Vision-Language-Action Models for Robotics: A Review Towards Real-World Applications
Abstract: Amid growing efforts to leverage advances in LLMs and vision-LLMs (VLMs) for robotics, Vision-Language-Action (VLA) models have recently gained significant attention. By unifying vision, language, and action data at scale, which have traditionally been studied separately, VLA models aim to learn policies that generalise across diverse tasks, objects, embodiments, and environments. This generalisation capability is expected to enable robots to solve novel downstream tasks with minimal or no additional task-specific data, facilitating more flexible and scalable real-world deployment. Unlike previous surveys that focus narrowly on action representations or high-level model architectures, this work offers a comprehensive, full-stack review, integrating both software and hardware components of VLA systems. In particular, this paper provides a systematic review of VLAs, covering their strategy and architectural transition, architectures and building blocks, modality-specific processing techniques, and learning paradigms. In addition, to support the deployment of VLAs in real-world robotic applications, we also review commonly used robot platforms, data collection strategies, publicly available datasets, data augmentation methods, and evaluation benchmarks. Throughout this comprehensive survey, this paper aims to offer practical guidance for the robotics community in applying VLAs to real-world robotic systems. All references categorized by training approach, evaluation method, modality, and dataset are available in the table on our project website: https://vla-survey.github.io .

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper is a big, friendly tour of a fast-growing idea in robotics: teaching robots to see, understand language, and act — all at the same time. These systems are called Vision-Language-Action (VLA) models. The authors explain how VLAs work, what kinds exist, how people train and test them, what robots and data they use, and what still needs to be solved to make robots useful in the real world.
