Optimizing Attention on GPUs by Exploiting GPU Architectural NUMA Effects
Abstract: The rise of disaggregated AI GPUs has exposed a critical bottleneck in large-scale attention workloads: non-uniform memory access (NUMA). As multi-chiplet designs become the norm for scaling compute capabilities, memory latency and bandwidth vary sharply across compute regions, undermining the performance of traditional GPU kernel scheduling strategies that assume uniform memory access. We identify how these NUMA effects distort locality in multi-head attention (MHA) and present Swizzled Head-first Mapping, a spatially-aware scheduling strategy that aligns attention heads with GPU NUMA domains to exploit intra-chiplet cache reuse. On AMD's MI300X architecture, our method achieves up to 50% higher performance over state-of-the-art attention algorithms using conventional scheduling techniques and sustains consistently high L2 cache hit rates of 80-97%. These results demonstrate that NUMA-aware scheduling is now fundamental to achieving full efficiency on next-generation disaggregated GPUs, offering a path forward for scalable AI training and inference.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview: What this paper is about
This paper is about making AI models (like LLMs) run faster on modern graphics chips (GPUs). New GPUs are built from several smaller pieces called chiplets. Because of this design, some parts of the chip can reach certain data faster than others. This uneven access is called NUMA (Non-Uniform Memory Access). The authors show that if we schedule attention computations (a core part of Transformers) in a way that matches this chip layout, we can make them run much faster. They propose a simple scheduling method called Swizzled Head-first Mapping and show it can speed up attention by up to 50% on AMD’s MI300X GPU.
The big questions the authors asked
- Can we take advantage of the “neighborhoods” inside a multi-chip GPU so attention runs faster?
- How should we assign pieces of the attention work to different chiplets so that data is reused more and memory is not wasted?
- Does this help both the forward pass (making outputs) and the backward pass (training step) of attention?
- Will these ideas still work for different attention styles, like Multi-Head Attention (MHA) and Grouped Query Attention (GQA)?
How they approached the problem
To follow the approach, here are a few simple explanations of key ideas:
- GPU with chiplets (NUMA): Imagine a city made of several neighborhoods (chiplets). Each neighborhood has its own small pantry (L2 cache) and roads to a big warehouse (HBM memory). It’s much faster to use food (data) from your own pantry than to drive to the big warehouse, or worse, to borrow from another neighborhood’s pantry.
- Cache: A small, nearby storage (the pantry) that is very fast. If many cooks in the same kitchen reuse the same ingredients, they save time by not running to the warehouse again.
- Attention and heads: The attention part of a Transformer looks at different parts of a sentence to decide what’s important. It does this in “heads.” You can think of each head as a team looking at the same document in different ways. Many heads together make up Multi-Head Attention (MHA). In GQA, some teams share certain notes (K and V).
- FlashAttention2 (FA2): A faster way to compute attention by chopping the work into tiles (blocks), so we keep important data in fast local memory instead of the slow big warehouse.
What goes wrong today:
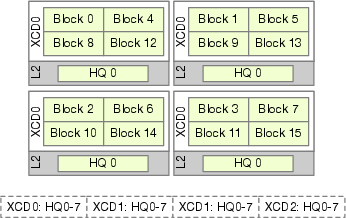
- Most existing attention kernels assume every cook reaches ingredients equally fast. But on chiplet GPUs, that’s not true. Default scheduling spreads related work across multiple neighborhoods. That means the same ingredients get loaded into several different pantries, wasting time and traffic.
The authors’ idea:
- Group related work so that it stays inside the same neighborhood and reuses the same pantry.
- Specifically, they identify natural “compute clusters” in attention: all the tiles that share the same K and V data (in MHA, that’s one head; in GQA, it’s a group of heads). They call these clusters Attention Compute Clusters (ACCs).
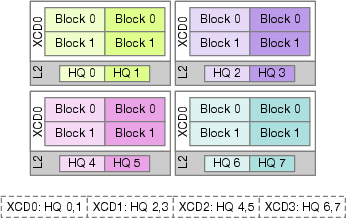
- Their Swizzled Head-first Mapping assigns all tiles of one attention head (or head group) to the same chiplet before moving on to the next head. In short: finish one head per neighborhood, then move to the next. This keeps shared data hot in the local pantry (L2 cache) and avoids re-fetching from the warehouse (HBM).
