- The paper introduces hardware-efficient attention techniques that halve the KV cache size and double arithmetic intensity to mitigate memory bottlenecks.
- It presents Grouped-Tied Attention (GTA) and Grouped Latent Attention (GLA) which optimize memory usage and enable efficient distributed inference on GPUs.
- Empirical results show up to twice token throughput and significantly lower latency, paving the way for scalable and real-time LLM decoding.
Hardware-Efficient Attention for Fast Decoding
Introduction
The paper "Hardware-Efficient Attention for Fast Decoding" introduces advanced techniques to enhance the decoding efficiency of LLMs by revisiting the hardware implementation of attention mechanisms. The authors propose Grouped-Tied Attention (GTA) and Grouped Latent Attention (GLA), which address the memory-bound performance of conventional attention by reducing the key-value (KV) cache size and enhancing parallel scalability across modern GPUs.
Methodology
Grouped-Tied Attention (GTA)
GTA leverages a unified key and value representation, shared across groups of query heads to halve the KV cache size and double the arithmetic intensity compared to Grouped-Query Attention (GQA). By tying the keys and values, GTA reduces memory bandwidth usage and mitigates the memory-bound bottleneck.
Figure 1: Overview of Grouped-Tied Attention (GTA), showcasing its simplified KV state management.
Grouped Latent Attention (GLA)
GLA extends Multi-head Latent Attention (MLA) by sharding latent heads, facilitating efficient distributed inference. By compressing tokens into latent heads and optimizing projection matrices, GLA achieves high arithmetic intensity and efficient scalability.
Figure 2: Memory-loading schematics for GLA illustrate the optimization in KV cache management.
System Optimization
Asynchronous Software Pipelining
The authors employ asynchronous software pipelining to overlap computation with memory operations, ensuring maximum utilization of GPU Tensor Cores. This technique involves using warp specialization and pipelined memory loading to maintain the tensor cores at full capacity.
Experiments and Results
GLA exhibits superior token throughput and reduced latency in online server benchmarks compared to MLA. Notably, GLA achieves up to twice the throughput and significantly lowers latency across different concurrency levels.
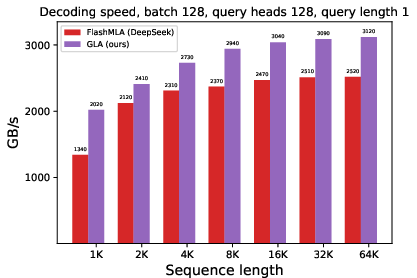
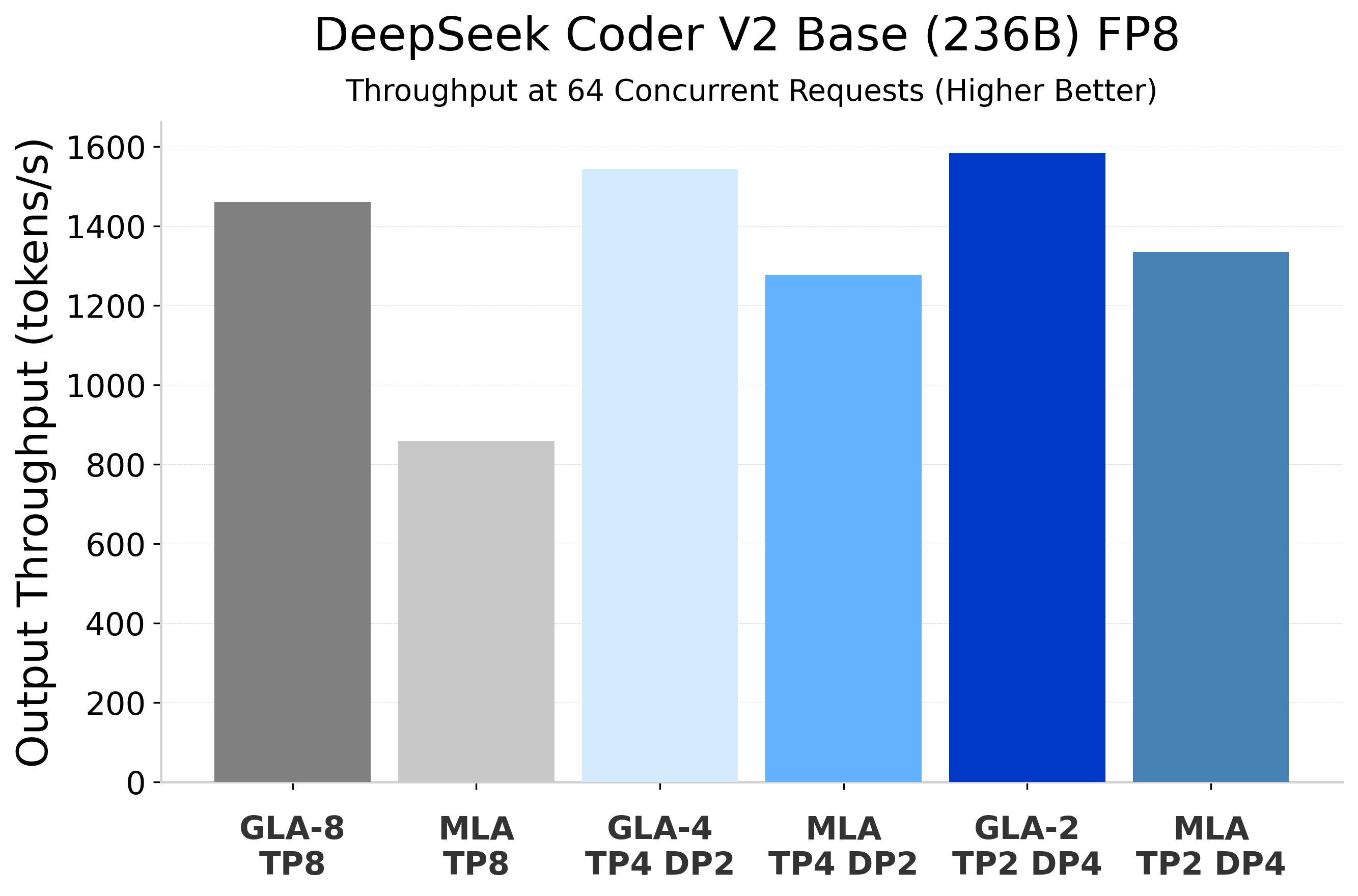
Figure 3: Output throughput comparison under live server benchmark settings, highlighting GLA's performance edge over MLA.
Scalability
The rigorous evaluation across different scales and setups demonstrates GLA's robustness. With superior parallelization capabilities, GLA effectively utilizes available hardware resources, significantly outperforming MLA in distributed inference scenarios.
Discussion
The interplay between arithmetic intensity and parallel execution explored in the paper addresses fundamental bottlenecks in LLM decoding. The techniques articulated pave the way for more sustainable and economically feasible LLM deployment across various hardware architectures, including edge devices.
Conclusion
The research demonstrates that optimizing attention mechanisms for hardware efficiency can result in significant improvements in LLM inference. GTA and GLA provide compelling alternatives to existing attention architectures by ensuring higher computational efficiency and effective scalability, which are critical for real-time applications.
This paper underscores a pivotal step towards more efficient and practical applications of LLMs, potentially influencing future research and implementation of neural architectures on a large scale.