Think of it like this: you show a robot a picture (vision), tell it what you want (language), and it figures out how to move its motors to do it (action). The paper surveys the whole field from top to bottom.
What questions does the paper ask?
The paper asks simple but important questions:
- How do we build robots that can look, listen (to instructions), and then act correctly?
- What designs and training tricks work best?
- What kinds of data do we need to teach these robots?
- How do we make one robot’s skills work on another robot with a different body?
- How do we test these systems fairly and run them efficiently in the real world?
The authors also set a clear rule for what counts as a VLA: the system must take in images and natural language and directly output robot control commands (not just pick from a list of pre-made skills).
How did they study it?
This is a review paper. That means the authors didn’t build one new robot model — they read, organized, and compared many existing papers, tools, datasets, and robot platforms. Then they grouped what they found into clear categories so you can see patterns and trends.
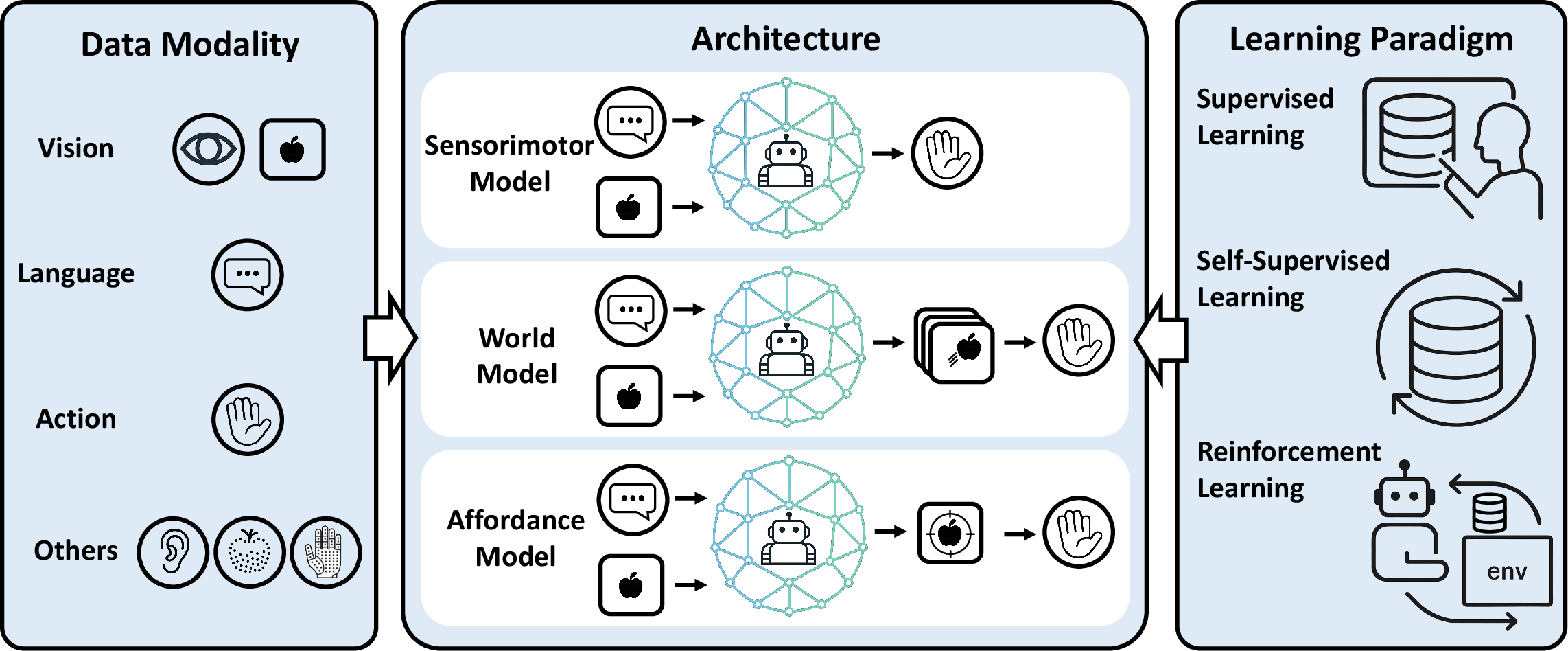
When they explain technical ideas, they use three main “model styles”:
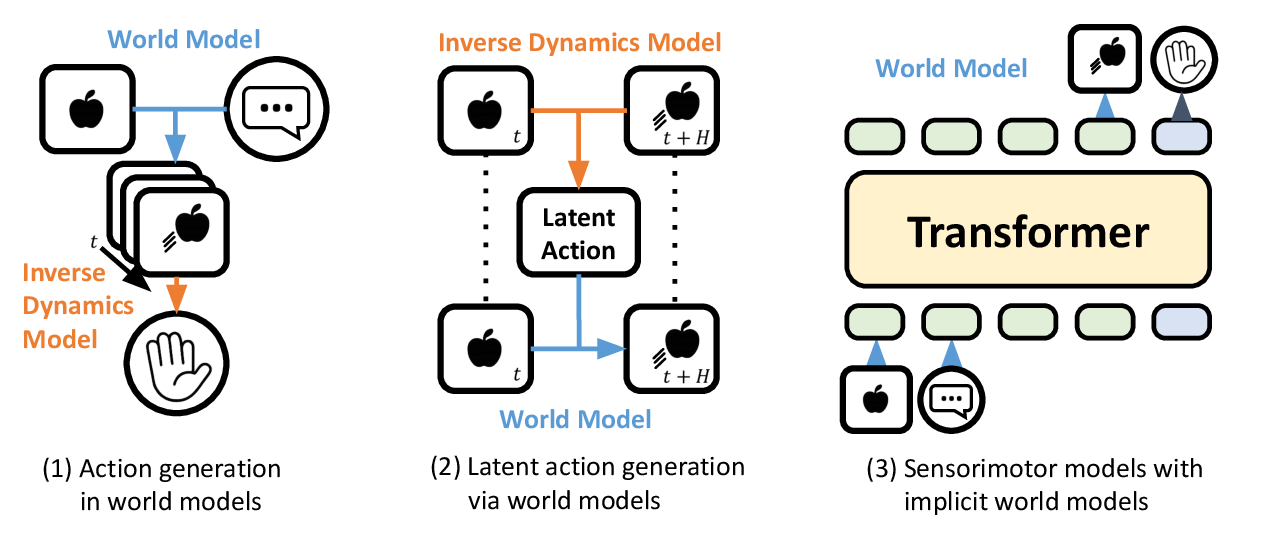
- Sensorimotor models: like a driver who looks at the road (vision), listens to directions (language), and directly turns the wheel and pedals (actions).
- World models: like planning ahead in your head — predicting what the world will look like next, then choosing actions based on that prediction.
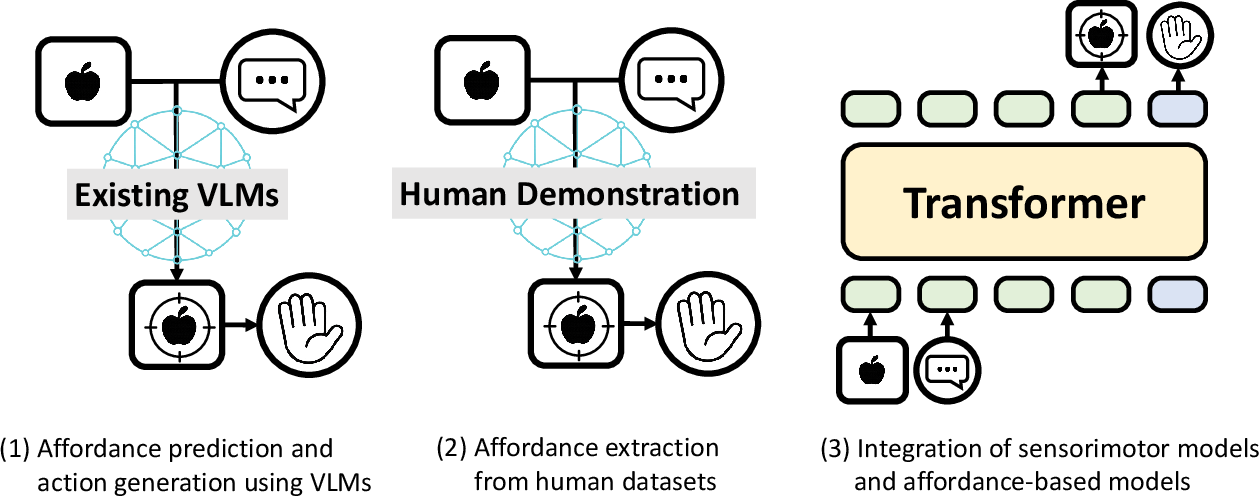
- Affordance-based models: like highlighting “where to grab” or “where to place” in the image first, then turning that into motor actions.
