Platforms, Robotics-as-a-Service
- Use case: Shared UVMC codebooks and policies across customers with privacy controls; downloadable task skills per robot type.
- Tools/workflow: Federated UVMC training; ROS 2 middleware plugins; policy versioning and rollback.
- Dependencies: Data sovereignty; multi-tenant security; model update governance.
- Privacy-preserving UVMC and compliance tech
- Sector: Policy/RegTech, Enterprise IT
- Use case: Federated/self-supervised UVMC learning on on-prem human videos; DP/secure aggregation; audit trails.
- Tools/workflow: Federated training server; differential privacy for codebooks; dataset weight tracking.
- Dependencies: Legal frameworks; compute at the edge; standardized audit requirements.
- Formal safety layers and certifiable action constraints
- Sector: Safety/Certification
- Use case: Certify XR-1 action heads with model checking/constraint solvers; runtime monitors that bound forces/velocities.
- Tools/workflow: Safety envelope generators; constrained decoders around UVMC; third-party certification toolchains.
- Dependencies: Standards evolution (ISO 10218/TS 15066 extensions); validated force/torque sensing.
- ROS-native UVMC middleware and developer ecosystem
- Sector: Software, Education
- Use case: Open-source modules exposing UVMC encoders/decoders, token injectors, dataset balancers; course kits for universities.
- Tools/workflow: ROS packages; tutorials; simulated tasks with exportable UVMC traces.
- Dependencies: Community maintenance; compatible licenses; stable APIs.
Cross-cutting assumptions and dependencies (impacting feasibility across use cases)
- Safety and compliance: Collision avoidance, force/torque limits, geofencing, emergency stops, and human-in-the-loop oversight are essential for real deployments.
- Hardware and sensing: Multi-view RGB (or depth) with calibration; suitable end-effectors; reliable proprioception; sufficient edge compute for latency bounds.
- Data availability and governance: Access to mixed robot+human video datasets with legal consent; privacy-preserving pipelines; domain similarity to deployment tasks.
- Integration complexity: Mapping model actions to existing controllers (ROS/PLC), time synchronization of streams, and monitoring/telemetry infrastructure.
- Domain shift: Performance depends on overlap with pretraining distributions; extreme OOD conditions require additional fine-tuning or data augmentation.
- Compute/budget: Stage-1/2 training requires substantial compute; XR-1-Light reduces inference cost but may need careful task curation.
Glossary
- Action head: A model component that outputs low-level control commands from fused vision and language inputs. "extend VLMs with an action head that grounds perception and language into executable motor commands."
- Alignment loss: A regularizer that encourages embeddings from different modalities to be consistent. "while an alignment loss enforces consistent multimodal embeddings across embodiments via UVMC."
- Asymmetric VQ-VAE: A vector-quantized autoencoder whose encoder/decoder are architecturally different, here used for future-frame prediction. "we adopt an asymmetric VQ-VAE structure tailored for future-frame prediction."
- Autoregressive losses: Training objectives that predict each output conditioned on previous outputs. "which can be generative or autoregressive losses depending on the VLA model instance."
- Behavior cloning: Supervised imitation learning that maps observations (and instructions) to demonstrated actions. "trained exclusively with a standard behavior cloning objective in Stage-3"
- Bimanual collaboration: Coordinated manipulation using two robot arms simultaneously. "involving bimanual collaboration, dexterous manipulation, deformable objects, contact-rich interactions, dynamic settings, and long-horizon manipulation."
- Chain-of-Thought (CoT) reasoning: Step-by-step intermediate reasoning used to improve planning or problem solving. "CoT-VLA incorporates complex Chain-of-Thought (CoT) reasoning for planning"
- Codebook: The set of learned discrete embedding vectors used for vector quantization. "we build a shared learnable codebook"
- Commitment loss: A VQ-VAE term that encourages encoder outputs to stay close to their selected codebook entries. "our training loss combines reconstruction error, codebook learning loss, and commitment loss for each branch:"
- Contact-rich interactions: Tasks where sustained physical contact and force control are critical. "contact-rich interactions"
- Cross-data exploitation: Leveraging multiple heterogeneous datasets jointly for training. "cross-data exploitation leveraging web human videos and robotic datasets"
- Cross-embodiment: Spanning or transferring across different robot bodies or morphologies. "cross-embodiment control across diverse robot platforms."
