- The paper introduces a unified VLA model that interleaves vision, text, and action data for general robot control.
- It employs a hybrid decoding strategy combining autoregressive prediction and flow matching to improve both language and action outputs.
- Extensive benchmarks show superior performance in embodied reasoning, dexterous manipulation, and open-world generalization.
EmbodiedOneVision: Interleaved Vision-Text-Action Pretraining for General Robot Control
Introduction
EmbodiedOneVision introduces a unified Vision-Language-Action (VLA) model and a large-scale interleaved multimodal dataset for generalist robot control. The central innovation is the integration of interleaved vision, text, and action data into a single transformer-based architecture, enabling seamless embodied reasoning and dexterous manipulation across diverse real-world scenarios. The model is trained with a hybrid objective combining autoregressive next-token prediction for discrete modalities and flow-matching denoising for continuous robot actions, leveraging a curated dataset that emphasizes temporal and causal relationships among modalities.
Unified Model Architecture
The EmbodiedOneVision model adopts a single decoder-only transformer backbone initialized from Qwen2.5-VL, supporting both discrete (language) and continuous (action) outputs. All modalities—language instructions, image observations, robot state, and noisy actions—are encoded into an interleaved token sequence, processed by the shared transformer. Discrete language modeling is handled via a classic logits head, while continuous actions are generated using a flow-matching head, with actions denoised through forward Euler integration of the predicted vector field.
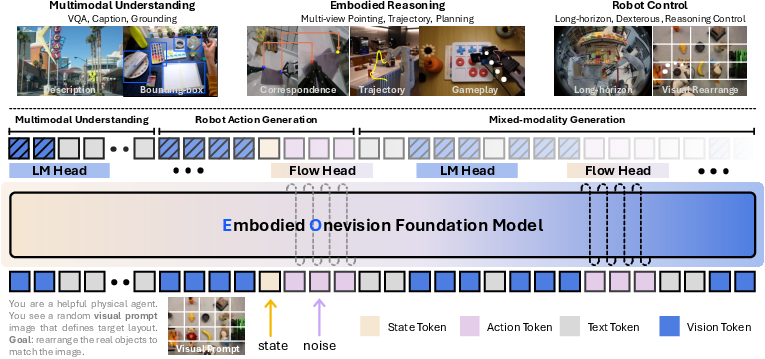
Figure 1: Model architecture showing unified transformer backbone with discrete language head and continuous flow-matching head for robot action generation.
This design circumvents the need for action-specific modules, facilitating direct cross-modal knowledge transfer and alignment. The architecture supports causal attention across the entire interleaved sequence, capturing dependencies between reasoning and acting, and enabling the model to alternate between multimodal reasoning and physical control.
Interleaved Data Construction and Sampling
A scalable data curation pipeline is employed to construct the EO-Robotics dataset, integrating web-based vision-language data with real robot episodes. Human annotators and VLMs generate diverse QA pairs for embodied temporal and spatial reasoning, including physical commonsense, task planning, object localization, affordance pointing, and multiview correspondence. These are concatenated with robot control actions in temporal order, forming interleaved vision-text-action sequences.
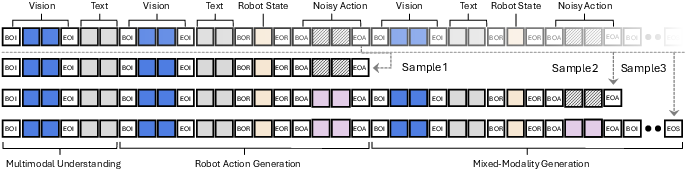
Figure 2: Interleaved rectifying sampling strategy for efficient mixed-modality training while preserving causal relationships.
To address the disruption of causal relationships during action denoising, a rectifying sampling strategy is introduced. Variable-length subsequences are sampled from action generation segments, with noisy action tokens replaced by clean ones in intermediate segments, ensuring proper gradient flow and causal alignment during training.
Dataset Composition and Benchmarking
The EO-Robotics dataset comprises over 1.5M interleaved samples, 1.2M robot control episodes, and 5.7M web multimodal samples, totaling 135B tokens. The interleaved data is annotated for both temporal and spatial reasoning, supporting fine-grained geometric and dynamic understanding.

Figure 3: Dataset statistics, curation pipeline, and interleaved data examples illustrating multimodal concatenation formats.
A comprehensive benchmark is constructed to evaluate embodied reasoning, covering spatial understanding, physical commonsense, task reasoning, and state estimation. Each QA instance targets a specific reasoning aspect, enabling interpretable and disentangled evaluation.

