OmniVLA: An Omni-Modal Vision-Language-Action Model for Robot Navigation
Abstract: Humans can flexibly interpret and compose different goal specifications, such as language instructions, spatial coordinates, or visual references, when navigating to a destination. In contrast, most existing robotic navigation policies are trained on a single modality, limiting their adaptability to real-world scenarios where different forms of goal specification are natural and complementary. In this work, we present a training framework for robotic foundation models that enables omni-modal goal conditioning for vision-based navigation. Our approach leverages a high-capacity vision-language-action (VLA) backbone and trains with three primary goal modalities: 2D poses, egocentric images, and natural language, as well as their combinations, through a randomized modality fusion strategy. This design not only expands the pool of usable datasets but also encourages the policy to develop richer geometric, semantic, and visual representations. The resulting model, OmniVLA, achieves strong generalization to unseen environments, robustness to scarce modalities, and the ability to follow novel natural language instructions. We demonstrate that OmniVLA outperforms specialist baselines across modalities and offers a flexible foundation for fine-tuning to new modalities and tasks. We believe OmniVLA provides a step toward broadly generalizable and flexible navigation policies, and a scalable path for building omni-modal robotic foundation models. We present videos showcasing OmniVLA performance and will release its checkpoints and training code on our project page.



Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Explaining “OmniVLA: An Omni-Modal Vision-Language-Action Model for Robot Navigation”
Overview: What is this paper about?
This paper introduces OmniVLA, a “Swiss Army knife” brain for robots that can understand different kinds of directions and use them to move around. Instead of learning from just one kind of instruction (like only GPS points or only pictures), OmniVLA can take in many kinds at once—like words, pictures, and positions—and use them together to figure out where to go and how to get there.
Objectives: What did the researchers want to achieve?
The researchers wanted to build a single robot navigation system that:
- Understands goals expressed in different ways (language, images, and positions).
- Can combine these ways (for example: “Go to this GPS point and stay on the sidewalk”).
- Works well in many places and on different robots, even ones it hasn’t seen before.
- Learns from a huge variety of data to make it more general and reliable.
Methods: How did they do it?
Think of OmniVLA as a robot brain that can:
- See through a camera.
- Read and understand text instructions.
- Decide what moves to make next.
To make this brain flexible and smart, the team did the following:
- Trained on a massive amount of experience: about 9,500 hours of driving and walking data collected from 10 different robot platforms in many kinds of environments (indoors, outdoors, sidewalks, parks, roads).
- Used a powerful “vision-language-action” model (VLA) as the backbone. This is like starting from a big, smart brain that already knows a lot from the internet and then teaching it to control robots.
- Let the robot handle three main goal types:
- Egocentric goal image: a picture of what the goal looks like from the robot’s perspective (like “go to the place that looks like this photo”).
- 2D goal pose: coordinates or GPS-like information telling the robot “go to this point on the map.”
- Natural language: instructions such as “move along the wall and go to the entrance.”
- Taught the model to combine these goal types. For example: “Head to these coordinates, and stay on the grass.”
- Used “modality dropout” during training. This means they sometimes hide one type of input (like removing the language or the image) so the robot learns to cope even when some information is missing—like practicing with one eye closed so you can still do well with either eye later.
- Turned goals into a shared “token” format inside the model, so words, pictures, and positions can be understood in the same internal language.
- Output actions as short sequences of moves (like steering and speed for the next couple of seconds), making the robot’s motion smooth and predictable.
They built two versions:
- A large, very capable model (based on OpenVLA, a 7-billion parameter system).
- A smaller “edge” version (based on ViNT) that runs on limited hardware but still performs well.
Results: What did they find, and why does it matter?
OmniVLA performed strongly across different types of tasks and beat specialized models that only handle one type of input. Highlights include:
- Egocentric image goals: near 100% success at reaching picture-defined targets.
- 2D pose/GPS goals: about 95% success, outperforming the strongest single-modality baselines.
- Language instructions: much better at following both normal and trickier, out-of-distribution (OOD) instructions (like “move along the building” even if it hasn’t seen that exact wording in training).