- Cross-modal consistency: Agreement between representations derived from different modalities (e.g., vision and motion). "This regularization enforces cross-modal consistency while preserving modality-specific expressiveness."
- Cross-modality alignment: Learning to align features across distinct modalities into a unified space. "cross-modality alignment between vision and motion"
- Degrees of freedom (DoF): The number of independent actuated joints/axes a robot can control. "degrees of freedom (DoF)"
- Diffusion models: Generative models that learn to denoise data from noise in iterative steps. "utilizes diffusion models for diverse action generation."
- Discrete diffusion modeling: Diffusion modeling adapted to discrete latent or token spaces. "and discrete diffusion modeling to enable effective robot policy learning with limited labeled data."
- Discrete latent representation: A tokenized latent encoding drawn from a finite codebook rather than continuous vectors. "a discrete latent representation learned via a dual-branch VQ-VAE"
- Dual-branch VQ-VAE: A VQ-VAE with two encoders (e.g., vision and motion) that share a codebook to unify modalities. "learned via a dual-branch VQ-VAE that jointly encodes visual dynamics and robotic motion."
- Embodiment-agnostic: Independent of specific robot hardware, enabling broad transfer. "while maintaining embodiment-agnostic consistency."
- Future-frame prediction: Predicting a future image from a current image and a latent representing dynamics. "tailored for future-frame prediction."
- Heterogeneous data sources: Datasets differing in modality, embodiment, or labeling (e.g., human videos vs. robot logs). "across heterogeneous data sources, including diverse robot embodiments and human demonstrations."
- Kullback–Leibler divergence (KL divergence): A measure of difference between probability distributions, often used for alignment. "we employ a KullbackâLeibler divergence loss"
- Latent space: The internal representation space where inputs are encoded for downstream prediction or decoding. "into a shared discrete latent space."
- Learnable tokens: Trainable input tokens used to inject auxiliary information into a transformer/VLM. "We introduce learnable tokens \btokens in the VLM input to enable the VLM to predict the UVMC."
- Morphological heterogeneity: Differences in robot hardware and kinematics across embodiments. "morphological heterogeneity: robots differ in hardware configuration and degrees of freedom (DoF)"
- Proprioceptive states: Internal robot states such as joint positions and gripper status sensed by the robot itself. "and proprioceptive states (e.g., joint positions and gripper commands)."
- Quantization loss: The VQ-VAE term that pulls codebook entries toward encoder outputs during training. "the second term updates codebook embeddings towards encoder outputs (quantization loss)"
- Rollouts: Executed episodes of policy interaction used for evaluation or data collection. "with more than 14,000 rollouts"
- Stop-gradient operator: An operation that blocks gradients from flowing through a tensor during backpropagation. "where denotes the stop-gradient operator."
- Supramodal codes: Representations that fuse information across senses/modalities into a unified form. "humans naturally fuse heterogeneous sensory inputs into supramodal codes"
- Teleoperation: Human remote control of a robot to collect expert demonstrations. "collect expert demonstrations via teleoperation"
- Unified Vision-Motion Codes (UVMC): Discrete codes jointly capturing visual dynamics and robotic motion in one space. "Unified Vision-Motion Codes (UVMC), a discrete latent representation"
- Vector Quantized Variational Autoencoder (VQ-VAE): An autoencoder that quantizes latent vectors using a learned codebook. "Vector Quantized Variational Autoencoder (VQ-VAE)"
- Vision-Language-Action (VLA) models: Models that map vision and language to actions for robotic control. "Vision-Language-Action (VLA) models"
- Vision-LLMs (VLMs): Models trained on paired image-text data for multimodal understanding. "Vision-LLMs (VLMs)"
- Zero-shot cross-embodiment transfer: Deploying a policy on a new robot embodiment without additional training on that embodiment. "capable of zero-shot cross-embodiment transfer"
Collections
Sign up for free to add this paper to one or more collections.