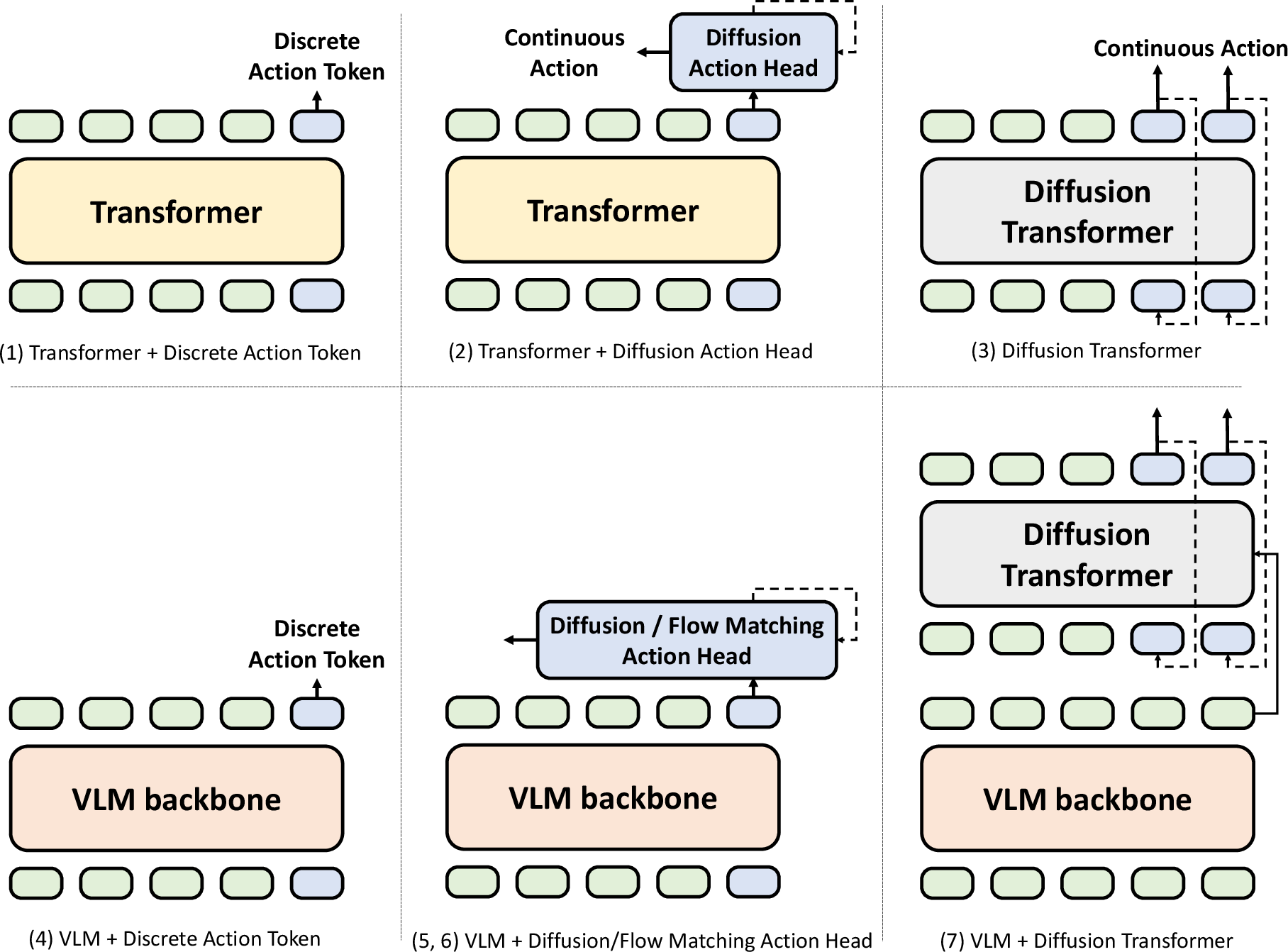
They also describe different action outputs:
- Discrete actions (like choosing from labeled buttons).
- Continuous actions (smooth motor commands), often made with “diffusion” or “flow matching” methods. You can think of diffusion like starting from a fuzzy guess and refining it step by step until it’s smooth and precise; flow matching aims to make that smoothing fast and stable, good for real-time control.
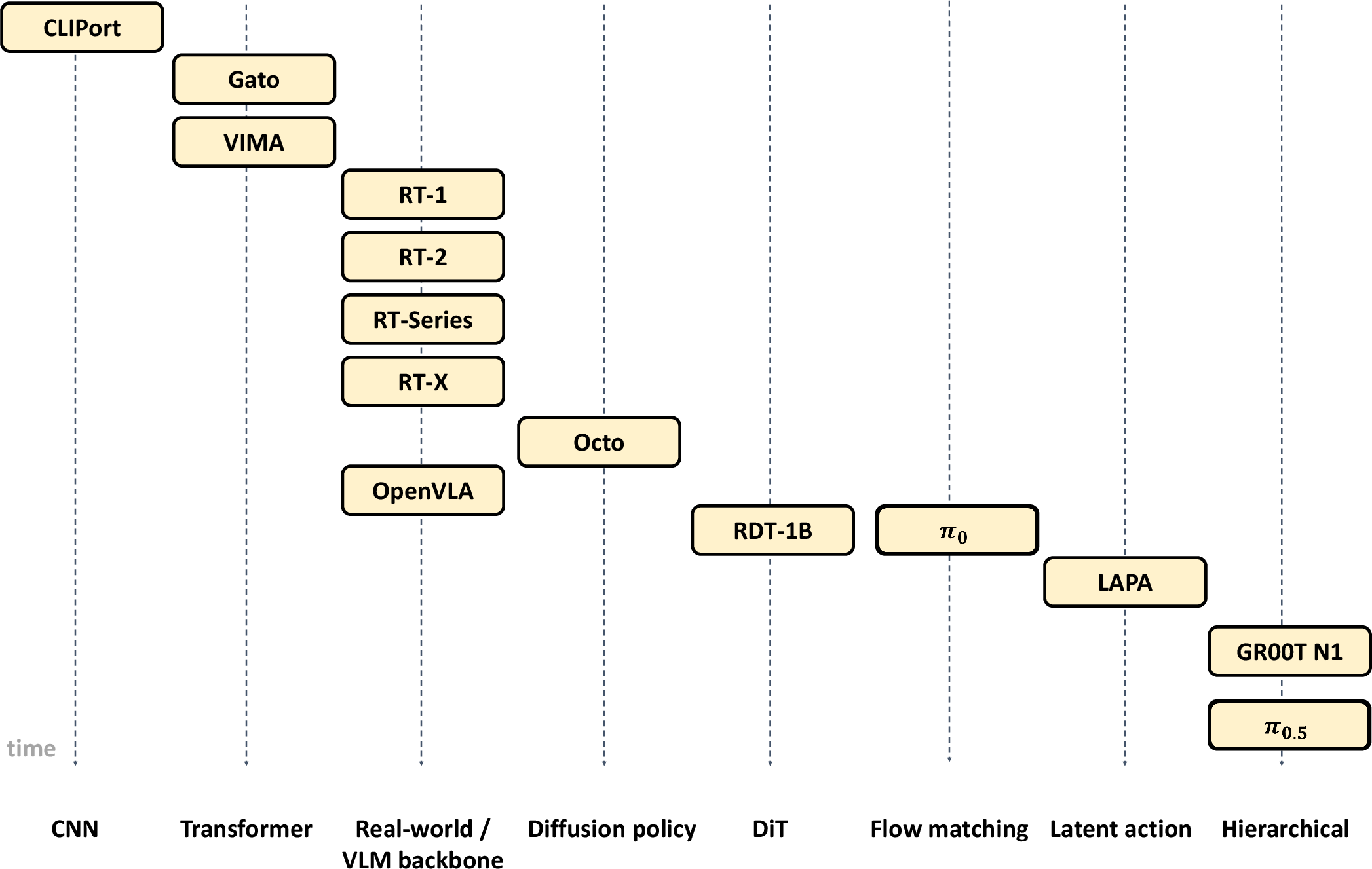
And they map out the “generations” of VLA designs:
- Early models used CNNs (a kind of image-processing network) and simple layers.