What they compared:
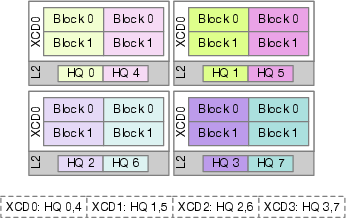
- Naive Block-first: Process one block of every head in turn (splits a head’s work across many neighborhoods; bad reuse).
- Swizzled Block-first: A smarter version that tries to keep grouped heads together, but still often splits work unless group counts match chiplets.
- Naive Head-first: Do all blocks of a head first, but still spread them across neighborhoods (so the same data is duplicated in many pantries).
- Swizzled Head-first (their method): Do all blocks of a head and keep them inside one neighborhood (best reuse).
They implemented these scheduling patterns using Triton (a GPU programming system) and measured performance and cache use on an AMD MI300X GPU.
What they found and why it matters
Here are the main results in simple terms:
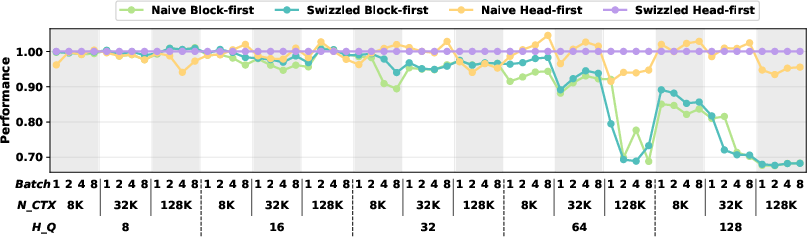
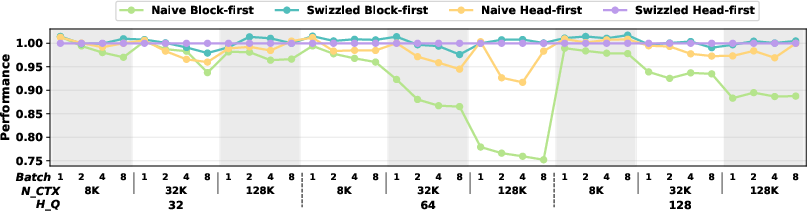
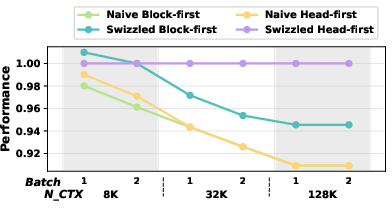
- Big speedups: On AMD MI300X, Swizzled Head-first Mapping makes attention up to 50% faster compared to strong existing methods, especially when there are many heads (like 64–128) and long sequences (like 32K–128K tokens).
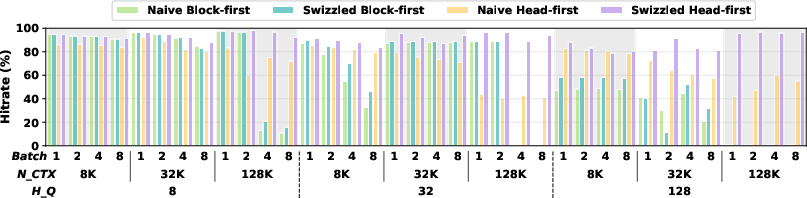
- Excellent cache reuse: Their method keeps L2 cache hit rates very high (about 80–97%), meaning most needed data is already in the local pantry and doesn’t have to be fetched again.
- Scales to real models: It works well for both MHA and GQA. For real setups like DeepSeek-V3’s prefill (128 heads), it stays fast at long sequence lengths where other mappings slow down a lot.
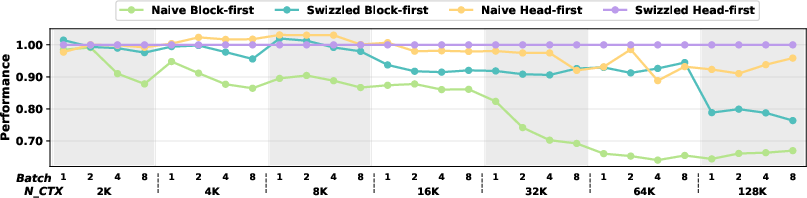
- Training benefits too: For the backward pass (used during training), Swizzled Head-first gives consistent speedups, up to about 1.10× at very long sequences.
- Minimal code changes: The scheduling logic is small and simple to add, but gives big wins.
Why this matters:
- Faster attention means faster training and inference for large AI models.
- Better cache use reduces pressure on memory bandwidth, which is a major bottleneck on modern GPUs.
- As more GPUs use chiplets, being “NUMA-aware” (understanding neighborhoods) becomes essential for top performance.
