- The paper demonstrates that reordering in Multi-head Latent Attention increases arithmetic intensity and throughput, shifting LLM bottlenecks.
- It analyzes how Mixture-of-Experts optimizes batching and sparse activation, improving compute efficiency and resource utilization.
- The study highlights system-level trade-offs and recommends balanced hardware design to mitigate communication overhead in LLM serving.
Systems Perspective on Latent Attention and Mixture-of-Experts
The paper "The New LLM Bottleneck: A Systems Perspective on Latent Attention and Mixture-of-Experts" (2507.15465) challenges the conventional focus on optimizing Multi-Head Attention (MHA) in LLMs. It posits that architectural innovations like Multi-head Latent Attention (MLA) and Mixture-of-Experts (MoE) have fundamentally altered the computational landscape, shifting the bottleneck from memory-bound attention to a more balanced system-level problem.
Background and Motivation
Traditional LLMs based on the Transformer architecture consist of MHA and Feedforward Network (FFN) blocks. MHA is characterized by low arithmetic intensity (a.i.), making it memory-bound, while FFN layers are compute-bound. This disparity has driven research toward specialized hardware for attention acceleration. Recent trends in LLM design, however, incorporate MLA, which reduces the memory footprint of attention, and MoE, which increases model capacity without a proportional rise in compute cost. The paper argues that these changes necessitate a re-evaluation of LLM serving strategies and hardware priorities.
Key Observations and Contributions
The paper makes two central observations. First, MLA significantly increases the a.i. of attention, bringing it closer to the compute-bound regime suitable for modern accelerators. Second, MoE, when combined with the increased batch sizes enabled by MLA, can achieve a.i. close to the ridge point of accelerators in its expert FC layers. These observations lead to the conclusion that the focus should shift from specialized attention hardware to designing balanced systems capable of handling the diverse demands of large-scale models. The key contributions are:
- Demonstrating that layer reordering in MLA increases the a.i. of core attention, enabling larger batch sizes and higher throughput.
- Analyzing MoE execution and identifying the batch size required to match the Op/B of expert FC layers, while considering memory and latency constraints.
- Presenting an end-to-end analysis of LLM serving systems, highlighting how MLA, MoE, and interconnect bandwidth together enable efficient, scalable inference.
Multi-Head Latent Attention (MLA)
MLA reduces the memory footprint of attention by applying a low-rank joint compression to the Query (Q), Key (K), and Value (V) matrices. This compression is achieved by projecting the hidden state matrix into a latent space, forming compressed Q (CQ) and compressed KV (CKV) matrices. These compressed matrices are then decompressed to reconstruct the full Q, K, and V matrices used in the core attention computation.
\
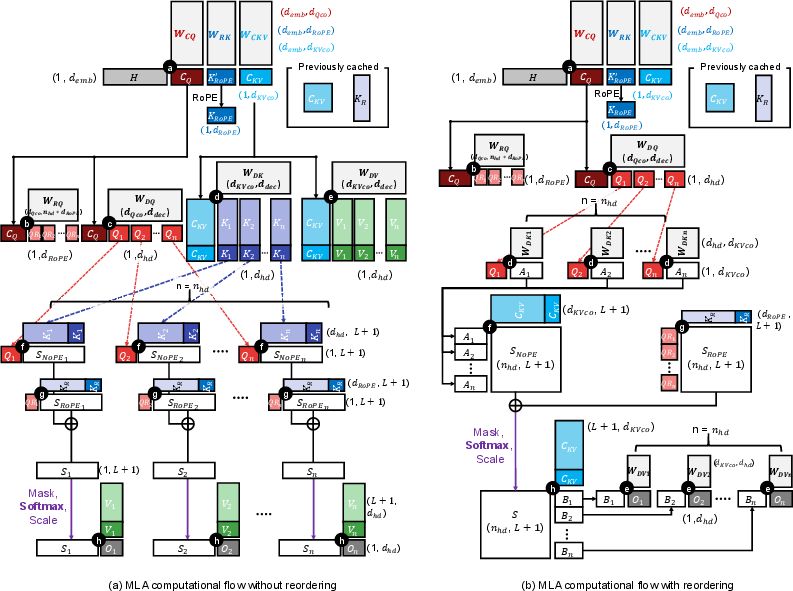
Figure 1: Computation flow of multi-head latent attention (MLA) with/without layer reordering.
A key feature of MLA is the decoupling of Rotary Positional Embedding (RoPE), which enables reordering of the attention block's layers. This reordering transforms the score and context layers from GEMV to GEMM operations, improving data reuse and increasing a.i. Table 2 in the paper compares the FLOPs and memory requirements of the reordered and non-reordered MLA, highlighting the benefits of reordering for the decode stage. Reordering drastically reduces the latency of attention blocks during the decode stage, whereas it rather increases the latency during the prefill stage.
Figure 2 shows the normalized latency of the attention block in the decode stage with and without reordering.
\
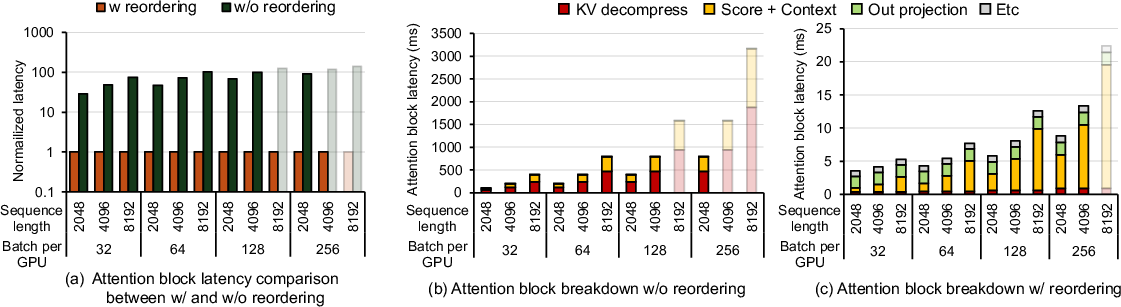
Figure 2: (a) Normalized latency of the attention block in the decode stage without reordering compared to a reordered Attention block. (b) and (c) shows execution time ratio of each layer in the attention block in the decode stage with and without reordering, across varying sequence length and batch size.