- Then came transformers (a flexible model that can pay attention to different parts of images and words).
- Next, vision-language backbones (very large models pre-trained on internet text and images) helped with common sense and generalization.
- Recently, diffusion and flow-matching models make actions smoother and more reliable.
- Newest are hierarchical models: a high-level “coach” plans steps and a low-level “player” executes smooth movements.
What did they find?
Here are the main takeaways, explained simply:
- Bigger, pre-trained vision-LLMs help a lot. Models like RT-2 and OpenVLA use large “foundation” models trained on internet-scale data. This gives robots better common sense and helps them understand new tasks with fewer examples.
- Smooth control matters. Diffusion and flow matching generate continuous, stable motor commands that look and feel more natural than picking from discrete action tokens. That’s important for tasks like pouring, grasping, or threading a needle.
- Hierarchical control works best for long, multi-step tasks. Think of a coach (high-level planner using language) guiding a player (low-level controller producing smooth motions). This combo makes robots better at complicated chores.
- Data is the biggest bottleneck. We have lots of images and text online, but fewer robot demonstrations that connect vision, language, and actions together. Collecting those demos is slow and expensive. Methods that learn from human videos (without detailed labels) and mix data from many robots can help.
- Transferring skills across different robot bodies is hard. A robot with wheels and a robot with legs need different commands. The paper highlights ways to bridge that gap, like learning “latent actions” from video that can be adapted to different machines.
- Compute costs are real. These models are big and can be slow, especially over long video clips or high-resolution images. That’s a challenge for running them onboard a robot. Efficient designs and model distillation (making smaller, faster versions) are key.
- The community is building the “full stack.” Beyond the models, the paper reviews robot platforms, data collection strategies, public datasets, data augmentation (creative ways to expand data), and evaluation benchmarks. It also shares practical advice for engineers bringing these systems into the real world.
Why does this matter?
If robots can reliably understand what we say, see the world around them, and act smoothly, they’ll be far more useful in homes, hospitals, warehouses, and disaster zones. The review shows that:
- Using large vision-language backbones speeds up progress and improves generalization.
- Hierarchical control makes long, tricky tasks possible.
- Learning from varied data — especially videos and many robot types — unlocks flexible skills.
- Making models efficient and standardized will help move from lab demos to dependable, everyday robots.
In short, this paper is a roadmap. It tells researchers and engineers which ideas are working now, where the pain points are (data, transfer, compute), and how to design the next generation of helpful, adaptable robots.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, actionable list of what remains missing, uncertain, or unexplored in the paper’s scope and the current VLA literature it surveys.
- Standardized VLA design practices: No consensus on backbone choice (VLM vs. transformer), multimodal fusion strategy (early/late/cross-attention), and action head (discrete tokens vs. autoregressive vs. diffusion vs. flow matching). Controlled, cross-dataset ablations are needed to establish best practices.
- Triple-aligned datasets at scale: A shortage of large, diverse datasets that tightly align vision, language, and action with rich linguistic variability and fine-grained motor grounding. Methods to automatically derive action labels from web videos and to align them with textual instructions remain underdeveloped.
- Cross-embodiment generalization: Lacking principled representations for morphology, kinematics, and proprioception that enable policies to transfer across robots with different DOFs and action spaces. Clear protocols and metrics for evaluating embodiment transfer are missing.
- Human-to-robot action mapping: Robust pipelines to convert human demonstrations (often without explicit actions) into robot-executable control sequences are nascent. Open questions include how to learn latent action spaces, retarget 3D poses, and preserve semantics under constraints.
- Goal specification choices: The field lacks comparative evaluations of text-only vs. text+goal image vs. sketch vs. trajectory inputs, including when each is preferable and how to combine them for long-horizon or contact-rich tasks.
- Action representation trade-offs: Concrete guidance is absent on discretization granularity, token schemas (e.g., FAST), and conversion to continuous control—especially regarding latency, smoothness, accuracy, and safety under different heads (MLP, diffusion, flow matching).
- Temporal and memory efficiency: Scalable methods for long-sequence modeling (e.g., streaming attention, memory modules, token compression) and their effect on closed-loop latency and performance on resource-constrained robots are not well characterized.