- Combining modalities (like GPS + language): it could reach the right place while following “how to get there” instructions (for example, “stay on the sidewalk” or “go between two objects”), achieving about 80% success—something most baselines couldn’t do.
- Adapting to new goal types: it learned to use satellite images as goals, improving a lot with only a small amount of extra training.
- Working on different robots: it controlled other robots (wheeled and quadruped) out of the box, following natural language and reaching targets.
This matters because real-world navigation often mixes different kinds of directions, and robots need to be flexible. OmniVLA shows that one general model can handle many types of inputs and environments.
Implications: Why is this important for the future?
- More natural human-robot interaction: People can give directions the way we naturally do—using words, maps, and pictures—without needing to force everything into one format.
- Better reliability in the real world: If one kind of information is missing or noisy (say GPS is weak indoors), the robot can rely on other inputs, like images or language.
- Easier to adapt: The model can be fine-tuned to new places or new kinds of goals with little extra data, making it practical for new cities, buildings, or tasks.
- A foundation for more capable robots: OmniVLA is a step toward broad “foundation models” for robotics—general brains that can be customized for many tasks, not just navigation.
In short, OmniVLA shows that teaching robots with mixed, real-world kinds of directions makes them smarter, more flexible, and more useful—and it opens the door to robots that can understand and combine “where” and “how” in the same task.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, concrete list of what remains missing, uncertain, or unexplored in the paper, intended to guide future research.
- Data quality and noise quantification: The training mixture heavily relies on synthetic action labels (MBRA, NoMaD) and custom reannotation for BDD-V; the paper does not quantify how label noise and reannotation errors impact performance across modalities, embodiments, and environments.
- Dataset mixture weighting: The fixed sampling ratio (LeLaN:GNM:Frodobots:BDD-V = 4:1:1:1) is not justified or ablated; it is unclear how mixture weights, dataset heterogeneity, or curriculum strategies affect generalization and modality balance.
- Action chunking and temporal horizon: The choice of N=8 at 3 Hz (2.4 s horizon) is not ablated; the sensitivity to chunk size, longer temporal horizons, and temporal credit assignment for long-horizon navigation remains unexplored.
- Modality dropout/masking strategy: The paper does not analyze dropout rates, mask patterns, or the effect of masking on cross-modal alignment and robustness; best practices for training-time vs inference-time masking are unknown.
- Cross-modal fusion and conflict resolution: The model accepts multiple modalities simultaneously but lacks mechanisms or analysis for resolving conflicting signals (e.g., language says “go on grass” while pose implies sidewalk), or dynamically weighting modality reliability (e.g., under GPS drift).
- Broader modality coverage: Beyond language, egocentric images, and 2D poses, other informative modalities (depth, LiDAR, semantic maps, audio cues, 3D goal volumes, floorplans, occupancy grids) are not studied; how to extend OmniVLA to these modalities remains open.
- Satellite imagery alignment: The adaptation to satellite goals is promising but limited; the paper does not address geo-registration challenges (scale, orientation, map freshness, occlusions, parallax), nor evaluate robustness across diverse geographies and map providers.
- Localization robustness: Pose-conditioned navigation depends on GPS; robustness under urban canyons, severe jitter/drift, multipath effects, or intermittent localization failures is not quantified; visual odometry or sensor fusion integration is not explored.
- Long-horizon memory integration: Image-conditioned long-range navigation uses an external topological memory; integration of memory into the VLA (e.g., learned spatial-temporal memory, graph embeddings, or differentiable mapping) and its effect on reliability is not addressed.
- Planning and safety guarantees: The policy outputs velocity sequences end-to-end without explicit planning or safety checks; the paper lacks collision statistics, near-miss rates, formal safety constraints, and strategies for integrating planners or safety shields.
- Dynamic environments and social compliance: Evaluations emphasize static obstacles; navigation amidst moving agents, social norms (yielding, passing), and crowded settings is not systematically benchmarked or measured.
