UltraCUA: A Foundation Model for Computer Use Agents with Hybrid Action
Abstract: Multimodal agents for computer use rely exclusively on primitive actions (click, type, scroll) that require accurate visual grounding and lengthy execution chains, leading to cascading failures and performance bottlenecks. While other agents leverage rich programmatic interfaces (APIs, MCP servers, tools), computer-use agents (CUAs) remain isolated from these capabilities. We present UltraCUA, a foundation model that bridges this gap through hybrid action -- seamlessly integrating GUI primitives with high-level programmatic tool calls. To achieve this, our approach comprises four key components: (1) an automated pipeline that scales programmatic tools from software documentation, open-source repositories, and code generation; (2) a synthetic data engine producing over 17,000 verifiable tasks spanning real-world computer-use scenarios; (3) a large-scale high-quality hybrid action trajectory collection with both low-level GUI actions and high-level programmatic tool calls; and (4) a two-stage training pipeline combining supervised fine-tuning with online reinforcement learning, enabling strategic alternation between low-level and high-level actions. Experiments with our 7B and 32B models demonstrate substantial improvements over state-of-the-art agents. On OSWorld, UltraCUA models achieve an average 22% relative improvement over base models, while being 11% faster in terms of steps. Out-of-domain evaluation on WindowsAgentArena shows our model reaches 21.7% success rate, outperforming baselines trained on Windows data. The hybrid action mechanism proves critical, reducing error propagation while maintaining execution efficiency.


Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
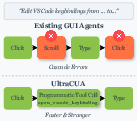
This paper introduces UltraCUA, a smart computer helper (an “agent”) that can use a computer in two ways at the same time:
- like a person, by clicking, typing, and scrolling on the screen, and
- like a programmer, by calling powerful shortcuts and tools that do many steps in one go.
This mix is called hybrid action. It helps the agent finish tasks faster and with fewer mistakes.
What questions are the researchers asking?
In simple terms, they ask:
- Can we make computer-use agents both careful and fast by letting them mix low-level actions (clicks) with high-level commands (tools)?
- How can we give these agents a big, reliable toolbox without writing everything by hand?
- Can we teach agents on realistic, checkable practice tasks so they learn when to click and when to use a tool?
- Will this approach work across different apps and even different operating systems (like Ubuntu and Windows)?
How did they do it?
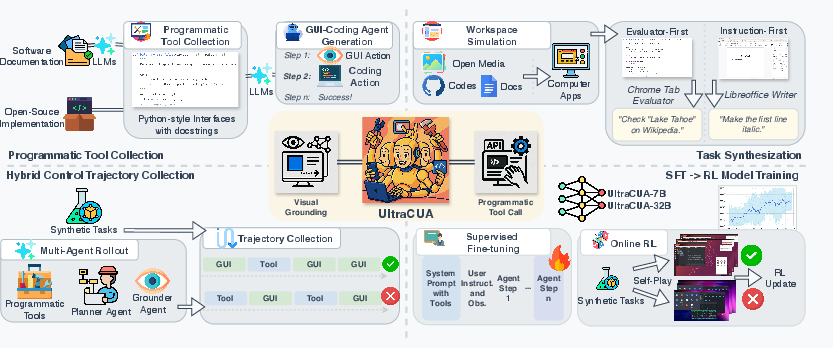
The team built UltraCUA with four main parts. Here’s the idea in everyday language:
- They first created a big set of tools the agent can call directly (like built-in shortcuts or small programs) so it doesn’t always need to click through menus.
- They generated a large number of realistic, verifiable practice tasks so the agent can learn safely and get clear feedback.
- They collected many example “how to do it” recordings that combine both clicking and tool use, so the agent sees good strategies.
- They trained the agent in two stages: first by copying good examples, then by improving through trial and error.
Building a bigger toolbox
To avoid doing everything by mouse and keyboard, the agent can call tools—small functions that do multi-step actions quickly (like “set spreadsheet cells,” “open bookmarks manager,” or “change VS Code theme”). The team grew this toolbox by:
- extracting shortcuts and features from app documentation (turning, say, “Ctrl+K, Ctrl+T” into a function like vscode.set_theme()),
- integrating open-source tools already available, and
- having a coding helper write new tools when needed, then packaging those into reusable functions.
Think of it like teaching the agent both how to use the menu and how to use hotkeys or scripts that finish jobs in one move.
