- The paper introduces a novel Flash Sparse Attention kernel that reorders computation loops to eliminate padding overhead.
- It achieves substantial performance gains with up to 3.5× lower kernel latency and up to 6.4× lower latency for long-context inference.
- System-level optimizations using Triton reduce memory access and enable efficient online softmax, all while preserving model accuracy.
Flash Sparse Attention: Efficient Native Sparse Attention Kernel for Modern LLMs
Introduction
The paper introduces Flash Sparse Attention (FSA), a hardware-efficient kernel implementation for Native Sparse Attention (NSA) tailored to modern LLMs with small Grouped Query Attention (GQA) group sizes. NSA, while algorithmically effective for long-context LLMs, suffers from significant inefficiencies on GPUs when GQA group sizes are small—a common configuration in contemporary models. FSA addresses this by reordering the kernel computation loops and introducing system-level optimizations, resulting in substantial reductions in kernel latency, end-to-end training, and inference times, without compromising model accuracy.
Background: Sparse Attention and System Bottlenecks
Sparse attention mechanisms, such as NSA, reduce the quadratic complexity of full attention by allowing each query to attend to a subset of keys. NSA achieves this via three parallel modules: compressed, selected, and sliding attention. The selected attention module, which dynamically selects key-value (KV) blocks per query, is the primary system bottleneck due to its irregular memory access patterns and hardware misalignment, especially at small GQA group sizes. NSA's kernel batches query heads sharing the same KV head, but when the group size is small, it must pad to meet hardware requirements, leading to wasted computation and memory bandwidth.
FSA Kernel Design and Implementation
FSA's core innovation is the inversion of the two-level loop in the selected attention kernel. Instead of iterating over queries in the outer loop and KV blocks in the inner loop (NSA's approach), FSA iterates over KV blocks in the outer loop and batches all queries attending to a given KV block in the inner loop. This eliminates the need for padding, as the number of queries per KV block typically exceeds the hardware threshold, ensuring efficient matrix multiplication without unnecessary computation.
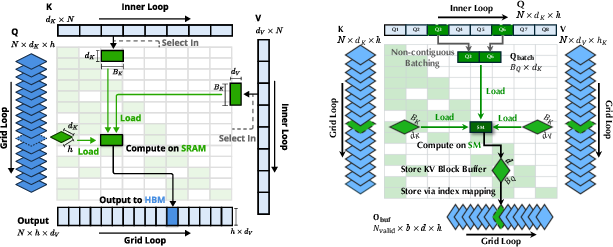
Figure 1: Illustration of NSA (left) and FSA (right) selected attention kernel loop order. FSA batches non-contiguous queries per KV block, eliminating padding overhead.
This reordering introduces two main challenges:
- Non-contiguous memory access: Query batches are non-contiguous, reducing L2 cache efficiency.
- Online softmax and accumulation: Attention scores for a query are computed across multiple KV blocks, requiring careful reduction and normalization.
FSA addresses these with:
- Index tensors for efficient non-contiguous query loading and early return mechanisms to avoid unnecessary memory access.
- Decoupled online softmax and reduction kernels: Partial results are written to intermediate buffers, and a dedicated reduction kernel accumulates and normalizes outputs, avoiding atomic operations.
The implementation leverages Triton for fine-grained control over thread block and warp-level parallelism, optimizing both compute and memory access patterns.
Theoretical Analysis
FSA reduces both memory access volume and FLOPs compared to NSA, especially at small GQA group sizes. For example, with GQA=4, block size BK=64, and top-k T=16, FSA reduces memory access to 21.3% and FLOPs to 56.2% of NSA's requirements. This is achieved by eliminating padding and ensuring all loaded KV data is used in computation.
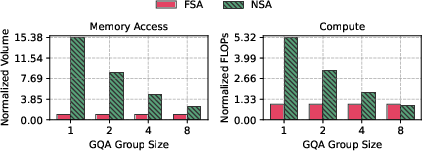
Figure 2: Memory access volume comparison between FSA and NSA across GQA group sizes, normalized to FSA.