- Failure mode analysis: There is no detailed breakdown of failure cases (e.g., mislocalization, instruction misinterpretation, perceptual aliasing, ambiguous references), nor actionable diagnostics for error recovery.
- Language evaluation breadth: OOD prompts are author-curated and largely single-step behavior modifiers; multi-step instructions, temporally compositional tasks, spatial relations under occlusion, ambiguity resolution, question-asking/clarification, and multilingual prompts remain unexplored.
- Standardized language benchmarks: The paper does not use standardized navigation language benchmarks; reproducible, objective scoring for “Behavior” (instruction adherence) and inter-annotator agreement are not provided.
- Retention under fine-tuning: While adapting to new modalities/environments, the paper does not evaluate catastrophic forgetting or performance retention across previously mastered modalities after fine-tuning.
- Embodiment transfer quantification: Cross-embodiment results (VizBot, Go1) are qualitative; systematic, quantitative evaluation across diverse dynamics, sensors, and actuation limits is missing.
- Action space normalization: Differences in action spaces (cars vs small robots) are handled via reannotation but not formally analyzed; strategies for normalizing/control constraints across embodiments and their effect on safety/generalization need study.
- Sensor limitations and multimodality: The policy uses a single RGB camera; the effect of adding depth/LiDAR/IMU/odometry on performance and robustness, and how to incorporate multi-sensor inputs within OmniVLA, is unexamined.
- Compute, latency, and deployment constraints: Real-time performance, inference latency, energy use, and memory footprint (especially for 7B models) are not reported; methods for distillation, quantization, and on-robot deployment constraints remain open.
- Scaling laws: The paper does not provide scaling analyses relating dataset size/diversity, modality count, and model capacity to performance, nor guidance on diminishing returns or optimal scaling regimes.
- Curriculum and active data collection: Strategies for targeted data acquisition (e.g., active learning, curriculum across environments/modality gaps) and their impact on sample efficiency and generalization are unexplored.
- Interactive learning and online adaptation: On-policy, real-time adaptation (e.g., RL, corrective feedback, human-in-the-loop instruction refinement) is not studied; safety-aware online learning remains an open direction.
- Multi-modal composition diversity: Only language+pose composition is evaluated; compositions such as image+language, pose+image, or tri-modal inputs (language+pose+image) and their failure/interaction patterns are not analyzed.
- Explainability and interpretability: The model’s internal reasoning across modalities is opaque; methods to visualize attention, modality contributions, and decision rationales (especially for instruction-following) are not provided.
- Benchmark breadth and environmental diversity: Real-world evaluation covers 40 environments but lacks systematic variation across weather, night-time, seasonal changes, terrain types, and extreme conditions; generalization under such shifts is unknown.
- Data and reannotation reproducibility: Custom reannotation for BDD-V and synthetic labels are central to performance, but details, tools, and datasets for independent replication are not fully accessible in the main text; release scope and licensing constraints are unclear.
Practical Applications
Immediate Applications
The following applications can be deployed now using the released OmniVLA checkpoints and training code, the smaller OmniVLA-edge variant for resource-constrained devices, and the demonstrated workflows (e.g., topological memory for long-range image-conditioned navigation, small-data fine-tuning, multi-modal conditioning).