Implications: What this could change
- Hardware-aware AI software: Future AI kernels should consider where data lives on the chip, not just how to compute it. “Where” you schedule work is now as important as “when.”
- Lower costs and energy: If attention runs faster and hits cache more often, you save time, electricity, and money when training or serving big models.
- Ready for next-gen GPUs: As more companies use multi-die designs, this scheduling idea provides a simple, portable path to keep performance high.
- A general rule of thumb: Keep work that shares the same data together on the same chiplet. This principle isn’t just for attention—it can help other GPU workloads too.
In short, the paper shows a simple scheduling tweak that matches how modern GPUs are built. By keeping related attention work inside one chiplet, you get big speedups, better cache use, and performance that holds up even at very large scales.
Knowledge Gaps
Unresolved knowledge gaps, limitations, and open questions
Below is a concise list of missing, uncertain, or unexplored aspects that future researchers could address to strengthen and generalize the paper’s claims and methods:
- Generalization beyond AMD MI300X: The approach is evaluated only on MI300X; performance and cache behavior on other architectures (e.g., NVIDIA Blackwell/Rubin with cross-die coherency, Hopper, prior AMD CDNA generations, or future CDNA variants) remain untested.
- Coherent-die GPUs: How NUMA-aware swizzling behaves when the hardware provides full cross-die cache coherency (e.g., NVIDIA Blackwell) is unclear—could head-first mapping be redundant or counterproductive?
- Scheduler variability: The method assumes a driver-level chunked round-robin WG distribution; its robustness to future scheduler changes (e.g., different chunk sizes, load-balancing heuristics) is not evaluated or modeled.
- Automatic topology detection and policy selection: There is no runtime mechanism to detect NUMA topology (die count, per-die L2 size, memory interleaving) and auto-select the best mapping (e.g., head-first vs block-first) per device/configuration.
- Load balance versus locality trade-offs: The paper does not quantify whether confining ACCs to single XCDs causes load imbalance or uneven occupancy across dies under various head/batch/sequence distributions.
- HBM bandwidth utilization: No direct measurement of HBM/LLC traffic or per-XCD bandwidth saturation; it remains unclear whether head-first co-location risks HBM controller hotspots or underutilizes aggregate bandwidth.
- Multi-stream and multi-tenant scenarios: Interaction with concurrent kernels, MPS/MIG-like partitioning, and multi-tenant interference is not studied; does swizzling remain beneficial under contention?
- End-to-end model impact: The evaluation focuses on kernel-level microbenchmarks; real model throughput/latency improvements (prefill+decode end-to-end, training steps/epoch time) are not quantified.
- Decoder-phase (autoregressive) attention: The paper optimizes prefill and FA2 forward/backward, but does not evaluate decode-phase with KV-cache reuse across timesteps, where locality and reuse patterns differ substantially.
- Cross-attention and masked variants: Effects on different attention forms (cross-attention, causal/padding masks, sliding-window/long-context variants like Longformer/Ring-Attention) are not addressed.
- Backward-pass bottlenecks: Backward speedups are modest (~1.10× at 128K); the specific emerging bottlenecks (compute-bound scalar ops, reductions, synchronization) are not identified or systematically optimized.
- Low-precision and asynchrony: Interaction with FA3, FP8/INT8 quantization, and asynchronous pipelining is unknown; do precision changes alter cache reuse and best mapping strategies?
- Tiling parameter sensitivity: Experiments use fixed BLOCK_M/BLOCK_N and limited head dimensions; a systematic sweep (and autotuning) over tile sizes, head dims, and CTA shapes to co-optimize with NUMA mapping is missing.
- Per-XCD cache metrics: L2 hit rates are aggregated across XCDs; per-die hit/miss distribution, eviction pressure, and cross-die traffic counters (LLC, interconnect) are needed to validate the locality hypothesis more precisely.
- Memory placement across HBM stacks: The paper does not analyze how memory interleaving or allocator policies map Q/K/V across HBM stacks; explicit placement could amplify or diminish NUMA benefits.
- Hotspot and thermal concerns: Assigning large ACCs to single XCDs may create hotspots; effects on power/thermal throttling and energy efficiency are not measured.
- Robustness to shape variability: The mapping’s stability under dynamic batch sizes, ragged sequences, and variable head counts (including per-request heterogeneity typical in inference serving) is not explored.
- Non-attention ops and fusion: Interactions with adjacent kernels (RMSNorm, rotary embeddings, projections, residuals) and opportunities for fusion that might change mapping/locality are not considered.