Figure 4: Benchmark examples including multiview pointing, physical commonsense, trajectory prediction, process verification, task planning, and affordance.
Training Paradigm
Training is performed on the full multimodal corpus for five epochs using Flash-Attention and variable-length packing. The model is optimized with a balanced loss between language regression and action flow matching. At inference, multi-view camera observations and sub-task instructions condition the policy, which predicts 16-step action chunks via 10 denoising iterations, supporting real-time deployment on a single RTX 4090 GPU.
Experimental Results
Embodied Reasoning
EmbodiedOneVision is evaluated on RoboVQA, ERQA, and the self-constructed benchmark, outperforming both open-source and closed-source VLMs and VLA models. On RoboVQA, it achieves a BLEU-4 score of 58.5, surpassing GPT-4o (47.2). On ERQA, it reaches 45.5 accuracy, exceeding InternVL2.5 8B (45.2). In the custom benchmark, it demonstrates strong spatial and temporal reasoning, with an overall score of 44.8.
Robot Control
On LIBERO, EmbodiedOneVision attains a 98.2% average success rate, outperforming OpenVLA-OFT, π0, and GR00T-N1 by 1.1–4.3%. On SimplerEnv, it achieves the highest success rates across all variants (WidowX: 72.7%, Google-VM: 76.5%, Google-VA: 63.0%), demonstrating robust generalization and data efficiency.
Real-World Manipulation
The model is tested on 28 real-world tasks across Franka Panda, WidowX 250 S, Agibot G-1, and Lerobot SO100, including pick-and-place, articulated manipulation, long-horizon dexterity, and embodied reasoning control.

Figure 5: Real-world evaluation tasks on diverse robots, illustrating long-horizon dexterity, pick-and-place, out-of-box, and embodied reasoning control.
EmbodiedOneVision consistently outperforms baselines, achieving 86.0% overall, 81.0% on long-horizon Agibot G-1 tasks, and 94.0% on Franka Panda pick-and-place. On reasoning-control tasks, it demonstrates superior integration of planning and execution, avoiding plan–act mismatches common in hierarchical pipelines.
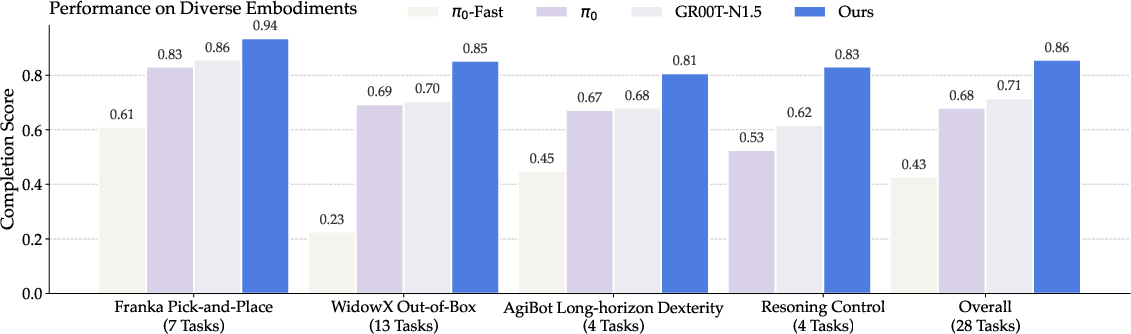
Figure 6: Performance comparison across robot platforms and task categories.

Figure 7: Long-horizon dexterity completion rate comparison on Agibot G-1.
Open-World Generalization
Generalization is assessed along visual, action, and language axes. EmbodiedOneVision achieves 73.0% overall, outperforming GR00T-N1.5 (60.0%) and π0 (51.0%). The largest gains are in language robustness, confirming the efficacy of interleaved training.

Figure 8: Instruction-following in open-world settings and success rates over 18 tasks.

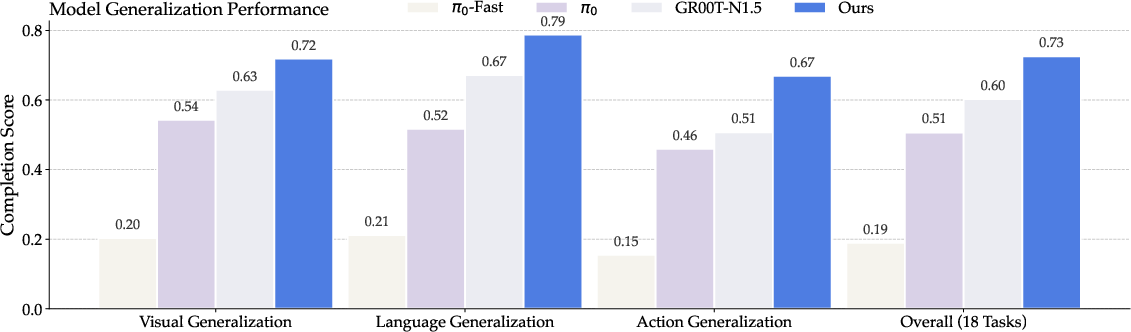
Figure 9: Generalization axes—visual, action, and language variations.
Unified Reasoning and Control
A reasoning-control benchmark evaluates the model's ability to integrate high-level reasoning with low-level control. EmbodiedOneVision outperforms hierarchical baselines on all tasks, with the largest margin in Tic-Tac-Toe (+40 points).