- Beyond vision and language: Systematic integration of depth, 3D point clouds, tactile, audio, and force/torque sensing is underexplored. Data collection, encoders, and training objectives to exploit these modalities for action grounding need development.
- Self-supervised motor pretraining: Approaches like latent action learning (e.g., from unlabeled video) require broader evaluation across tasks and embodiments, including data requirements, failure modes, and how to best couple with supervised fine-tuning.
- World models and affordance-based control: The survey references these architectures but lacks systematic comparisons to sensorimotor models. When does predictive modeling (future frames/affordances) improve control, and what losses/training regimes are most effective?
- Hierarchical policies: Open issues include how to represent intermediate plans (e.g., “language motion”), credit assignment across levels, switching criteria, stability under error compounding, and training schedules for end-to-end vs. modular learning.
- Evaluation standards: No unified, widely adopted benchmark suite captures generalization across tasks, objects, embodiments, and environments; long-horizon performance; contact-rich manipulation; and safety/failure rates. Reproducible protocols and reporting standards are needed.
- Safety and reliability: Little guidance exists on uncertainty estimation, confidence-aware action selection, constraint satisfaction, recovery strategies, and formal verification. Standard safety layers and fail-safe mechanisms for VLA control remain open.
- Continual learning and adaptation: Methods for on-robot learning, few-shot adaptation, combining IL and RL, preventing catastrophic forgetting, and robust test-time adaptation are under-specified and need empirical validation.
- Data augmentation for action grounding: The effectiveness of physics-aware augmentation, multimodal perturbations (vision/language/tactile), and paraphrasing on downstream control is not quantified, especially their impact on real-world transfer.
- Compute and deployment efficiency: Practical recipes for distillation, quantization, pruning, and hardware acceleration (GPU/TPU/edge) that preserve control fidelity at real-time rates (e.g., 50 Hz) on embedded platforms are missing.
- Tokenization and fusion mechanics: The role of readout tokens, learned modality tokens, and alternating condition injection is not systematically dissected; guidelines are needed for token budgets, positional encodings, and attention patterns.
- Robust language grounding: Best practices for prompt design, multilingual support, instruction noise handling, and context window management in VLM-backed policies are not established, especially under real-time constraints.
- Sim2real at scale: Scalable pipelines that bridge simulation diversity to real-world control (including domain randomization tailored to actions, not just perception) require clearer evidence and tooling.
- Open-source and reproducibility: Many leading systems lack fully open data/code/training details and permissive licenses, hindering cross-lab comparisons and cumulative progress. Community standards for releases and documentation are needed.
- Real-world operations: Guidance on deployment logistics—telemetry, calibration drift handling, reset strategies, integration with navigation/perception stacks, and maintenance—remains sparse despite being critical for sustained field use.
- Sample efficiency metrics: Standardized measures and learning curves to compare how many demonstrations are needed per task/embodiment (and under which augmentations or pretraining) are not yet established.
Glossary
- Action expert: A specialized action-output module that maps multimodal context (vision, language, proprioception) to control trajectories. "the action expert, which enables a multimodal model to handle both discrete and continuous data."
- Action tokenization: Representing continuous control or trajectories as discrete tokens for sequence modeling. "have focused primarily on either action tokenization or general architectural advancements"
- Affordance-based models: Methods that first predict action-relevant affordances from vision and language and then derive control actions from them. "Affordance-based models are another variant that predict action-relevant visual affordances based on language, and then generate actions accordingly."
- Alternating Condition Injection: A conditioning strategy that alternates image and text tokens as queries across transformer layers to improve multimodal conditioning and reduce overfitting. "Alternating Condition Injection is proposed, in which image and text tokens are alternately used as queries at each transformer layer."
- Autoregressively: Generating outputs step-by-step, each conditioned on previously generated tokens. "A decoder-only transformer is then used to autoregressively generate actions"
- Binned values: Discretized numeric ranges used to represent continuous quantities like actions. "output discretized actions such as binned values."
- Causal temporal transformer: A temporal transformer that enforces causal ordering so only past information influences future predictions. "a causal temporal transformer"
- Cross-attention: An attention mechanism that conditions one token sequence on another (e.g., actions on vision/language tokens). "via cross-attention with a vision and language query"
- Cross-embodiment generalization: The ability of a policy to transfer across robots with different bodies, sensors, and action spaces. "cross-embodiment generalization?"
- Decoder-only transformer: A transformer architecture using only the decoder stack for autoregressive prediction. "A decoder-only transformer is then used"
- Diffusion action head: An action-generation module that uses denoising diffusion to produce smooth, continuous control. "then applies a diffusion action head conditioned on the readout token."
- Diffusion Policy: A policy class that models action trajectories via denoising diffusion processes. "is the first VLA to leverage Diffusion Policy"
- Diffusion Transformer (DiT): A transformer backbone that integrates diffusion directly into the network for generative prediction. "employs a Diffusion Transformer (DiT) as its backbone"
- Embodiment Transfer: Transferring learned skills or policies between robots with different embodiments. "Embodiment Transfer"
- End-to-end framework: Training that maps inputs (vision, language) directly to actions without hand-crafted intermediate stages. "in an end-to-end framework"
- FiLM conditioning: Feature-wise Linear Modulation to inject conditioning signals (e.g., language) into visual features. "performs FiLM conditioning"
- Flow matching: A generative modeling technique that learns continuous-time flows for fast, parallel sampling of actions. "flow-matching"
- Hierarchical policy architectures: Multi-level policies separating high-level planning from low-level control. "Hierarchical policy architectures."
- Hierarchical policy structure: A two-level control design with high-level intermediate plans and low-level action execution. "hierarchical policy structure."