- Multi-GPU scaling: Extending NUMA-aware mapping across GPUs (NVLink/XGMI), model/tensor/pipeline parallelism, and inter-device NUMA effects remains an open problem.
- Compiler and framework integration: Practical integration into PyTorch/Triton/ROCm libraries (automatic graph-level ACC inference, kernel selection, autotuning) is not described; reproducibility and code availability for the presented kernels are unclear.
- Formal performance model: There is no analytic or simulation-based model predicting cache hit rates and throughput given topology and tiling; such a model could guide automatic mapping decisions.
- Non-divisible mappings: Behavior and performance when ACC counts or GQA group counts do not divide evenly into XCDs (including remainder handling and head skew) are not quantified.
- Correctness and masking edge cases: While swizzling is claimed minimally invasive, potential corner cases (e.g., causal masking boundaries, numerical stability in online softmax under remapped iteration) are not rigorously validated.
Practical Applications
Immediate Applications
The following applications can be deployed now using the paper’s NUMA-aware “Swizzled Head-first Mapping” for attention on chiplet GPUs (e.g., AMD MI300X), with minimal code changes in Triton/ROCm-based stacks and direct impact on cost, throughput, and energy.
- High-throughput long-context LLM inference serving (prefill-heavy)
- Description: Deploy Swizzled Head-first mapping in FlashAttention2 (FA2) kernels for batched prefill on MI300X-class instances to cut latency and raise tokens/sec for long prompts (e.g., 32K–128K tokens) and high head counts (64–128).
- Sectors: software/SaaS, finance (research assistants), customer support, education, healthcare (clinical summarization), media/legal (document analysis).
- Tools/Workflows: Triton FA2 kernels; ROCm AITER integration; PyTorch extension; Hugging Face Transformers/Optimum-ROCm; vLLM/LightLLM/DeepSpeed-MII backends; Kubernetes+MIG style service tiers for long-context SKUs.
- Impact: Up to ~50% higher throughput in extreme regimes; 80–97% L2 hit rates reduce HBM traffic and tail latency.
- Assumptions/Dependencies: MI300X/MI325-class GPUs with exposed NUMA; FA2-based attention; accurate NUM_XCD detection; long contexts and/or many heads for largest gains; stable driver WG scheduling semantics.
- Faster, cheaper training of Transformer models using FA2
- Description: Integrate the mapping in training kernels (forward and backward; backward shows modest but consistent benefits) to reduce time-to-train and power.
- Sectors: industry labs, academia, healthcare/drug discovery (protein LLMs), weather/climate forecasting, robotics foundation models.
- Tools/Workflows: Megatron-LM/DeepSpeed training configs; ROCm builds; Triton-backed FA2; profiler-guided tuning with ROCProfiler v3.
- Impact: Reduced time-to-accuracy, GPU-hours, and carbon per experiment; higher throughput at large head counts and long-context curricula.
- Assumptions/Dependencies: Training uses FA2 kernels; benefits increase with sequence length and heads; backward pass speedups smaller than forward but positive.
- NUMA-aware FA2 packaged as a drop-in library for ROCm
- Description: Ship “NUMA-Aware FlashAttention2 for ROCm” wheels and Triton templates that auto-map heads to XCDs (Swizzled Head-first), with runtime guards for topology/query.
- Sectors: software, cloud platforms, OEMs.
- Tools/Workflows: ROCm AITER repository; Triton swizzle utility; automatic NUM_XCD query; fallbacks for non-NUMA hardware.
- Impact: One-line upgrades in inference/training stacks; portable gains on MI300X.
- Assumptions/Dependencies: Maintained compatibility with ROCm/Triton versions; kernel autotuning retains occupancy.
- Energy and cost optimization in AI data centers
- Description: Reduce HBM transactions via higher L2 reuse; integrate cache-hit telemetry into autoscaling and SLO policies to cut $/token and W/token.
- Sectors: cloud, energy/sustainability.
- Tools/Workflows: ROCProfiler-driven L2-hit dashboards (Prometheus/Grafana); inference cost estimators; carbon reporting tied to kernel mapping.
- Impact: Lower power draw and cooling costs; improved sustainability metrics without hardware changes.
- Assumptions/Dependencies: Access to counters; operators can select kernel variants by workload (context length, heads, batch).
- Performance uplift for specific model families out of the box
- Description: Apply mapping to MHA (e.g., DeepSeek-V3 prefill with H=128) and GQA (e.g., Llama 3 8B/70B/405B) without model changes.