\
The paper finds that TP offers little latency benefit once reordering is applied in the attention block because all heads share the same CKV, and the capacity benefit from TP diminishes. As TP reduces the number of heads batched on each accelerator, the a.i. is reduced.
Mixture-of-Experts (MoE)
MoE enhances LLM scalability by sparsely activating a subset of experts for each token. This allows for larger model capacity without proportional increases in computation. Recent LLMs adopt a hybrid architecture with shared and routed experts. The computational procedure of an MoE block can be described as Router(u)=E∈{1,2,⋯,ne},∣E∣=nk<ne and $\text{MoE}(\mathbf{u})\!=\! (\sum_{e \in \mathbf{E} \text{Expert}_{e}(\mathbf{u}))\! +\! \text{Expert}_\mathrm{shared}(\mathbf{u})$. The values of nk and ne vary across different models.
Hardware Efficiency and Arithmetic Intensity
The paper emphasizes the importance of arithmetic intensity (a.i.) in LLM serving. a.i. is the ratio of arithmetic operations to memory access, measured in operations per byte (Op/B). The ridge point of an accelerator defines the a.i. at which performance transitions from being memory-bound to compute-bound. To fully exploit an accelerator's capabilities, the a.i. of each model layer should approach this ridge point. The paper shows that MLA and MoE can shift the a.i. of LLM layers closer to the ridge point of modern accelerators.
\
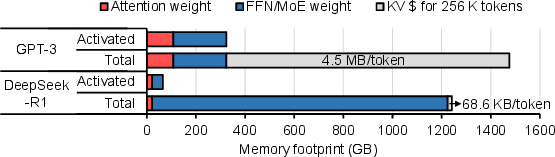
Figure 3: Memory usage comparison of DeepSeek-R1 and GPT-3, including attention weight, FFN/MoE weight, and the KV\$ for 256K tokens with BF16 precision.
Figure 3 compares the number of activated parameters per token between DeepSeek-R1, which employs a MoE network, and GPT-3 that uses a dense FFN.
End-to-End Model Execution Analysis
The paper analyzes the end-to-end execution of modern LLMs, evaluating how the interplay between MLA, MoE, system scale, and interconnect bandwidth determines overall serving performance. LLMs using MLA and MoE achieve significantly higher throughput than conventional models. MLA's highly-compressed KV\$ dramatically increases the memory capacity available for batching, which, in turn, allows the system to form the large batches required to fully utilize the compute resources of the sparsely activated experts in MoE blocks.
\
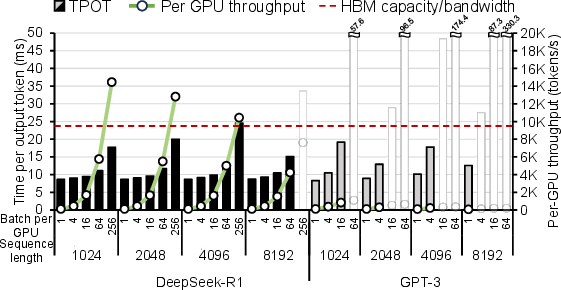
Figure 4: Time per output token and per-device throughput of DeepSeek-R1 and GPT-3 across varying sequence length and batch size.
\
Figure 4 illustrates this by comparing DeepSeek-R1 and GPT-3. This comparison reveals an impressive throughput improvement of up to 53.67×, alongside a notable increase in the maximum feasible batch size (B).
\
However, scaling the system out introduces a new trade-off. Increasing the number of accelerators to raise the memory capacity limit also increases the batch size required to saturate the attention blocks. The paper finds that the performance of a scaled-out MoE-based system is highly sensitive to interconnect bandwidth, as the all-to-all communication pattern required to dispatch every token to its designated experts can easily become a bottleneck.
Implications and Future Directions
The paper's findings have significant implications for the design of LLM serving systems. The diminishing need for specialized attention hardware suggests that future research should focus on holistic system-level optimizations. This includes:
- Balancing compute, memory capacity, and memory bandwidth to match the diverse demands of MLA and MoE.
- Developing efficient data parallelism strategies for reordered MLA.
- Utilizing high-bandwidth interconnects to mitigate communication overhead in MoE-based systems.
Further research could explore novel hardware architectures that cater to the specific computational characteristics of MLA and MoE. This may involve designing accelerators with high memory bandwidth and specialized support for sparse computations. Additionally, optimizing communication protocols and network topologies could further improve the scalability and efficiency of LLM serving systems.
Conclusion
The paper "The New LLM Bottleneck: A Systems Perspective on Latent Attention and Mixture-of-Experts" (2507.15465) provides a valuable systems-level perspective on the evolving landscape of LLM serving. By highlighting the impact of MLA and MoE on the computational characteristics of LLMs, the paper challenges conventional wisdom and points toward new directions for hardware and system design. The findings emphasize the importance of holistic optimization strategies that consider the interplay between algorithmic innovations, hardware capabilities, and system-level parameters.