Profiling and Kernel Benchmarks
Empirical profiling on NVIDIA H20 and H200 GPUs confirms the theoretical advantages. FSA achieves up to 3.5× and on average 1.6× lower kernel latency than NSA, and up to 6.4× lower latency than full attention for long sequences and small GQA group sizes.
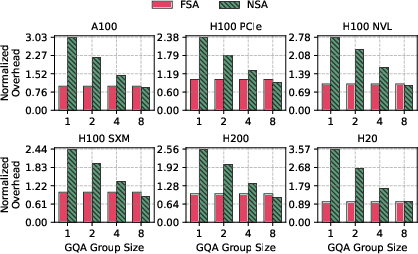
Figure 3: Real-time profiling of FSA and NSA kernel execution overhead across GPUs, with FSA latency normalized to 1.
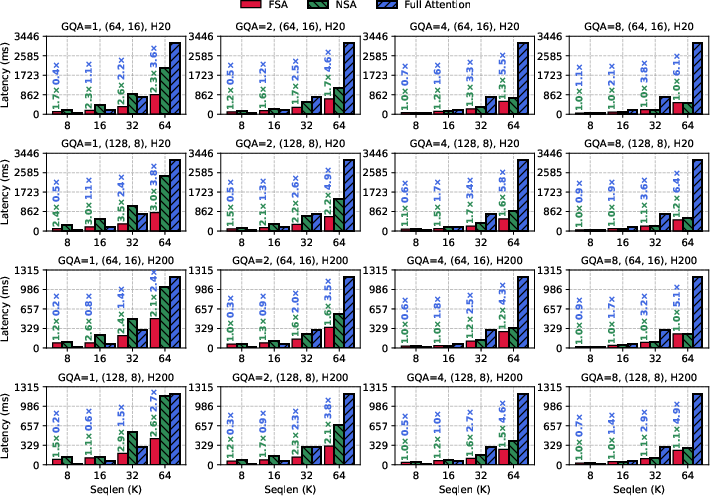
Figure 4: Kernel-level performance comparison of FSA, NSA, and full attention under various configurations.
Training and Inference Latency
FSA consistently outperforms NSA and full attention in end-to-end training and inference across Llama3-8B, Qwen3-14B, and Qwen2.5-32B models. For training, FSA achieves up to 1.25× and on average 1.09× speedup over NSA, and up to 2.47× over full attention. For inference prefill, FSA achieves up to 1.36× and on average 1.11× speedup over NSA, and up to 1.69× over full attention.
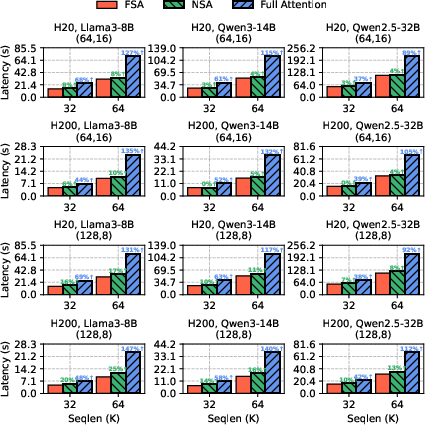
Figure 5: End-to-end training latency comparison for FSA, NSA, and full attention.
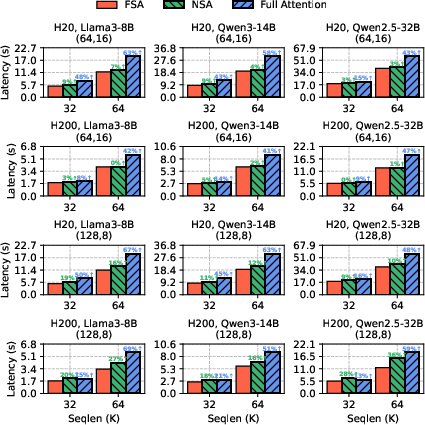
Figure 6: Prefill latency comparison for FSA, NSA, and full attention.
Detailed Breakdown and Ablation
The selected attention phase dominates total attention computation time, accounting for up to 79% of the overhead. FSA delivers up to 7.6× speedup in this phase. Ablation studies show that disabling FSA's inner loop optimization or early return mechanism degrades performance by up to 18.9% and 25.2%, respectively.
