- The paper introduces an asynchronous KV cache prefetching method that overlaps computation and data loading to reduce latency.
- It leverages NVIDIA Hopper's L2 cache and detailed profiling of GPU bottlenecks to achieve up to 2.15x speedup in attention kernels.
- Experimental results on NVIDIA H20 GPUs demonstrate nearly doubled compute and memory throughput, outperforming baselines like FlashAttention-3.
Accelerating LLM Inference Throughput via Asynchronous KV Cache Prefetching
Introduction
LLMs are increasingly utilized across numerous domains, including real-time translation, automated content generation, and personalized recommendation systems. Despite their advanced capabilities, inference remains a bottleneck due to the substantial memory bandwidth demands and latency challenges, particularly in GPUs. To address these challenges, the paper introduces a novel asynchronous KV Cache prefetching method designed to overlap computation and data loading, thereby enhancing inference throughput.
Motivation
During inference with LLMs, the autoregressive nature of Transformers necessitates token-by-token generation, resulting in significant reliance on loading historical Key-Value (KV) caches. This process, constrained by High Bandwidth Memory (HBM) capacities, leads to frequent GPU cache misses, invoking high-latency data transfers and subsequent warping stalls. Profiling analyses of the XFormers attention kernel highlight three main bottlenecks: suboptimal GPU utilization, poor cache hit rates, and persistent warp stalls. The GPU cache hierarchy and the intrinsic inefficiencies underlie these issues, pointing to the urgent need for more efficient bandwidth utilization.
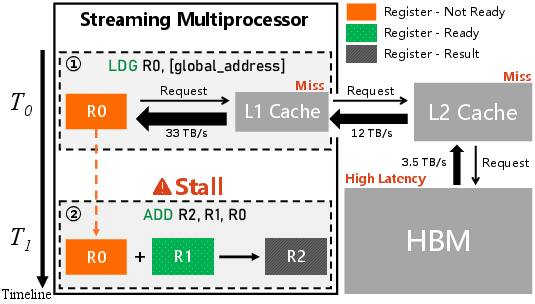
Figure 1: Schematic illustration of Stall Long Scoreboard event in NVIDIA GPU.
The Proposed Method
The core strategy of the proposed method relies on leveraging NVIDIA's L2 cache capabilities, using a hardware-software co-design approach to proactively prefetch KV blocks. By strategically scheduling memory bandwidth usage within active computational cycles, it reduces the latency caused by off-chip memory accesses. The method uses asynchronous prefetching instructions tailored to the NVIDIA Hopper architecture, enabling consecutive iterations to benefit from cache hits and thereby significantly reducing stall-induced inefficiencies.
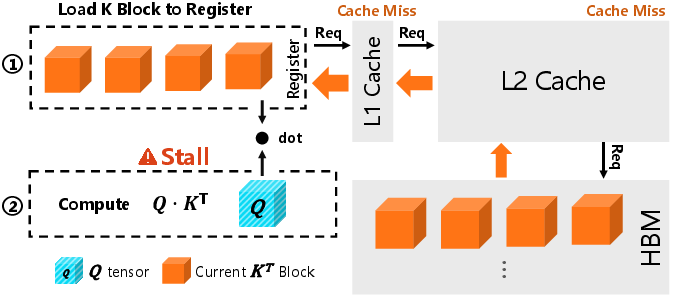
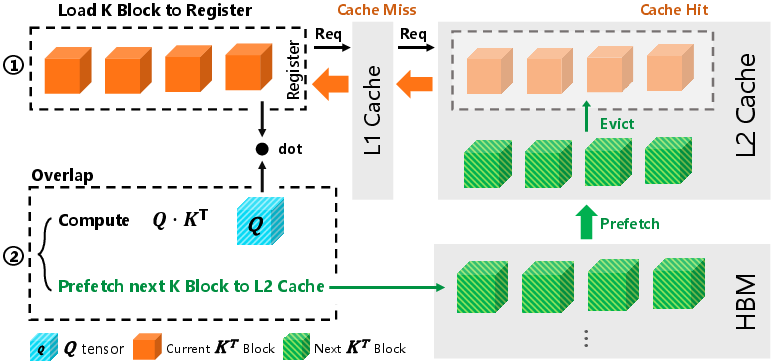
Figure 2: Q⋅KT computation flow in a single iteration for native XFormers and the proposed method, illustrated with a thread block configuration containing 4 warps.
Experimentation and Results
Experiments conducted on NVIDIA H20 GPUs with various open-source LLMs such as Llama2-7B revealed substantial performance improvements. Compared to the native XFormers backend, the prefetch approach increased computational efficiency in attention kernels by up to 2.15x and overall throughput by 1.97x. Metrics like compute and memory throughput were more than doubled. Furthermore, the proposed method surpassed the FlashAttention-3 baseline in most configurations, underlining its potential for broader application.