- Campus and sidewalk delivery robots
- Sector(s): logistics, robotics
- Tools/workflows: OmniVLA-edge on low-cost wheeled robots; smartphone/ops console to specify destination via GPS coordinates plus a landmark photo and simple language (“stay on the sidewalk”); ROS integration; modality masking at runtime
- Assumptions/dependencies: reliable outdoor GPS; pedestrian-safe speeds; geofencing; weather/lighting robustness; local regulatory compliance; obstacle-dense areas may require conservative behaviors
- Warehouse and industrial facility navigation
- Sector(s): manufacturing, operations
- Tools/workflows: egocentric goal-image + language prompts (“go to dock 3, keep right of forklifts”); topological memory graphs to extend range indoors; OmniVLA-edge for on-prem deployment
- Assumptions/dependencies: indoor GPS typically unavailable—rely on image/topological memory; safety interlocks; traffic policies; periodic graph refresh due to layout changes
- Security patrol and facility inspection
- Sector(s): security, property management
- Tools/workflows: scheduled patrols conditioned by language (“follow the perimeter, check entrance C”) plus 2D goal poses; simple operator interface; logging for audit
- Assumptions/dependencies: robust night lighting or IR; dynamic obstacles; tamper detection; fail-safe stop; coverage planning
- Utilities and infrastructure field checks
- Sector(s): energy, telecom
- Tools/workflows: satellite image goal + 2D pose to approach assets (poles, valves) with language like “stay on shoulder”; deploy OmniVLA-edge on outdoor platforms
- Assumptions/dependencies: GPS accuracy in rural areas; traversability (grass, gravel); roadway safety policies; adverse weather handling
- Municipal services (park and sidewalk cleaning, signage checks)
- Sector(s): public sector, municipal operations
- Tools/workflows: language-conditioned routes (“move on grass near bench 4”) and waypoint-based patrols; simple fleet dispatcher UI
- Assumptions/dependencies: pedestrian safety; special-event closures; public acceptance; insurance and permitting
- Cross-embodiment deployment (wheeled and quadruped)
- Sector(s): defense, search-and-rescue, construction
- Tools/workflows: out-of-the-box language-conditioned navigation on heterogeneous platforms (e.g., VizBot, Unitree Go1) demonstrated in the paper; minimal retuning
- Assumptions/dependencies: embodiment-specific velocity/low-level control; terrain stability; communications; operator oversight in risky environments
- Human-in-the-loop supervision for mobile robots
- Sector(s): software, HRI
- Tools/workflows: operator provides high-level language goals and safety constraints; robot executes and reports progress; override/abort mechanisms; behavior adherence checks for OOD prompts
- Assumptions/dependencies: latency and bandwidth; explicit escalation paths; reliable logging and traceability
- Education and STEM labs
- Sector(s): education
- Tools/workflows: classroom kits using OmniVLA-edge; students specify multimodal goals to explore navigation concepts; reproducible experiments with released checkpoints
- Assumptions/dependencies: safe robots; limited compute; simplified environments; instructor training
- Healthcare facility wayfinding and assistive support
- Sector(s): healthcare
- Tools/workflows: language prompts (“follow wall to nurse station”) and short-range image goals in hospitals/clinics; topological memory
- Assumptions/dependencies: stringent safety and infection control; accessibility standards; busy corridors; periodic route revalidation
- Rapid site adaptation with small-data fine-tuning
- Sector(s): system integration, professional services
- Tools/workflows: LoRA-based fine-tuning with ~1–2 hours of site-specific data (2D poses, satellite goals) to boost success rates; balanced modality sampling during fine-tuning
- Assumptions/dependencies: short data collection run; GPU access; maintenance of modality balance; change management
- Mobile mapping via topological memory graphs
- Sector(s): software tooling
- Tools/workflows: record 1 Hz images to build goal graphs; online nearest-node localization; feed next-node image as goal
- Assumptions/dependencies: consistent viewpoint and lighting; periodic graph updates; storage and versioning of maps
- Academic research baseline for multimodal navigation
- Sector(s): academia
- Tools/workflows: OmniVLA checkpoints; training scripts; ablations on modality dropout/masking; comparative evaluation across modalities and embodiments
- Assumptions/dependencies: multi-GPU training for 7B variant; dataset licensing; standardized benchmarks
Long-Term Applications
The following applications require further research, scaling, engineering, or policy development (e.g., broader datasets, reliability and safety certification, edge inference advances, multi-agent coordination).