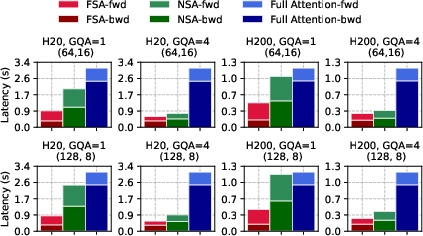
Figure 7: Forward and backward computation latency breakdown for FSA, NSA, and full attention.
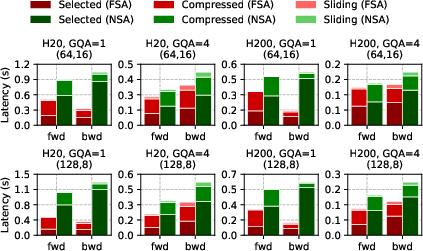
Figure 8: Breakdown of selected, compressed, and sliding attention overhead in forward and backward passes.
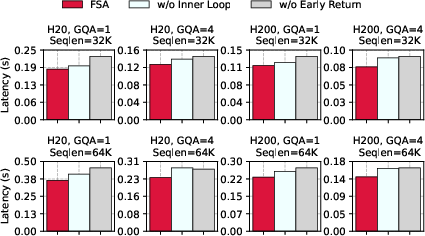
Figure 9: Ablation study on FSA selected attention kernel, quantifying the impact of each optimization.
Correctness and Convergence
Loss curves for Llama3-8B fine-tuning show that FSA matches NSA and full attention in convergence behavior, confirming correctness.
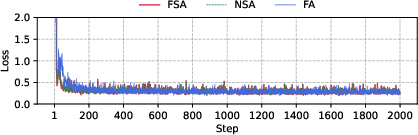
Figure 10: Loss comparison between FSA, NSA, and full attention during Llama3-8B training.
Source of Speedup
End-to-end breakdowns confirm that FSA's speedup is localized to the attention computation, with up to 1.4× lower latency than NSA and up to 3.87× over full attention in this component.
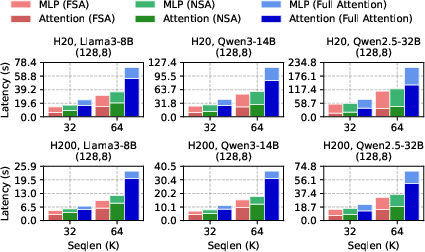
Figure 11: Computation time breakdown for attention and MLP during end-to-end training.
Implementation Considerations
- Buffer Overhead: FSA introduces intermediate buffers for partial results, but the memory overhead is manageable on modern GPUs (e.g., 1GB for 64K tokens, T=16, d=128).
- Non-contiguous Access: While FSA's non-contiguous query loading is less cache-efficient, the overall reduction in memory volume and FLOPs compensates for this.
- Scalability: FSA is robust across a range of GQA group sizes, block sizes, and sequence lengths, and is implemented in Triton for portability and extensibility.
- Deployment: FSA is suitable for both training and inference in long-context LLMs, and the open-source implementation facilitates integration into existing model stacks.
Implications and Future Directions
FSA demonstrates that algorithm–system co-design is essential for realizing the practical benefits of sparse attention. By aligning kernel design with hardware constraints, FSA enables the deployment of efficient sparse attention in modern LLMs, particularly those with small GQA group sizes. This work suggests several future directions:
- Further hardware-specific optimizations for emerging GPU architectures.
- Extension to other forms of dynamic sparsity and integration with quantization or mixed-precision techniques.
- Exploration of FSA in distributed and heterogeneous environments for large-scale training and inference.
Conclusion
Flash Sparse Attention provides an efficient, hardware-aligned kernel for NSA, enabling practical sparse attention in modern LLMs with small GQA group sizes. Through loop reordering and targeted system optimizations, FSA achieves substantial speedups in both kernel and end-to-end performance, without sacrificing model accuracy. This work underscores the importance of bridging algorithmic advances with system-level implementation to unlock the full potential of efficient attention mechanisms in large-scale LLMs.