Creating lots of practice tasks
Agents learn best with many practice problems that come with answer checks. The team made 17,000+ tasks using two strategies:
- Evaluator-first: they built small “checkers” (like “is this file here?” or “is Chrome on this URL?”), then asked an AI to write tasks that would satisfy those checks. This guarantees tasks can be automatically verified (like a built-in answer key).
- Instruction-first: they let an agent explore real apps and screens, then asked for tasks that fit the current context (like “create a new spreadsheet”). Another agent checks whether the task was done correctly. This adds variety and real-world feel.
They also prepared realistic content (real images, code files, documents) so tasks match what people do in everyday computer work.
Teaching the agent
Training happened in two steps:
- Supervised fine-tuning (SFT): The agent learns by example from 26.8K successful “trajectories” (step-by-step solutions) produced by a planner and a grounder working together:
- Planner (reasoner): decides the next move and whether to click or call a tool.
- Grounder (precise clicker): finds the exact spot on the screen to click or the right GUI element to interact with.
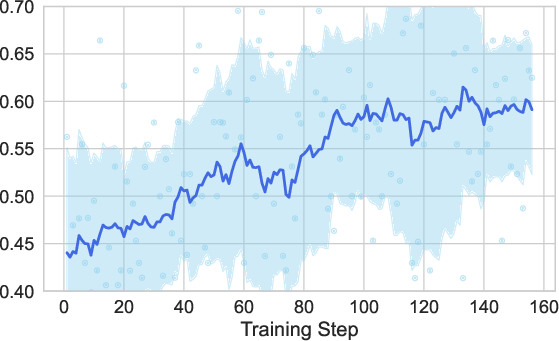
- Reinforcement learning (RL): The agent then practices on the verifiable tasks, gets a reward when it succeeds, and learns to be smarter about when to use tools (it even gets a small bonus when it uses tools effectively). This is like playing a game and learning what strategies score more points.
They also gave the agent a simple “working memory,” a short, structured note to itself like:
- task goal,
- steps already completed,
- things it needs to remember (like a file path), so it doesn’t lose track in multi-step tasks.
What did they find?
Overall, hybrid action makes agents both stronger and faster.
Here are the key results:
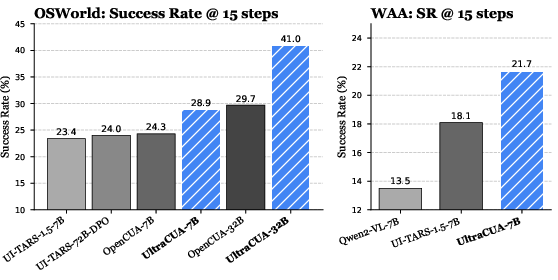
- On OSWorld (a tough benchmark of real desktop tasks on Ubuntu):
- The 7B model improved from 23.4% to 28.9% success when allowed to use hybrid actions (a 23%+ relative gain).
- The 32B model reached 41.0% success, beating several strong baselines.
- It also needed about 11% fewer steps on average, showing better efficiency.
- On WindowsAgentArena (Windows tasks), even without Windows-specific training, the 7B model scored 21.7% success, beating other models that were trained on Windows data. This shows the skills transfer across operating systems.
- Ablation studies (controlled tests) showed:
- Hybrid action clearly outperforms click-only behavior.
- Reinforcement learning makes the agent more selective: it uses tools when helpful and avoids tool calls that cause errors.
- Working memory provides small but steady improvements, especially for multi-step tasks.
- Tool use patterns:
- Stronger models use tools more often and with more variety, suggesting they better “sense” when a tool will save time and reduce errors.
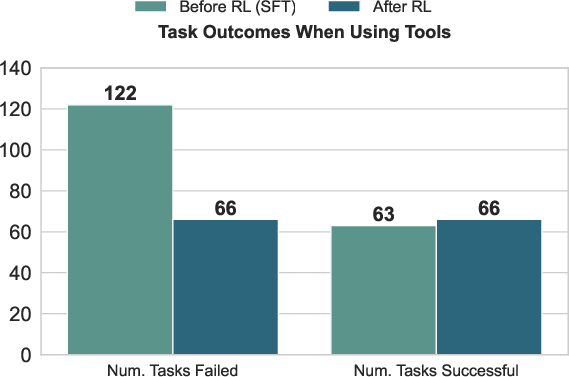
Why this matters: Using only clicks can cause “cascading failures,” where one wrong click ruins the whole task. With tools, the agent can do big steps safely and quickly, reducing the chance of messing up.