- Imitation learning: Learning control policies by mimicking expert demonstrations. "policies learned through imitation learning"
- In-context learning: Leveraging prompts or context at inference time to adapt behavior without parameter updates. "in-context learning capabilities."
- Language motion: An intermediate, language-expressed representation of planned motion used by a high-level controller. "known as language motion,"
- Latent actions: Compact, learned action representations inferred from video that can guide control. "learn latent actions for use in VLA models."
- Latent Quantization Network: A model that quantizes latent temporal changes (e.g., via VQ-VAE) to discrete action-like tokens. "forming a Latent Quantization Network."
- Mask R-CNN: A deep model for instance segmentation and object detection used to extract object-centric tokens. "Mask R-CNN"
- Multi-Layer Perceptron (MLP): A feedforward neural network used for embedding or mapping features to actions. "multilayer perceptron (MLP)"
- Nonautoregressively: Generating multiple outputs in parallel rather than sequentially token-by-token. "predict all action tokens non-autoregressively"
- Proprioception: Internal sensing of a robot’s state (e.g., joint positions/velocities) used as input to policies. "proprioceptive input from the robot"
- Readout token: A special token that aggregates sequence information and conditions downstream action heads. "conditioned on the readout token."
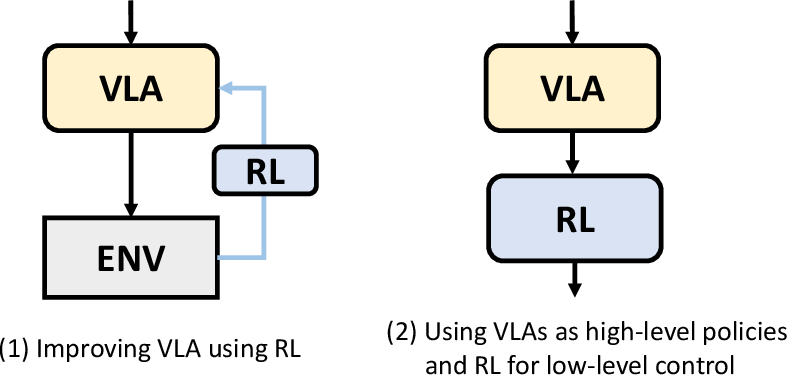
- Reinforcement learning: Learning policies by maximizing cumulative reward through trial-and-error interaction. "reinforcement learning"
- Sensorimotor model: A model that directly maps sensory inputs (vision, language) to motor actions. "Architecture of sensorimotor models for VLA."
- SentencePiece: A subword tokenizer used to convert text into tokens for transformers. "SentencePiece"
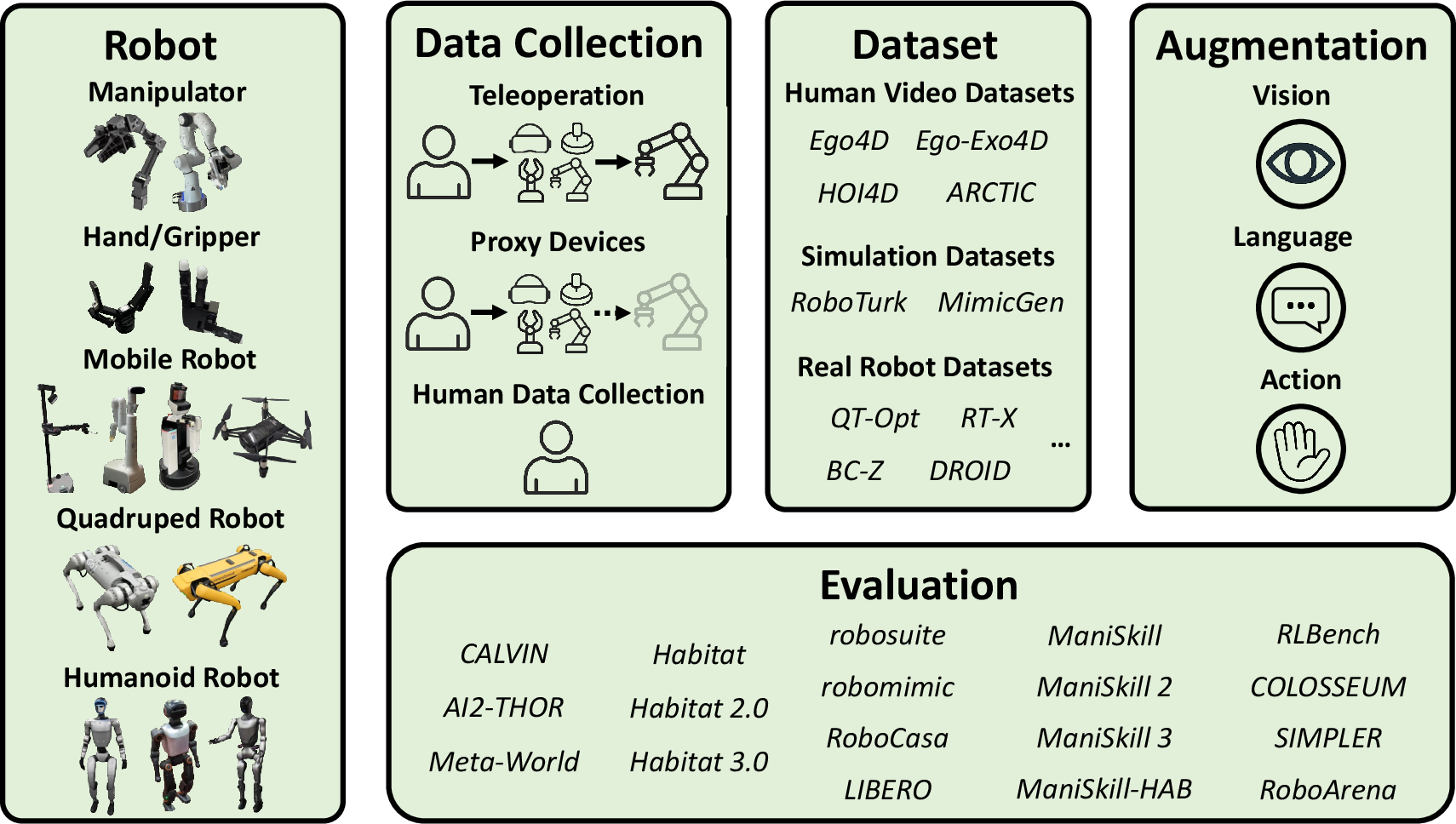
- Teleoperation: Human remote control of a robot to collect expert demonstration data. "often collected via teleoperation"
- TokenLearner: A module that adaptively selects a smaller set of informative visual tokens for efficient processing. "TokenLearner"
- Transporter Network: An architecture for object manipulation that learns where to pick and where to place. "the Transporter Network"
- Vision-Language-Action (VLA) model: A model that takes vision and language as required inputs and directly outputs robot actions. "Vision-Language-Action (VLA) Model"
- Vision-LLM (VLM): A model pre-trained to align vision and language, often used as a backbone in robotics. "Vision-LLM (VLM)"
- Vision Transformer (ViT): A transformer architecture that processes images as sequences of patches. "Vision Transformer (ViT)"
- VQ-VAE: Vector-Quantized Variational Autoencoder used to discretize latent representations. "VQ-VAE"
- World models: Models that predict future observations (e.g., video) conditioned on language to guide control. "World models predict the future evolution of sensory modalities"
Practical Applications
Immediate Applications
The following applications can be deployed today by leveraging the survey’s consolidated guidance on architectures (e.g., VLM backbones, diffusion/flow-matching heads, hierarchical policies), datasets (e.g., Open-X Embodiment), and engineering practices (data collection, augmentation, evaluation).
- Language-driven pick-and-place, sorting, and kitting on mobile manipulators
- Sectors: Logistics, Manufacturing, Retail
- Tools/Workflows: VLM + discrete action policies (e.g., RT-2/OpenVLA-style), transformer + diffusion heads (Octo-style) for smooth grasping; standardized data collection from teleoperation; tokenization of actions for reliability; evaluation via common manipulation benchmarks
- Assumptions/Dependencies: Moderate visual variability; accessible robot arms/grippers; sufficient in-domain demonstrations; safety cages or collaborative robot compliance
- Long-horizon office/hospital fetch-and-deliver
- Sectors: Healthcare (non-clinical), Facilities, Corporate IT
- Tools/Workflows: Hierarchical VLA (high-level instruction parsing + low-level control, e.g., RT-H-style); waypoint or subtask prompting; routine tasks like “bring sanitizer from storage,” “deliver documents to room 204”
