- The paper introduces a fully automated pipeline to convert unscripted human videos into structured VLA episodes for robotic manipulation.
- It employs state-of-the-art 3D motion labeling, atomic action segmentation, and GPT-4.1-based instruction labeling for precise temporal and semantic alignment.
- Experimental results show strong zero-shot performance and enhanced generalization on unseen objects and diverse environments.
Scalable Vision-Language-Action Model Pretraining for Robotic Manipulation with Real-Life Human Activity Videos
Introduction and Motivation
This work addresses the challenge of pretraining Vision-Language-Action (VLA) models for dexterous robotic manipulation by leveraging large-scale, unscripted real-life human activity videos. The scarcity and limited diversity of existing robotic VLA datasets, especially for dexterous hand actions, restricts the generalization capabilities of current models. The authors propose a fully automated pipeline that transforms unstructured egocentric human videos into structured VLA episodes, aligning them with the format and granularity of robotic data. This approach enables scalable pretraining, facilitating robust zero-shot generalization and efficient fine-tuning for real-world robotic tasks.

Figure 1: Pretraining VLA models by converting unstructured human activity videos into structured V-L-A formats, enabling strong zero-shot hand action prediction and robust generalization after fine-tuning.
Holistic Human Activity Analysis Pipeline
The data construction pipeline consists of three stages:
- 3D Motion Labeling: Monocular 3D hand and camera pose estimation is performed using state-of-the-art deep visual SLAM and hand reconstruction methods. Camera intrinsics are estimated and images are undistorted to conform to the pinhole model. HaWoR is used for hand pose reconstruction, and MegaSAM (with MoGe-2 depth priors) for metric-scale camera pose tracking. Spline smoothing and outlier removal are applied to the reconstructed trajectories.
- Atomic Action Segmentation: Videos are segmented into atomic-level action clips by detecting speed minima in the 3D hand wrist trajectories. This unsupervised approach exploits natural action transitions and is highly efficient, requiring no additional model inference or annotation.
- Instruction Labeling: For each segment, sampled frames are overlaid with hand trajectories and fed to GPT-4.1 for imperative action captioning. Clips without meaningful actions are labeled as "N/A". This process ensures precise temporal and semantic alignment between actions and instructions.
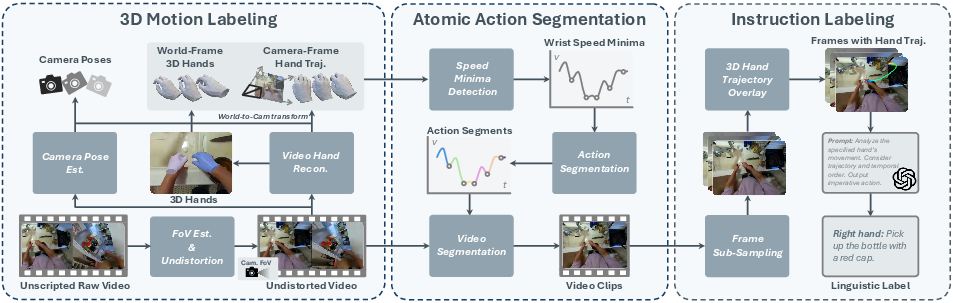
Figure 2: The three-stage pipeline: (a) 3D motion labeling, (b) atomic action segmentation, and (c) instruction labeling, converting unscripted human videos into V-L-A episodes aligned with robotic data.
The resulting dataset comprises 1M episodes and 26M frames, sourced from diverse egocentric video datasets (Ego4D, Epic-Kitchen, EgoExo4D, SSV2), and covers a broad spectrum of objects, environments, and manipulation skills.
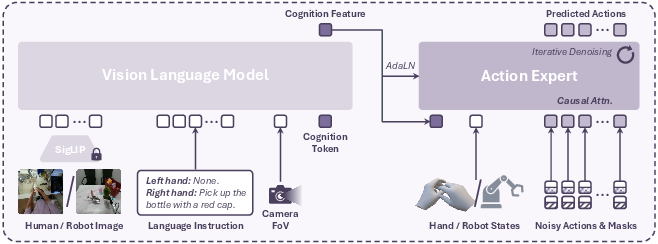
Model Architecture
The proposed VLA model consists of a Vision-LLM (VLM) backbone and a diffusion-based action expert:
Pretraining and Fine-Tuning Strategies
- Pretraining: The model is trained on the constructed human hand VLA dataset with trajectory-aware augmentation (random cropping, perspective warping, flipping, color jittering), ensuring hand trajectories remain visible and instructions consistent. State and cognition token dropout are used for classifier-free guidance.
- Fine-Tuning: For deployment, the model is fine-tuned on a small set of real robot trajectories. Robot hand actions are mapped to the human hand action space, with joint correspondence established via topology matching. Direct future execution commands are supervised for plausible hand-object interactions.
Data Diversity and Scaling Analysis
The dataset exhibits superior visual and instruction diversity compared to existing VLA datasets (EgoDex, OXE, DROID, AgiBot World). Diversity is quantified via DINOv2 feature similarity to OpenImages and word frequency analysis (nouns, verbs, adjectives) in instructions. The scaling behavior is favorable: increasing data scale yields approximately linear improvements in hand action prediction and downstream robot task success rates.
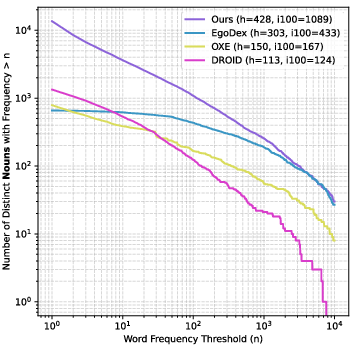
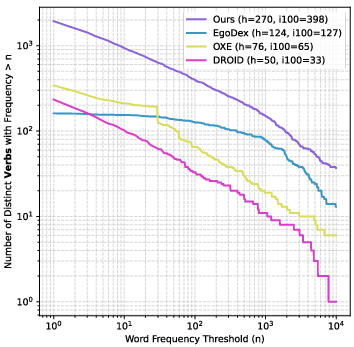
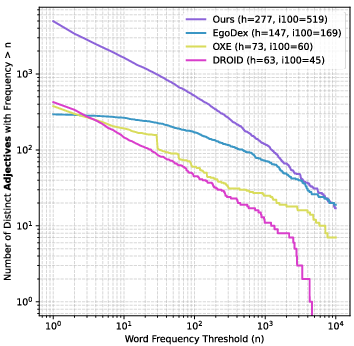
Figure 4: Distribution of nouns in language instructions across VLA datasets, demonstrating high diversity in the proposed dataset.