Why does this matter?
UltraCUA shows a practical path to reliable, everyday computer helpers that:
- can handle many apps (browsers, spreadsheets, code editors, image tools),
- finish tasks faster by mixing clicks with smart commands,
- make fewer mistakes on long, complex tasks,
- and transfer their skills to new environments (like from Ubuntu to Windows).
In the future, this could power more trustworthy personal assistants, office automation, and accessibility tools—agents that not only “see and click” but also know the right shortcuts and scripts to get things done quickly and safely.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, concrete list of what remains missing, uncertain, or unexplored in the paper. Each item is phrased to be directly actionable for future research.
- Quantify real-world robustness beyond deterministic benchmarks: test resilience to UI changes (theme, DPI, layout shifts), pop-ups, network delays, localization (non-English UIs), multi-monitor setups, and non-determinism that frequently causes GUI agents to fail.
- Measure wall-clock latency and resource consumption: report runtime, tool-call overhead, GPU/CPU utilization, and energy across tasks, not just step counts, to substantiate efficiency claims and inform deployment costs.
- Long-horizon, multi-session workflows: evaluate tasks requiring 100–200+ steps, cross-application sequences with background/asynchronous operations, and persistence across sessions (including reboots, scheduled tasks, or delayed system responses).
- Safety, security, and permissions for programmatic tools: design and evaluate sandboxing, permission gating, auditing/logging, dry-run/rollback mechanisms, and policies preventing destructive or privacy-violating actions (e.g., file deletion, data exfiltration, credential handling).
- Tool coverage assessment and completeness: provide a quantitative coverage map of supported actions across applications/OSs; identify gaps (e.g., macOS, enterprise tools, non-Chrome browsers, CAD/creative suites) and a systematic strategy for prioritizing tool acquisition.
- Automatic tool maintenance and validity checks: create monitoring to detect app updates that invalidate shortcuts/APIs, auto-regenerate/upsert tools, and verify continued correctness with regression tests.
- Scaling tool discovery beyond context-length limits: integrate retrieval/indexing for thousands of tools (vector search over signatures/docstrings, schema-aware selection), and study how tool selection accuracy scales as the tool universe grows.
- Zero-shot adaptation to unseen tools: go beyond modest gains by evaluating few-shot tool instruction assimilation (docstring comprehension, schema adherence), parameter inference accuracy, and rapid learning curricula for new tool ecosystems.
- Tool parameter validation and syntax robustness: instrument static/dynamic checking for parameters (types, ranges, required fields), grammar enforcement, auto-correction loops, and quantify tool-call error rates over training.
- Decision policy interpretability: analyze and model when the agent chooses tools vs. GUI primitives (e.g., cost-aware policies, options/hierarchical RL), and derive measurable criteria for optimal hybrid switching.
- Failure taxonomy and error propagation metrics: systematically categorize common failure modes (grounding errors, tool misuse, parameter mismatches, state drift), and quantify cascade error reduction attributable to hybrid action.
- Working memory limitations: evaluate memory scalability, persistence across long tasks, interference/forgetting, consistency under modality switches, and applicability to multi-task concurrency; compare internal memory tags vs. external structured state stores.
- Dependence on closed-source planner (o3) for trajectory generation: assess biases/reproducibility risks, replicate collection with open planners, and quantify how trajectory quality and diversity change with different generator models.
- Synthetic task realism and evaluator fidelity: audit instruction-first tasks for realism and evaluator-first tasks for semantic completeness; measure evaluator false positives/negatives, leakage/cueing, and generalization of learned strategies to unverified real-world tasks.
- Data scale and distribution: 17k tasks/26.8k trajectories may be modest—study scaling laws (data volume vs. capability), domain balancing, and effects of distribution shift relative to real user workloads.
- RL training under-specified and small-scale: justify the 150-step budget, ablate reward designs (tool-use bonus magnitude, presence/absence of KL), study stability/exploration trade-offs, and compare against standard baselines (e.g., PPO, A2C, offline RL, self-play variants).
- Credit assignment for hybrid action: investigate step-level reward shaping for tool selection (e.g., penalties for redundant tool calls, rewards for risk-reducing actions) and formalize a cost/risk model for action choices.
- Joint training of grounding and planning: explore end-to-end training that fuses planner and grounder (rather than relying on GTA1-7B externally), and assess gains in visual grounding robustness under hybrid action.