- Assumptions/Dependencies: Clear navigation stack integration; mapped environments; human-in-the-loop override; institutional safety protocols
- Reconfigurable warehouse workflows via natural language prompts
- Sectors: Logistics, E-commerce Fulfillment
- Tools/Workflows: VLM backbones for promptable policies; skill adaptation by fine-tuning on small in-house datasets; discrete action token interfaces for rapid reprogramming of stations (e.g., retarget “place items to bin C”)
- Assumptions/Dependencies: Stable lighting and fixtures; SKU-level visual grounding; robust bin localization; role-based access controls for prompting
- Assembly assistance and part handling for low-precision sub-tasks
- Sectors: Light Manufacturing, Electronics Kitting
- Tools/Workflows: Diffusion or flow-matching action heads for continuous trajectories; language-anchored affordance prediction (“insert cable into left port”); time-chunked action decoding to reduce latency
- Assumptions/Dependencies: Fixtures and jigs to constrain tolerances; QA checks; limited force/precision requirements
- Cleaning and tidying in semi-structured environments
- Sectors: Hospitality, Facilities, Labs
- Tools/Workflows: Sensorimotor models trained on wiping, organizing, opening/closing drawers; hierarchical policies that split “what to clean” vs. “how to wipe”
- Assumptions/Dependencies: Non-hazardous cleaning agents; conservative force limits; environment roll-outs for training
- Language-guided lab logistics (moving racks, replenishing consumables, equipment staging)
- Sectors: Research Labs, Biotech R&D
- Tools/Workflows: VLM + diffusion head for delicate grasping; few-shot fine-tuning on labware; structured prompts (“place 8-tip rack on deck position B2”)
- Assumptions/Dependencies: Sterility and contamination protocols; restricted contact with samples; compatible end-effectors
- Assisted teleoperation with policy auto-completion
- Sectors: Field Service, Inspection, Construction
- Tools/Workflows: Diffusion/flow-matching policies to smooth operator inputs; instruction-grounded intent inference; latency-aware decoding on edge GPUs
- Assumptions/Dependencies: Reliable comms; safety interlocks; well-calibrated kinematics
- Cross-embodiment transfer for new robot arms/grippers via pretraining
- Sectors: Robotics OEMs, System Integrators
- Tools/Workflows: Pretrain on multi-robot datasets (e.g., Open-X Embodiment), then fine-tune per site; morphology-aware action spaces; shared tokenization schemas across fleets
- Assumptions/Dependencies: Availability of cross-robot data; standardized proprioceptive streams; calibration procedures
- On-the-fly task personalization through language
- Sectors: Enterprise Services, Facilities
- Tools/Workflows: Prompt engineering pipelines for parameterizing skills (speed, force, placement offset); constraint prompts (“avoid red zones”); logging prompts + outcomes for A/B evaluation
- Assumptions/Dependencies: Prompt governance; user access policies; traceable versioning of prompts and behaviors
- Data operations for VLA training-in-the-loop
- Sectors: Academia, Robotics Startups, Industrial R&D
- Tools/Workflows: Survey-recommended pipelines for teleop collection, video-language alignment, action discretization, augmentation, and evaluation; reproducible benchmarks and ablations
- Assumptions/Dependencies: Storage/compute budgets; data licensing; annotation QA
- Edge deployment of compact VLAs for constrained tasks
- Sectors: OEMs, SMEs with limited compute
- Tools/Workflows: Model distillation/LoRA fine-tuning; token compression (e.g., TokenLearner-like); low-res visual encoders; action chunking to reduce decoding overhead
- Assumptions/Dependencies: Target FPS/latency budgets; thermal/power limits; acceptable performance trade-offs
- Safety-aligned evaluation and rollout procedures
- Sectors: All adopting sectors
- Tools/Workflows: Use of survey’s evaluation benchmarks; red-teaming for long-horizon failures; curriculum-based validation (from tabletop to in-situ)
- Assumptions/Dependencies: Cross-functional safety review; incident reporting; rollback mechanisms
Long-Term Applications
These applications rely on maturing trends outlined in the survey (latent action learning from video, cross-embodiment generalization, hierarchical control at scale, efficient inference) and will require further research, scaling, or policy development before broad deployment.