- City-scale “Navigation Foundation Service” (NFS) for fleets
- Sector(s): software/cloud, robotics
- Tools/products: cloud API serving OmniVLA-based navigation; fleet management; multi-modal goal composition; telemetry
- Assumptions/dependencies: low-latency inference or on-edge fallback; cost control for large models; robust across neighborhoods and seasons; privacy compliance
- Household generalist mobile assistants
- Sector(s): consumer robotics
- Tools/products: language + goal-image navigation in cluttered homes; personalized prompts; safe contact behaviors
- Assumptions/dependencies: robust indoor generalization; safety certifications; privacy, on-device learning; integration with home IoT
- Scaled last-mile delivery with natural-language drop-off semantics
- Sector(s): logistics
- Tools/products: “leave by the blue door” or “hand off to concierge” instructions; combined GPS/landmark navigation; proof-of-delivery workflows
- Assumptions/dependencies: semantic perception beyond navigation; reliable identity verification; municipal regulation; curbside and building access policies
- Disaster response and emergency navigation
- Sector(s): public safety, defense
- Tools/products: ad-hoc multimodal goals in degraded GPS; rugged embodiments; responder voice commands
- Assumptions/dependencies: robustness to smoke, darkness, debris; intermittent comms; safety guarantees; risk management
- Standards and safety frameworks for language-conditioned robotics
- Sector(s): policy, standards
- Tools/products: prompt design guidelines; test suites for instruction adherence; auditing and traceability requirements
- Assumptions/dependencies: multi-stakeholder process; alignment on acceptable behaviors; liability frameworks; certification pathways
- Multimodal robot data marketplaces and curation pipelines
- Sector(s): data/AI ecosystem
- Tools/products: cross-embodiment datasets; reannotation services (e.g., MBRA, NoMaD); modality balancing tools; licensing portals
- Assumptions/dependencies: privacy and consent; standard formats; provenance tracking; incentives for contributors
- Integration with high-level route planners and maps
- Sector(s): autonomous systems, software
- Tools/products: bridge modules combining OmniVLA low-level control with global planners; map-aware multimodal conditioning (including satellite)
- Assumptions/dependencies: APIs for planner-policy coordination; robust state estimation; failure recovery strategies
- Efficient on-device inference for large VLAs
- Sector(s): semiconductors, edge AI
- Tools/products: quantization/distillation of 7B model; accelerator support; power- and memory-aware scheduling
- Assumptions/dependencies: hardware availability; acceptable latency; maintaining performance with compression
- Personalized instruction learning and user-language adaptation
- Sector(s): consumer, enterprise
- Tools/products: continual learning of user phrasing; privacy-preserving fine-tuning; preference profiles
- Assumptions/dependencies: safe adaptation mechanisms; guardrails against prompt injection or unsafe commands; on-device storage
- Multi-robot coordination and shared multimodal situational awareness
- Sector(s): operations, smart cities
- Tools/products: shared satellite goals, semantic landmarks; scheduling and conflict avoidance; cross-fleet learning
- Assumptions/dependencies: reliable communications; centralized vs. decentralized control trade-offs; fairness and priority policies
- Accessibility-focused public guidance and prompt interfaces
- Sector(s): policy, public services
- Tools/products: standardized signage and voice interfaces for instructing municipal robots; ADA-compliant workflows
- Assumptions/dependencies: inclusive design; community engagement; security of public interfaces; accountability
- Environmental monitoring and scientific fieldwork
- Sector(s): environment, academia
- Tools/products: robots navigate to sampling sites with multimodal goals; repeatable route adherence; data collection pipelines
- Assumptions/dependencies: terrain/weather resilience; calibration; long-range autonomy; integration with GIS
- Insurance and risk modeling for multimodal robot navigation
- Sector(s): finance/insurance
- Tools/products: underwriting models informed by behavior adherence metrics and logs; compliance scoring
- Assumptions/dependencies: standardized safety KPIs; access to telemetry; legal frameworks for claims and liability
- Robotics curricula linking manipulation and navigation foundation models
- Sector(s): education, academia
- Tools/products: course modules demonstrating multi-modal conditioning, cross-embodiment transfer, modality dropout/masking
- Assumptions/dependencies: accessible compute; open datasets; sustained institutional support
Glossary
- 2D poses: Goal representations specifying positions (and sometimes orientations) in a 2D plane used to condition navigation policies. "three primary goal modalities: 2D poses, egocentric images, and natural language"
- Action chunk size: The number of timesteps of actions predicted per inference step to control execution horizon. "We set the action chunk size to 8 at 3 Hz, corresponding to 2.4 seconds for all models."