Figure 5: Distribution of verbs in language instructions, indicating broad coverage of manipulation actions.
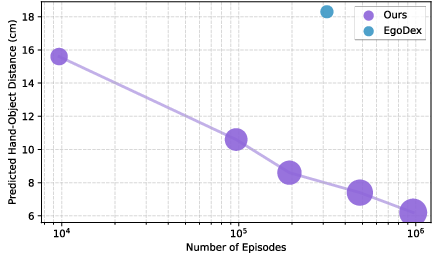
Figure 6: Data scaling behavior on the grasping task; larger circle size indicates greater visual diversity.
Experimental Results
Human Hand Action Prediction
Zero-shot hand action prediction is evaluated on unseen environments for grasping and general actions. Quantitative metrics (hand-object distance) and user studies (plausibility ranking) demonstrate that the proposed model outperforms baselines trained on lab data, human annotations, and concurrent works (e.g., Being-H0). Ablations confirm the importance of trajectory-aware augmentation, causal attention, and 3D trajectory-guided episode construction.

Figure 7: Predicted hand grasping trajectories in unseen real-world environments, showing robust generalization.

Figure 8: Predicted general hand actions in novel environments, illustrating diverse and plausible motion generation.
Real-World Robotic Manipulation
Fine-tuned models are evaluated on a Realman robot with XHand dexterous hands across four tasks: pick-and-place, functional grasping, pouring, and sweeping. Both seen and unseen objects/backgrounds are tested. The proposed approach achieves significantly higher success rates than prior art (VPP, π0), OXE pretraining, and latent action pretraining, especially in unseen scenarios. Data diversity and explicit 3D action supervision are critical for generalization.

Figure 9: In-domain execution trajectories for pick-and-place and functional grasping tasks, captured by the robot head camera.

Figure 10: Execution trajectories in environments with unseen objects and backgrounds, demonstrating strong generalization.

Figure 11: Sequential task execution (sweeping, pouring, bimanual handover), illustrating the model's capability for long-horizon and bimanual manipulation.
Implementation Considerations
- Computational Requirements: Pretraining requires 2 days on 8 H100 GPUs; fine-tuning takes 8 hours on the same hardware. Inference is efficient, with DDIM sampling and action chunking for real-time execution.
- Limitations: Some inaccuracies remain due to imperfect 3D reconstruction and VLM capabilities. The current framework targets short-horizon atomic skills; extension to long-horizon planning and multi-modal (e.g., tactile) inputs is a future direction.
- Deployment: The pipeline is fully automated and scalable, enabling rapid expansion with additional video sources. The model and dataset will be open-sourced for community use.
Implications and Future Directions
This work demonstrates that large-scale, unstructured human activity videos can be transformed into high-quality VLA data for scalable pretraining, substantially improving zero-shot generalization and few-shot adaptation in dexterous robotic manipulation. The approach is tractable for further scaling, with no technical barriers to incorporating more diverse video sources. Future research should focus on improving 3D reconstruction accuracy, filtering noisy samples, organizing data for long-horizon reasoning, and integrating multi-modal sensory inputs.
Conclusion
The proposed framework establishes a scalable paradigm for VLA model pretraining using real-life human activity videos. By aligning unstructured human demonstrations with robotic data formats and leveraging explicit 3D action supervision, the approach achieves strong zero-shot performance, efficient fine-tuning, and robust generalization to novel objects and environments. This work lays a foundation for generalizable embodied intelligence in robotics, with significant implications for data-driven skill acquisition and deployment in real-world settings.