- Benchmark breadth and fairness: standardize compute budgets, rollout counts, and infrastructure speed across baselines; extend evaluation to macOS, mobile (Android/iOS), and enterprise apps to test generality.
- Authentication and enterprise constraints: evaluate tasks with sign-ins, MFA, permission prompts, corporate proxies/policies, and admin privileges that commonly affect practical automation.
- Accessibility support: test and adapt to screen readers, high-contrast modes, keyboard-only navigation, and other accessibility settings that alter UI semantics and layout.
- Robust cross-platform generalization: while Windows results are promising, examine transfer to macOS and diverse Linux distros/desktops; quantify what hybrid strategies transfer and where they break.
- Tool–GUI concurrency and race conditions: study synchronization when tools modify state while GUI actions proceed (file handles, background processes), including detection and recovery from race-induced inconsistencies.
- OOD tool insertion methodology: detail how unseen tools are surfaced at inference, the retrieval/prompting strategy, and the exploration vs. exploitation dynamics that led to more steps; propose ways to minimize exploratory overhead.
- Action-level error rates and cascading failure reduction: provide quantitative evidence that hybrid action reduces the probability of action-level errors and downstream cascades, not just aggregate success improvements.
- License and compliance considerations: clarify licensing for integrated code/images/data; define policies for tool generation from third-party repositories and implications for distribution.
- User-in-the-loop recovery: design and evaluate interactive correction channels (clarification questions, partial rollback, alternative strategies) to mitigate failures mid-task.
- Formalization of hybrid action within RL/MDP frameworks: develop theoretical models (e.g., options/hierarchical MDPs) to analyze optimal hybrid policies, sample complexity, and convergence guarantees.
- Pass@k vs. interactive deployment reality: go beyond Pass@4 to simulate realistic retry policies and user-guided re-plans, measuring cumulative success under practical interaction budgets.
- Content-centric task understanding: assess performance on tasks requiring deep content comprehension (e.g., editing long documents, code review), including OCR/text-in-image reliability under GUI screenshots.
- Release and reproducibility details: provide containers/environment snapshots, seeds, prompts, tool schemas, and evaluator code to ensure end-to-end reproducibility of tool mining, task generation, trajectories, and training.
Practical Applications
Immediate Applications
Below are actionable use cases that can be deployed now or with minimal engineering, leveraging the paper’s hybrid action mechanism (mixing GUI primitives and high-level programmatic calls), automated tool extraction pipeline, synthetic verifiable task engine, working-memory prompting, and SFT/RL training recipe.
- Universal desktop copilot for cross-app workflows — software, enterprise IT, productivity
- Automate multi-application tasks (e.g., “pull KPIs from a browser dashboard, summarize in Calc/Excel, and email via Thunderbird/Outlook”) with tool-first, GUI-fallback execution that reduces steps and failure cascades.
- Potential product/workflow: A “Try tools → fallback to GUI” orchestration policy integrated into existing automation platforms.
- Dependencies: Secure OS-level control (keyboard/clipboard/windowing), application-specific tool registry, sandboxing, role-based access to files and network services.
- Hybrid RPA uplift for legacy apps — enterprise IT, finance, operations
- Augment existing RPA bots by mining app documentation to auto-generate high-reliability tool calls (e.g., shortcut-based operations), then fallback to GUI where APIs don’t exist.
- Potential product/workflow: A “tool extractor” that scrapes docs and codebases to synthesize callable functions (e.g., vscode.set_theme(), set_cell_values()) and auto-test them.
- Dependencies: Documentation availability and stability; integration with RPA orchestrators; regression tests for tool wrappers.
- Spreadsheet and document automation with fewer steps — finance, operations, education
- Replace brittle multi-click flows with high-level tools (e.g., set multiple cells, bulk formatting, export) while still supporting GUI-level edits (charts, selections).
- Potential product/workflow: A “Spreadsheet Command Kit” that exposes bulk write/read functions plus GUI selection where needed.
- Dependencies: Application-specific tool shims (Calc/Excel), file-system access, policy-compliant data handling.
- Developer environment automation inside IDEs — software engineering
- Invoke IDE tools (open project, switch theme, run tests, refactor files) via programmatic calls, only using GUI when needed (e.g., for UI prompts or extensions).
- Potential product/workflow: “IDE Workbench Agent” for VS Code and JetBrains with mined shortcuts and scripted settings (e.g., add_vs_code_keybinding).
- Dependencies: Stable CLI/shortcut interfaces, permission to write settings, CI/CD integration for auditability.