- Generalist home robots for open-ended chores
- Sectors: Consumer Robotics
- Tools/Workflows: Hierarchical VLA (task decomposition + low-level control), large-scale household demonstrations, robust affordance grounding
- Assumptions/Dependencies: Significant advances in robustness, safety, and multi-modal sensing (depth/tactile); extensive in-home datasets; reliable failure recovery
- Video-to-robot learning from web-scale unlabeled data
- Sectors: Cross-sector (skills from human videos)
- Tools/Workflows: Latent action pretraining (e.g., LAPA-style) to extract transferable “action tokens” from human videos; minimal robot datapaths for adaptation
- Assumptions/Dependencies: Robust embodiment mapping; legal/ethical use of web video; domain adaptation to robot kinematics
- Universal cross-embodiment policies across arms, mobile bases, and hands
- Sectors: Robotics OEMs, Integrators
- Tools/Workflows: Morphology-aware encoders; shared action token ontologies; fleet-wide policy training and validation
- Assumptions/Dependencies: Very large, diverse multi-robot datasets; standardized telemetry; cross-site MLOps
- Safety-critical manipulation in healthcare and eldercare
- Sectors: Healthcare, Assisted Living
- Tools/Workflows: Verified hierarchical controllers; formal safety envelopes; multi-modal sensing (tactile, force, audio) for contact-rich tasks (e.g., dressing assistance)
- Assumptions/Dependencies: Regulatory certification; clinical trials; liability frameworks
- Precision assembly and compliant manipulation with foundation VLAs
- Sectors: Advanced Manufacturing, Electronics
- Tools/Workflows: VLM + diffusion transformer or flow matching with high-frequency control; tactile + force integration; fine-grained affordances
- Assumptions/Dependencies: High-fidelity sensors; closed-loop compliance; stringent QA benchmarks
- Agricultural picking and handling of delicate produce
- Sectors: Agriculture
- Tools/Workflows: Language-anchored affordances for ripeness/defect cues; 3D perception and tactile feedback; long-horizon task decomposition (navigate–pick–place)
- Assumptions/Dependencies: Robust outdoor perception; crop-specific datasets; seasonal adaptation
- Autonomous facility operations (multi-task orchestration at building scale)
- Sectors: Facilities, Hospitality, Smart Buildings
- Tools/Workflows: Multi-robot hierarchical policies; task marketplace and scheduling; cross-robot skill sharing via standardized action tokens
- Assumptions/Dependencies: Reliable indoor localization; fleet coordination; networked safety governance
- On-device VLA inference at scale
- Sectors: OEMs, Consumer Robotics
- Tools/Workflows: Model compression, sparsity, low-bit quantization; efficient attention for long sequences; action chunk decoding
- Assumptions/Dependencies: Hardware co-design; performance–energy trade-offs; real-time guarantees
- Auditable, standards-based evaluation and certification of VLA robots
- Sectors: Policy/Regulation, Insurance
- Tools/Workflows: Standardized datasets/benchmarks for long-horizon safety; incident taxonomy and reporting; third-party certification labs for VLAs
- Assumptions/Dependencies: Multi-stakeholder standards bodies; harmonized regulations; access to representative evaluation environments
- Open skill catalogs and “app store” for robot capabilities
- Sectors: Robotics Ecosystem, Integrators
- Tools/Workflows: Interoperable discrete action token schemas (e.g., FAST-like), skill packaging with prompts and safety envelopes; provenance and versioning
- Assumptions/Dependencies: IP/licensing norms; compatibility across VLA stacks; sandboxed testing
- Multi-modal VLAs with tactile, audio, and 3D point clouds for dexterous tasks
- Sectors: Robotics, Manufacturing, Labs
- Tools/Workflows: Multi-sensor fusion backbones; modality-specific augmentation; contact-rich policy learning
- Assumptions/Dependencies: Sensor availability/cost; synchronization; increased compute and data needs
- Continual and federated learning across robot fleets
- Sectors: Logistics, Facilities, Retail
- Tools/Workflows: Privacy-preserving data aggregation; fleet-scale evaluation; automatic skill updates with rollback
- Assumptions/Dependencies: Data governance; bandwidth; robust drift detection and safety gating
Note: Across both categories, feasibility hinges on factors emphasized in the survey: availability of aligned vision–language–action data, cross-embodiment transfer methods, compute/latency constraints for training and inference, robust evaluation protocols, and adherence to safety and regulatory requirements.
Collections
Sign up for free to add this paper to one or more collections.