- Action head: A learned layer attached to a language-model output that decodes tokens into continuous robot actions. "add a linear action head to the LLM output to generate a sequence of actions"
- Attention mask: A masking matrix in transformers that prevents the model from attending to certain tokens (e.g., unavailable modalities) during training. "we construct an attention mask that excludes unused or unavailable modalities (filled with random values) so that only the selected modalities are attended to."
- CoW: A language-driven object navigation baseline using detectors and planners. "CoW~\cite{shah2023vint}: For language-conditioned navigation, we provide the current observation and prompts describing the target object to the OWL-ViT B/32 detector"
- Counterfactual action generation: A training technique that synthesizes alternative actions to improve policy learning. "Other works have extended to using counterfactual action generation~\cite{glossop2025cast}"
- CounterfactualVLA: A VLA model and dataset leveraging counterfactual actions for language-conditioned navigation. "we fine-tune our OmniVLA using the recently published CounterfactualVLA dataset"
- Cross-embodiment: Training or evaluating across different robot platforms and morphologies to improve generalization. "cross-embodiment robot actions"
- Depth360: A self-supervised monocular depth estimation method used to approximate 3D structure from RGB for navigation. "we estimate depth using Depth360~\cite{hirose2022depth360}"
- Egocentric goal images: First-person snapshots of the target location that serve as visual goals for navigation. "adding a visual backbone and a projector to condition on egocentric goal images and 2D goal poses."
- Egocentric images: First-person camera observations used for perception and sometimes goal specification. "2D poses, egocentric images, and natural language"
- Foundation model: A large, broadly trained model intended for adaptation to many tasks via fine-tuning. "Training foundation models requires that we leverage as much data as possible."
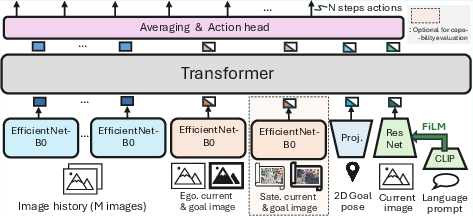
- Goal graph: A topological structure of images or states used to plan long-range navigation via successive goal images. "To build the goal graph, we record image observations at 1 Hz."
- Gradient accumulation: A technique to simulate larger batch sizes by accumulating gradients over multiple mini-batches before an optimizer step. "we accumulate the gradient for several steps to stabilize the training process."
- Internet-scale pre-training: Pre-training on massive web data to gain broad visual-language knowledge before robot fine-tuning. "contains knowledge from Internet-scale pre-training (for the base VLM)"
- Internet-scale videos: Large collections of online videos used to pre-train or augment robot policies. "methods that can leverage internet-scale videos~\cite{hirose2024lelan}"
- LeLaN: A language-conditioned navigation policy trained from diverse in-the-wild videos and robot data. "LeLaN~\cite{hirose2024lelan} leverages both robot and non-robot data to learn a generalized language-conditioned navigation policy"
- LLM backbone: The LLM core that processes tokenized inputs (vision, language, goal tokens) to produce outputs. "which serves as the input of the LLM backbone."
- LoRA: Low-Rank Adaptation; a parameter-efficient fine-tuning method that injects small trainable matrices into large models. "we apply LoRA to limit the learnable parameters to about 5 , allowing us to maximize the batch size and balance training speed with training stability."
- MBRA: Model-Based Reannotation; a method that refines action labels by generating improved synthetic actions from models. "MBRA\cite{hirose2025learning} introduces a model-based reannotation approach to leverage large-scale data sources to perform more challenging long-distance navigation tasks conditioned on 2D goal poses."
- MiniVLA: A smaller-footprint vision-language-action model variant used as a baseline backbone. "we also implement our omni-modal goal-conditioning strategy for the 1B MiniVLA~\cite{belkhale2024minivla}"
- Modality dropout: Randomly removing goal modalities during training so the model learns to be robust to missing inputs. "We use \"modality dropout\" to flexibly mask the goal modalities during training and inference."