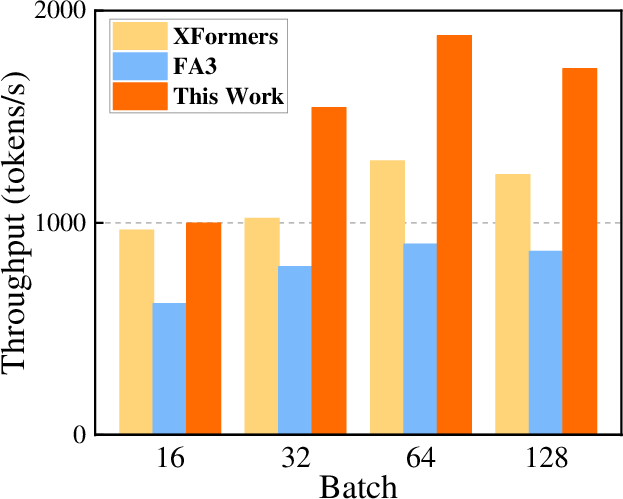
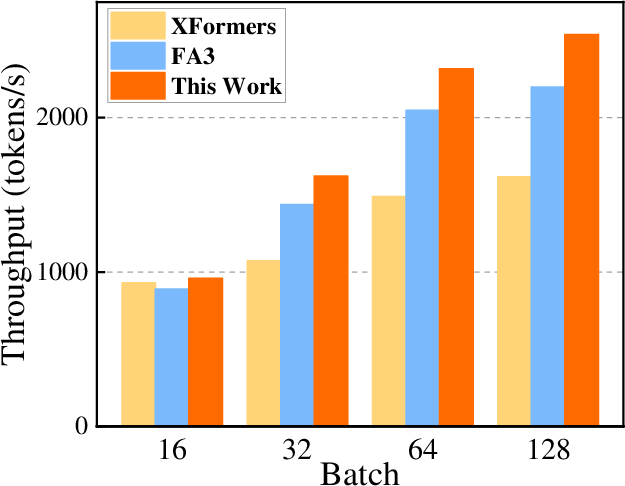
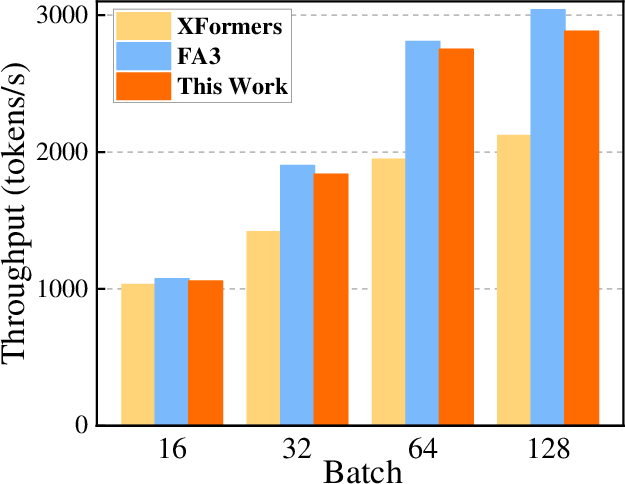
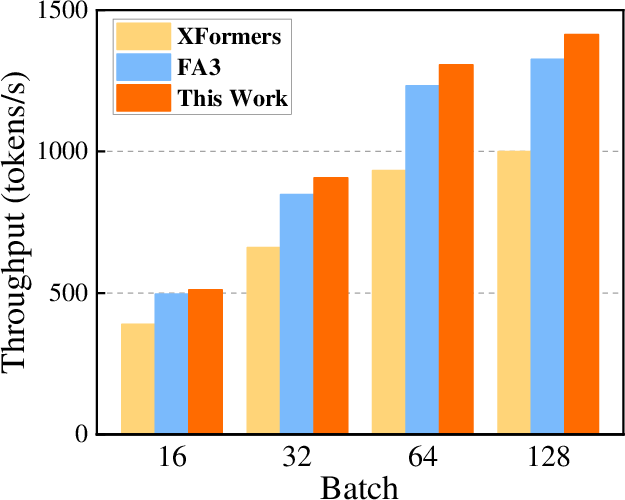
Figure 3: Single-GPU end-to-end inference throughput comparison across backends with fixed 2048 output tokens on H20.