- Sectors: software, research, enterprise LLM deployments.
- Tools/Workflows: Model-serving frameworks (vLLM, Text-Generation-Inference) including a “chiplet-optimized attention” flag; CI perf tests for 8K–128K contexts.
- Impact: Immediate speedups on routine workloads; more stable tail latency at high batch x sequence regimes.
- Assumptions/Dependencies: GQA vs. MHA differences handled; ensure head/group counts don’t split ACCs across XCDs.
- Compiler/library updates and presets
- Description: Add “Head-first swizzle” presets in Triton, and enable runtime selection heuristics (heads, batch, context).
- Sectors: compilers/libraries, software.
- Tools/Workflows: Triton decorators; ROCm AITER kernels; autotuner rules (choose head-first at H≥64 or seq≥32K).
- Impact: Fewer manual toggles; safer defaults for chiplet GPUs.
- Assumptions/Dependencies: Runtime topology query; heuristic boundaries validated per architecture.
- NUMA-aware performance benchmarking and QA
- Description: Extend perf suites to report L2 hit rates and NUMA sensitivity alongside throughput and latency; add A/B tests vs. naïve/block-first mappings.
- Sectors: QA, cloud benchmarking, MLPerf task owners.
- Tools/Workflows: Reproducible Triton kernels; ROCProfiler v3 integration; MLPerf supplemental metrics (cache efficiency).
- Impact: Detect regressions when driver scheduling changes; standardized reporting for procurement.
- Assumptions/Dependencies: Stable access to performance counters; vendor tooling parity.
Long-Term Applications
These applications require further research, scaling, standardization, or vendor support but build directly on the paper’s insights into spatially-aware kernel design for chiplet GPUs.
- Automatic NUMA-aware mapping in compilers and runtimes
- Description: Compiler passes (Triton/TVM/XLA/IREE) that detect “attention compute clusters” (ACCs) and automatically co-locate them on die-local caches; dynamic selection based on topology and live counters.
- Sectors: compilers, software, cloud platforms.
- Tools/Workflows: Pattern-matching in IR; feedback-directed optimization (FDO) using L2 hit counters; deployment-time kernel selection.
- Dependencies: Standardized topology queries; low-overhead counters; correctness across diverse schedulers.
- Cross-vendor topology and placement standards
- Description: Define vendor-neutral APIs to expose chiplet/NUMA domains, cache sizes, and die affinity hints; extend HIP/CUDA/Khronos specs for workgroup placement.
- Sectors: standards bodies, hardware vendors, cloud providers.
- Tools/Workflows: HIP/CUDA extensions; Kubernetes device plugins surfacing die-level topology; scheduler hints in drivers.
- Dependencies: Vendor cooperation; security/isolation considerations; backward compatibility.
- Driver-level workgroup affinity and cache-partitioning policies
- Description: OS/driver support for “ACC affinity,” allowing kernels to request die-local execution and optional L2 partitions to avoid cache contention between ACCs.
- Sectors: hardware-software co-design, OEMs.
- Tools/Workflows: Placement APIs; cache-way allocation; QoS for mixed workloads.
- Dependencies: Hardware/firmware support; fairness and utilization trade-offs; compatibility with coherence protocols.
- Generalization beyond attention
- Description: Apply spatially-aware mapping to MoE routing/projections, KV-cache maintenance, retrieval scoring, diffusion attention, and GNN attention, where subgraphs share large read-mostly tensors.
- Sectors: recommender systems, search/RAG, scientific computing (genomics, weather), drug discovery, finance (risk graph models).
- Tools/Workflows: Operator libraries providing “ACC-like” grouping primitives; graph compilers co-locating subgraphs per die.
- Dependencies: Robust identification of shared-tensor groups; mixed-precision and asynchrony interactions (e.g., FA3).
- Topology-aware model-parallel and serving schedulers
- Description: Incorporate die-level affinity into pipeline/tensor parallelism and inference schedulers (vLLM, Ray Serve), keeping attention-heavy stages on a single die or a NUMA-friendly subset across multi-GPU nodes.
- Sectors: cloud AI serving, distributed training.
- Tools/Workflows: Cost models factoring L2 reuse and interconnect traffic; schedulers that pack requests by ACC.
- Dependencies: Multi-device topology awareness; interplay with KV-cache sharding and batching.
- Energy-aware orchestration using cache-efficiency feedback
- Description: Data center controllers adjust batching, head-first mapping, and die affinity to minimize joules/token under SLOs, guided by real-time L2/HBM metrics.