Figure 10: Qualitative rollouts for unified reasoning and control, showing perception, reasoning, and precise action execution.
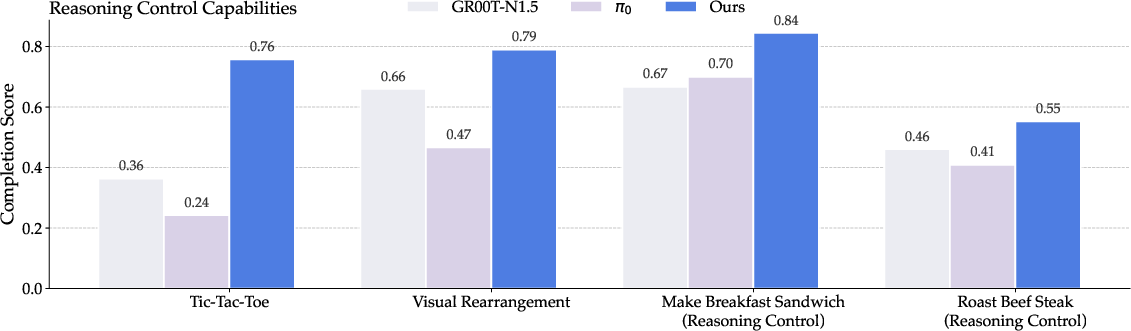
Figure 11: Success rates on the reasoning-control benchmark, with EmbodiedOneVision outperforming hierarchical baselines.
Ablation and Scaling Analysis
Hybrid decoding (autoregression + flow matching) consistently outperforms pure autoregression, especially in action and language generalization. Scaling interleaved data further boosts generalization, while generic instruction-following data can degrade physical grounding. The unified architecture enables stable, high-performance outcomes under distribution shift.
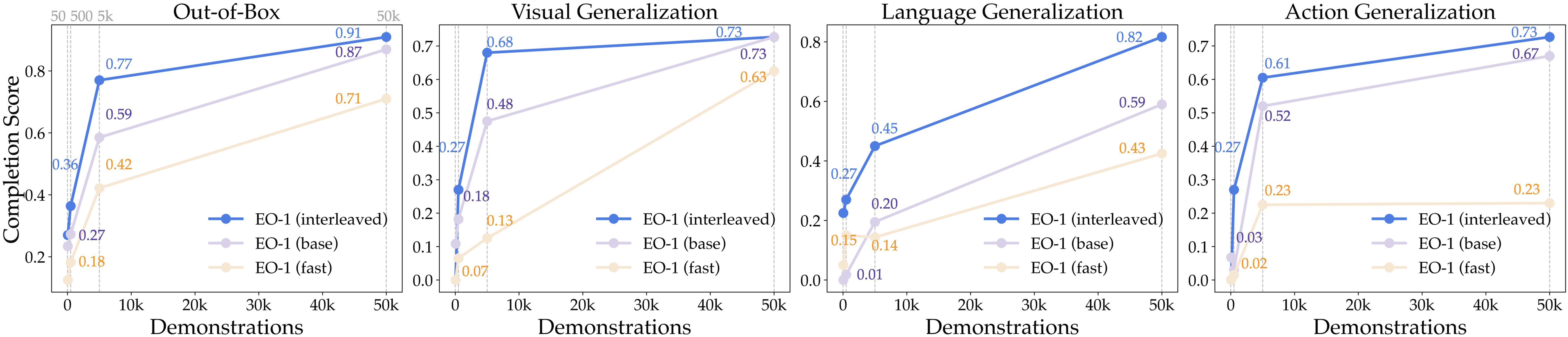
Figure 12: WidowX generalization performance across data scales for base, interleaved, and fast models.
Implementation Considerations
- Computational Requirements: Training requires high memory bandwidth and efficient attention mechanisms (Flash-Attention, DeepSpeed ZeRO-1). Inference is feasible on consumer-grade GPUs (RTX 4090, 6GB VRAM).
- Data Curation: Interleaved data construction is critical; annotation pipelines must ensure diversity and causal alignment.
- Deployment: The unified model supports real-time control and reasoning, suitable for both simulation and real-world robots.
- Limitations: Generalization to navigation, human-robot interaction, and failure analysis remains challenging; future work should expand data modalities and asynchronous reasoning-action pipelines.
Implications and Future Directions
EmbodiedOneVision demonstrates that unified, interleaved multimodal pretraining substantially improves open-world generalization, reasoning, and dexterous control in robotics. The approach sets a precedent for integrating perception, planning, and action in a single model, with strong empirical results across benchmarks and real-world tasks. Future research should focus on scaling to more complex scenarios, enhancing simultaneous reasoning and action, and incorporating broader data sources (e.g., human demonstrations, navigation tasks).
Conclusion
EmbodiedOneVision establishes a robust framework for generalist robot policies, leveraging interleaved vision-text-action pretraining and a unified transformer architecture. The model achieves state-of-the-art performance in embodied reasoning and manipulation, with strong generalization across modalities and environments. The open-source release of model weights, code, and dataset provides a valuable resource for advancing embodied AI and autonomous robotics.