- Modality masking: Disabling specific modalities at inference or training time so the model attends only to available inputs. "modality dropout during training, and modality masking during inference."
- NoMaD: A navigation method that uses goal-masked diffusion policies for exploration and planning. "NoMaD~\cite{sridhar2024nomad}: For 2D goal pose-conditioned navigation, we run the NoMaD policy in exploration mode"
- Omni-modal goal conditioning: Conditioning a navigation policy on multiple simultaneous goal specifications (e.g., language plus pose). "enables omni-modal goal conditioning for vision-based navigation."
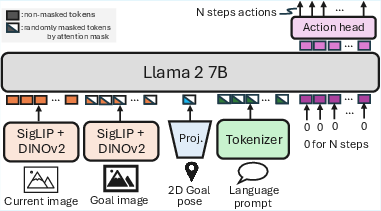
- OmniVLA: The proposed omni-modal vision-language-action model that unifies diverse goal modalities for navigation. "OmniVLA is the first end-to-end VLA model for navigation that unifies diverse task modalities."
- OmniVLA-edge: A smaller, resource-efficient variant of OmniVLA suitable for limited compute deployments. "we find OmniVLA-edge to be a very compelling choice for resource-constrained deployment, where inference of large VLA models is not feasible."
- OpenVLA: A large-scale VLA backbone used as the base architecture for OmniVLA. "built on top of OpenVLA~\cite{kim24openvla}, a 7B-parameter VLA model."
- Out-of-distribution (OOD): Inputs (e.g., prompts) that differ from the training distribution, used to test generalization. "out-of-distribution (OOD) language prompts"
- OWL-ViT B/32 detector: An open-vocabulary vision transformer detector used to localize target objects from language prompts. "the OWL-ViT B/32 detector~\cite{minderer2022simple}, reported as the strongest model in the original paper"
- Pose-conditioned policies: Navigation policies driven by target poses rather than solely images or language. "2D pose-conditioned policies are most successful in long-horizon tasks in outdoor environments with GPS localization~\cite{shah2022viking}."
- Projector: A module that maps modality-specific goal inputs (image, pose) into a common token space for the backbone. "adding a visual backbone and a projector to condition on egocentric goal images and 2D goal poses."
- Randomized modality fusion strategy: A training scheme that combines different goal modalities in random combinations to encourage cross-modal learning. "through a randomized modality fusion strategy."
- Reannotation model: A model trained to refine or generate synthetic action labels when raw actions are unavailable or mismatched. "we train a reannotation model to generate reasonable synthetic actions"
- Satellite modality: Using satellite images as a goal specification to test adaptation to a new task. "We use the satellite modality in the Frodobots dataset for evaluation of OmniVLA's ability to adapt to a new task."
- SmolVLA: A compact VLA backbone variant used to study capacity and pre-training effects. "the 500M SmolVLA~\cite{shukor2025smolvla}"
- State lattice motion planner: A planner that discretizes the state space into a lattice to compute feasible motion commands. "A state lattice motion planner is then used to generate velocity commands."
- Token space: The embedding space of discrete tokens (from different modalities) fed into the language-model backbone. "into a shared token space, which serves as the input of the LLM backbone."
- Topological memory: A graph-based memory of previously observed states or images used to extend navigation range. "employ topological memory for navigation"
- ViNT: A navigation transformer backbone used for the edge variant of OmniVLA. "built on top of ViNT~\cite{shah2023vint}, a 50M-parameter navigation transformer."
- Vision-Language-Action (VLA) model: A multimodal model that ingests visual and language inputs to output robot actions. "a 7B-parameter VLA model."
- Vision-language priors: Knowledge and biases inherited from vision-language pre-training that guide downstream behavior. "preserving the strong vision-language priors in the base model."
- VLM backbone: The underlying vision-LLM used to initialize or inform the VLA via pre-trained representations. "from the VLM backbone~\cite{karamcheti2024prismatic}"
Collections
Sign up for free to add this paper to one or more collections.