- Sectors: cloud, sustainability.
- Tools/Workflows: Control loops in autoscalers; per-pod kernel selection; carbon-aware scheduling.
- Dependencies: Accurate, streaming telemetry; coordination with admission control.
- Education and workforce development on chiplet-era optimization
- Description: Curricula and lab kits demonstrating NUMA effects and spatially-aware scheduling for attention/GEMM; competitions for topology-aware kernel design.
- Sectors: academia, training providers.
- Tools/Workflows: Open-source Triton labs; MI300X dev clusters for courses; benchmarking leaderboards.
- Dependencies: Accessible hardware/time sharing; maintained teaching kernels.
- Guidance for procurement, regulation, and benchmarks
- Description: RFPs and compliance checklists requiring NUMA-aware kernels on chiplet GPUs; benchmarks reporting energy and cache-efficiency metrics; policy incentives for architecture-aware software in public-sector AI.
- Sectors: government, standards, enterprise IT.
- Tools/Workflows: MLPerf addenda; sustainability scorecards; audit scripts verifying kernel mappings.
- Dependencies: Community consensus on metrics; verification methods that respect IP.
- Extension to heterogeneous and edge chiplet NPUs
- Description: As chiplet NPUs proliferate in edge/embedded platforms, adapt ACC-aware mappings for on-device long-context inference and multimodal attention.
- Sectors: robotics, automotive, mobile.
- Tools/Workflows: Vendor SDKs exposing die topology; lightweight Triton-like DSLs; hybrid CPU–NPU scheduling.
- Dependencies: Exposure of NUMA at the edge; memory budgets vs. L2 sizes; power constraints.
Notes on applicability and assumptions
- Hardware dependency: Benefits are largest on architectures that expose NUMA (e.g., AMD MI300X). Systems with full inter-die cache coherence (e.g., NVIDIA Blackwell, per the paper) may see reduced need, though spatial affinity can still help under cache pressure.
- Workload dependency: Gains grow with longer sequences, more heads, and larger batches; modest for small contexts/heads. GQA vs. MHA requires different grouping but both benefit when ACCs are not split across dies.
- Software stack: Current implementations rely on Triton, ROCm, and FA2. Driver scheduling policies can change; libraries should keep mapping logic adaptable and query topology at runtime.
- Correctness and portability: Mapping must preserve algorithmic behavior; fall back to neutral mappings on uniform-memory GPUs to maintain portability.
Glossary
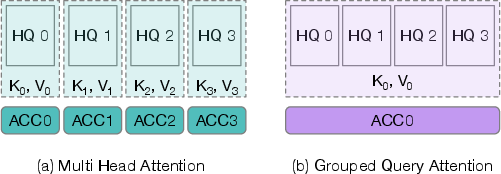
- Attention Compute Cluster (ACC): A grouping of workgroups that share the same input tensors within an attention mechanism to maximize cache reuse when co-located on a single die. "From a spatial locality perspective, workgroups that share the same input tensors during either forward or backward computation naturally form what we term an Attention Compute Cluster (ACC)."
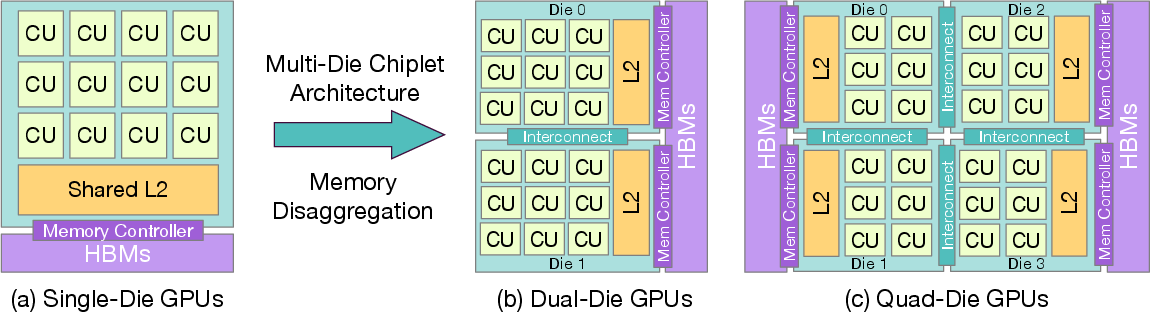
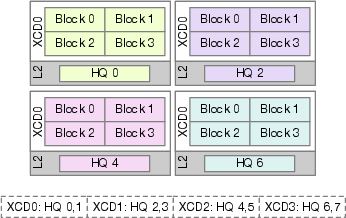
- Accelerator Complex Die (XCD): A chiplet within AMD GPUs that contains its own compute units, L2 cache, and memory controllers, forming a NUMA domain. "The MI300X features eight XCDs (Accelerator Complex Dies), each with dedicated compute units, L2 cache, and memory controllers connected to independent HBM stacks."