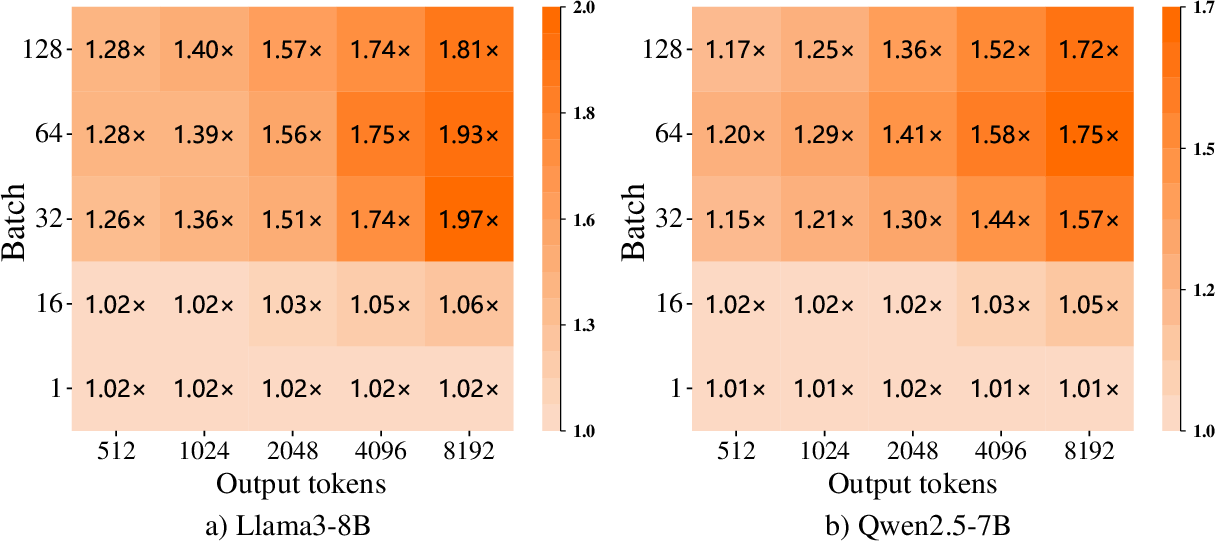
Figure 4: Speedups of the proposed method over native XFormers across varying batch sizes and output sequence lengths, evaluated on a single NVIDIA H20 GPU.
Implications and Future Directions
This study substantiates the feasibility of prefetching strategies to mitigate LLM inference bottlenecks attributed to memory bandwidth. The integration of such asynchronous operations into existing frameworks allows for a scalable solution that capitalizes on current hardware capabilities. Given its supportive nature, this approach can be amalgamated with other state-of-the-art techniques, laying the groundwork for future generations of LLM inference engines. Future research must explore adaptive scheduling strategies and expanded architectural support to further refine and enhance these capabilities.
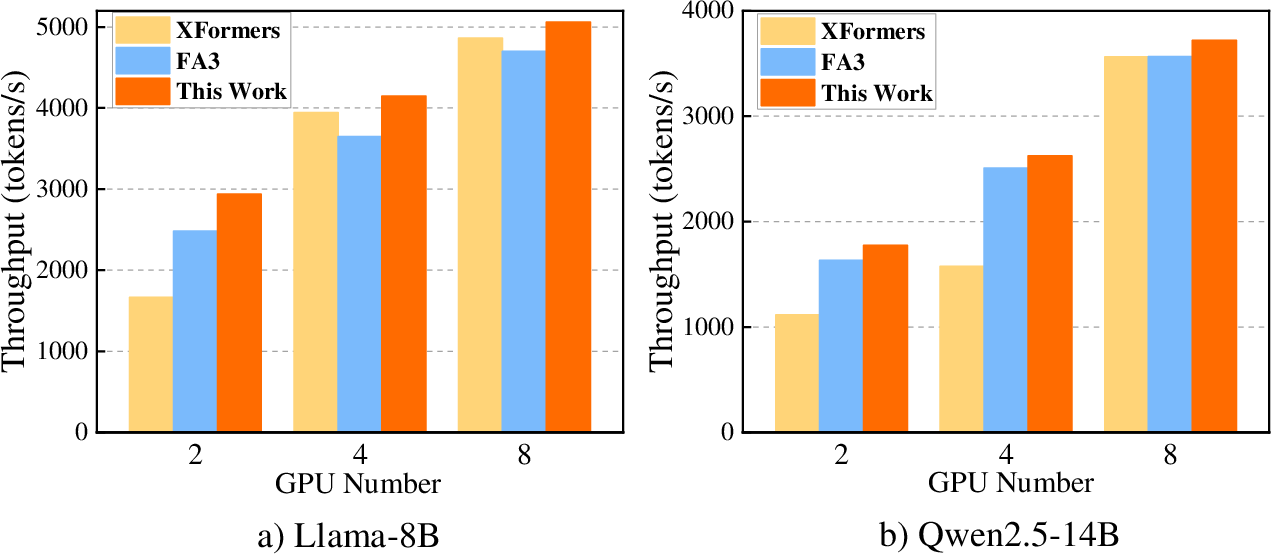
Figure 5: Multi-GPU end-to-end inference throughput comparison across backends under fixed 4096 output tokens with batch size 64, benchmarked on NVIDIA H20 GPUs.
Conclusion
The paper introduces a novel method leveraging asynchronous KV Cache prefetching to significantly enhance LLM inference throughput. By effectively overlapping data loading and computation, the method addresses memory bandwidth constraints, achieving scalable performance improvements across diverse models and configurations. These findings open avenues for further research into cache-focused optimizations in high-performance computing contexts.
The method provides a robust foundation for future work aimed at optimizing inference workflows and enhancing the capabilities of LLMs in various real-world applications.