- QA and regression testing for desktop apps — software quality, DevOps
- Use evaluator-first tasks to create verifiable scenarios; combine tool calls (state setup) with GUI actions (interaction) for robust end-to-end tests.
- Potential product/workflow: A test generator that composes evaluators (file exists, URL open, setting applied) and produces repeatable test suites.
- Dependencies: Deterministic test environments, evaluator coverage for target apps, containerized OS images.
- IT helpdesk triage and reproduction — enterprise IT support
- Automatically reproduce user-reported issues by executing tool-first steps and GUI fallbacks, logging verifiable state checks to confirm outcomes.
- Potential product/workflow: “Case Replayer” that uses working memory (<memory> blocks) to persist intent, intermediate states, and reproductions.
- Dependencies: Secure remote session control, privacy filtering for sensitive data, audit logs.
- Accessibility and assistive computing — public sector, daily life
- Provide reliable, fewer-click assistance for routine tasks (file management, downloads, form filling) using tool shortcuts; GUI fallback maintains universality across unfamiliar apps.
- Potential product/workflow: Desktop accessibility copilot configurable with per-app tool packs.
- Dependencies: OS accessibility APIs, user consent flows, localization for different UI languages.
- Email and calendar admin tasks — operations, sales, customer success
- Programmatically manage folders/rules/labels where available; resort to GUI to handle provider-specific quirks; verify outcomes via evaluator scripts.
- Potential product/workflow: “Inbox Manager” that enforces org-wide hygiene rules (folder structure, archiving) with verifiable checks.
- Dependencies: Account permissions, rate limits, compliance with retention policies.
- Cross-platform agent evaluation and training data — academia, MLOps
- Reuse the paper’s dual synthetic data engine to generate verifiable tasks for benchmarking and fine-tuning other CUAs; directly adopt working-memory prompting and SFT-RL recipe.
- Potential product/workflow: A public benchmark suite (OSWorld-like) plus a “task synthesizer” service for labs/teams.
- Dependencies: Access to OS images, evaluator library, GPU time for SFT/RL; alignment with licensing terms of datasets/tools.
- Browser-intensive workflows with hybrid control — marketing, research, OSINT
- Use programmatic URL/state checks and downloads with GUI navigation for complex sites; reduce brittleness and steps.
- Potential product/workflow: “Web-to-Workspace” agent for research curation: fetch docs, save to folders, log citations.
- Dependencies: Network/firewall rules, site TOS compliance, download directory access.
- No-code macro builder with automatic toolization — daily life, SMBs
- Observe a user flow and synthesize parameterized tools via the coding-agent mining pipeline; next runs are one-call operations with GUI only for un-toolable steps.
- Potential product/workflow: “Auto-macro from demo” that outputs callable functions and unit tests.
- Dependencies: Recording permission, script execution policy, simple review/approval UI for generated tools.
- Policy and compliance setting verification on endpoints — policy, IT governance
- Compose evaluators (OS settings, browser configs, file paths) to check compliance; perform remediation via tool calls then confirm success.
- Potential product/workflow: “Policy Fix-and-Verify” playbooks with auditable state checks.
- Dependencies: Endpoint management rights, change control, security review for automated remediation.
Long-Term Applications
These use cases require additional research, scaling, productization, or organizational change (e.g., broader tool ecosystems, safety/controls, on-device deployment).
- Enterprise-grade agent platform with governed tool store — enterprise IT, platform engineering
- Standardize a curated marketplace of programmatic tools mined from vendor docs and code; enforce policy, sandboxing, telemetry, and approval workflows.
- Dependencies/assumptions: Vendor buy-in for “agent-ready” docs, stable tool schemas, enterprise identity and secrets management, comprehensive observability.
- Autonomy in high-stakes domains (EHRs, ERP, CRM) via hybrid action — healthcare, finance, operations
- Safely orchestrate actions across complex systems (EHR chart updates, ERP postings, CRM batch cleanups) using tool-first calls where available.
- Dependencies/assumptions: Strong safety layers, change windows, human-in-the-loop gating, domain-specific evaluators, HIPAA/GDPR/SOX compliance.
- Live, in-the-wild RL to optimize workflows — MLOps, productivity at scale
- Extend the paper’s online RL with outcome/tool-use rewards to real user tasks, learning organization-specific “best-first” strategies across apps.
- Dependencies/assumptions: Safe exploration policies, rollback, offline evaluation, reward engineering, privacy-preserving logs.