- AITER: AMD’s AI Tensor Engine for ROCm, a repository of high-performance AI operators and kernels. "This scheme is deployed by AMD's AITER~\cite{aiter} repository of high-performance AI operators."
- Cache coherency: A hardware property ensuring caches across different dies observe a consistent view of memory, reducing software-visible NUMA effects. "NVIDIA's Blackwell maintains full cache coherency between the dies, abstracting the NUMA effects at the hardware level"
- Chiplet architecture: A multi-die design that partitions compute and memory resources across separate silicon chiplets connected via inter-die interconnects. "Quad-die chiplet architecture (e.g., NVIDIA Rubin Ultra~\cite{nvidia_rubin_ultra}, AMD MI300~\cite{amd_mi300} series) with further disaggregation."
- Cooperative Thread Array (CTA): A GPU execution unit grouping threads cooperatively, often swizzled for locality in high-performance kernels. "This remapping approach generalizes the cooperative thread array (CTA) or workgroup swizzling techniques widely used in high-performance GEMM libraries such as Tensile~\cite{tensile}, hipBLASLt~\cite{hipBLASlt}, and Triton~\cite{triton-swizzle2d}."
- Compute Unit (CU): The primary GPU execution block comprising multiple stream processors; CUs share caches within a die in traditional architectures. "unified L2 cache shared across all compute units (CUs), providing uniform memory access."
- Disaggregated memory hierarchies: Memory subsystems distributed across large dies or multiple chiplets, leading to non-uniform access latencies and bandwidth. "Modern GPU architectures designed for AI workloads have increasingly adopted disaggregated memory hierarchies to achieve the necessary scale in compute capacity and memory bandwidth."
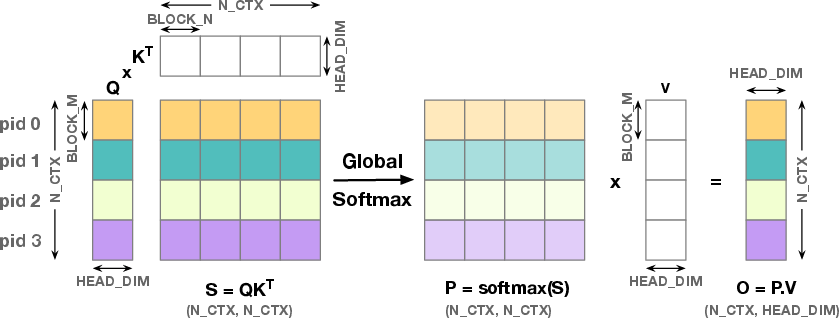
- FlashAttention (FA): An attention algorithm using online softmax and tiling to reduce memory overhead while maintaining exactness. "FlashAttention~(FA)~\cite{flashattention} addresses this limitation by using an online softmax approach, enabling tiled computation where intermediate blocks of and reside in local memory rather than global memory."
- FlashAttention2 (FA2): An optimized attention algorithm that improves parallelism and work partitioning across the context length. "FlashAttention2~(FA2)~\cite{flashattention2} further improves performance by parallelizing WGs across the context length for both forward and backward computations."
- GEMM: General Matrix-Matrix Multiplication, a core linear algebra kernel whose spatially-aware mapping can dramatically improve cache utilization. "spatially-aware mapping strategies for GEMM operations on the MI300X have shown dramatic improvements in cache utilization"
- Grouped Query Attention (GQA): An attention variant where multiple query heads share the same key and value projections to reduce memory footprint. "More recent models have adopted grouped query attention (GQA)~\cite{gqa}, which reduces memory requirements by sharing key and value projections across multiple query heads"
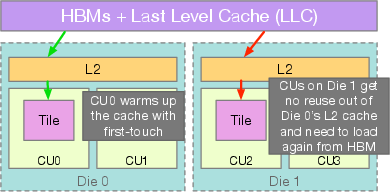
- HBM (High Bandwidth Memory): On-package DRAM providing very high bandwidth; accessed via per-die memory controllers in chiplet GPUs. "This cross-die scheduling forces redundant memory fetches from HBM through the shared last-level cache (LLC)"
- HBM3: The third generation of High Bandwidth Memory used in modern accelerators with very high throughput. "HBM3 Bandwidth & 5.3 TB/s"
- hipBLASLt: An AMD ROCm library providing high-performance BLAS routines with tiling and swizzling support. "such as Tensile~\cite{tensile}, hipBLASLt~\cite{hipBLASlt}, and Triton~\cite{triton-swizzle2d}"
- Last-level cache (LLC): The cache level shared across dies or memory controllers that sits closest to main memory. "redundant memory fetches from HBM through the shared last-level cache (LLC), as L2 caches are private to each Accelerator Complex Die or XCD."
- L2 cache hit rate: The fraction of memory accesses serviced by the L2 cache, indicating reuse and locality effectiveness. "sustains consistently high L2 cache hit rates of 80-97\%."
- MI300X: AMD’s chiplet-based Instinct GPU designed for AI workloads with eight XCDs and disaggregated memory. "On AMDâs MI300X architecture, our method achieves up to 50\% higher performance over state-of-the-art attention algorithms"
- Multi-head attention (MHA): The Transformer mechanism that splits model dimensions across multiple attention heads operating in parallel. "In practice, Transformer models use multi-head attention (MHA), which splits the model dimension () across multiple attention heads."
- Non-uniform memory access (NUMA): A memory model where access latency and bandwidth vary with the location of compute relative to memory. "The rise of disaggregated AI GPUs has exposed a critical bottleneck in large-scale attention workloads: non-uniform memory access~(NUMA)."
- NUMA domain: A hardware region (e.g., a die) with localized memory and cache resources presenting distinct access costs. "each die (or NUMA domain) receives a small, contiguous batch of WGs before the scheduler advances to the next."
- Online softmax: A numerically stable technique to compute softmax incrementally over tiles, enabling memory-efficient attention. "FlashAttention (FA) addresses this limitation by using an online softmax approach"
- Prefill stage: The phase in LLM inference that computes initial context attention (often with MHA) before decoding. "For MHA, used in the prefill stage of models like DeepSeek-V3~\cite{deepseekv3}, this strategy causes multiple ACCs per XCD to be served simultaneously"
- ROCProfiler v3: A profiling tool in ROCm used to collect hardware performance counters, such as cache hit rates. "We use ROCProfiler v3~\cite{rocprofv3} to measure L2 cache hit rates via hardware performance counters"
- Round-robin policy: A scheduler strategy that dispatches workgroups in a cyclic order across dies, often fragmenting spatial locality. "Modern multi-die chiplet GPUs schedule workgroups (WGs) across compute dies using a chunked round-robin policy"
- Spatial locality: The property that nearby computations reuse nearby data, critical for cache efficiency on NUMA hardware. "This section explores the spatial locality inherent in the FlashAttention2 algorithm"
- Swizzled Block-first mapping: A mapping strategy that iterates blocks first and swizzles head assignments to improve locality, effective when GQA groups match XCD count. "The Swizzled Block-first approach retains the block-first iteration order but applies a swizzling technique to co-locate grouped heads in GQA within the same XCD, preserving locality"
- Swizzled Head-first Mapping: The proposed scheduling strategy that confines all blocks of an attention head to a single XCD to exploit cache reuse. "present Swizzled Head-first Mapping, a spatially-aware scheduling strategy that aligns attention heads with GPU NUMA domains to exploit intra-chiplet cache reuse."
- Swizzling: The deliberate reordering of work-to-hardware mapping to improve locality and cache utilization. "One widely adopted technique to address this challenge is swizzling, which refers to the deliberate reordering of how computational work is mapped to hardware execution units to improve memory locality and cache utilization."
- Tensile: An AMD library for high-performance GEMM that uses swizzling and spatially-aware tiling. "such as Tensile~\cite{tensile}, hipBLASLt~\cite{hipBLASlt}, and Triton~\cite{triton-swizzle2d}"
- Triton: A language and compiler for writing tiled GPU kernels, used to implement the paper’s attention kernels and swizzling logic. "All kernels are implemented in Triton~\cite{triton}."
- Workgroup (WG): A unit of parallel execution (CTA) scheduled on GPU hardware; mapping of WGs to dies impacts locality. "Modern multi-die chiplet GPUs schedule workgroups (WGs) across compute dies using a chunked round-robin policy"
- Workgroup ID: The identifier of a workgroup used for remapping (swizzling) to enforce spatial locality. "Chiplet-aware workgroup ID remapping in Triton."
Collections
Sign up for free to add this paper to one or more collections.