- Autonomous UI explorer and API synthesizer — software, ISVs
- Use hybrid agents to discover latent affordances in apps, then synthesize robust tool wrappers and tests automatically (from exploratory GUI traces and code paths).
- Dependencies/assumptions: App instrumentation hooks, permission to crawl UIs, code synthesis guardrails, continuous verification.
- Cross-OS, multilingual, and modality-general CUAs — global enterprises, public sector
- Scale from Ubuntu/Windows to macOS, localized UIs, and more app domains by expanding tool inventories and strengthening OOD generalization.
- Dependencies/assumptions: Diverse training data, localization support, model capacity, durable visual grounding across themes and languages.
- On-device, privacy-preserving assistant — consumer devices, regulated industries
- Deploy compact 7B-class hybrids with a lightweight tool set and strict sandboxing for sensitive contexts.
- Dependencies/assumptions: Efficient inference on edge hardware, limited context windows (tool subset selection), local evaluators, battery/thermal constraints.
- Autonomous SOC analyst for GUI-based consoles — cybersecurity
- Triage alerts, pivot across browser dashboards/agents, run scripted checks (tools), and verify containment with evaluators.
- Dependencies/assumptions: Strict isolation, immutable logging, approval workflows, red/blue-team validation.
- Creative workflow copilot across design/media apps — media, marketing
- Combine tool calls (batch export, metadata edits) with GUI for fine-grained operations (layers, filters) in graphics/video editors.
- Dependencies/assumptions: Vendor APIs/shortcuts coverage, large-file handling, deterministic project setups for reproducible evaluators.
- Government digital service automation and auditing — policy, public services
- Automate form processing, records updates, and compliance verification across heterogeneous systems with verifiable evaluators.
- Dependencies/assumptions: Procurement of agent-ready tool packs from agencies/vendors, stringent audit trails, accessibility mandates.
- Data pipeline bridging between desktop and cloud — data engineering, BI
- Hybrid agents that move data across local spreadsheets, browsers, and cloud dashboards, with evaluator-backed checks of data freshness and lineage.
- Dependencies/assumptions: Secure credentials handling, data classification, lineage tracking, policy-based egress controls.
- Standardized “agent-ready documentation” and tool schemas — software ecosystem
- Encourage ISVs to publish structured shortcuts/APIs with parameterized signatures, tests, and evaluators to plug into agents.
- Dependencies/assumptions: Industry standards (schema, versioning), backward compatibility, certification programs.
- Human-robot-computer loop for knowledge work — robotics, HRI
- Robots (or embodied agents) delegate screen-based tasks to CUAs with hybrid action, while handling physical tasks themselves.
- Dependencies/assumptions: Reliable inter-agent protocols, temporal coordination, safety interlocks, facility network constraints.
- Continuous UI reliability monitoring — SRE, product teams
- Agents periodically verify critical user flows (login, checkout, report export) using evaluators; escalate regressions with repro steps.
- Dependencies/assumptions: Stable staging environments, synthetic accounts/fixtures, SLA-linked alerting.
- Education: lab automation and grading assistants — education technology
- Set up coding labs, fetch datasets, grade artifacts via tool calls, and provide stepwise feedback with working memory.
- Dependencies/assumptions: Academic policy alignment, plagiarism checks, controlled network/file access, per-course tool packs.
- Safety-aligned agent governance and certification — policy, standards
- Develop certification processes for hybrid CUAs (sandboxes, explainability via memory traces, constrained tool budgets, evaluator coverage metrics).
- Dependencies/assumptions: Cross-industry standards bodies, reference audits/benchmarks, regulatory guidance on autonomous desktop actions.
Notes on Feasibility and Transferability
- Hybrid action is the core enabler: programmatic tools reduce steps and brittleness; GUI primitives ensure universality. The paper’s 22% relative SR improvement and 11% fewer steps indicate immediate efficiency gains in real workflows.
- Out-of-domain generalization (Ubuntu → Windows) suggests portable strategies across OSes, but tool inventories and grounding must be extended per platform.
- The automated tool-mining pipeline can be productized to keep tool stores fresh as apps evolve; correctness depends on unit tests/evaluators and vendor documentation quality.
- The dual synthetic data engine is key to scalable training/evaluation; in production, replace with organization-specific evaluators for reliable RL signals.
- Working-memory prompting (<memory> blocks) is low-effort to adopt in other agents and improves multi-step reliability without external state storage.
- Safety, compliance, and observability are essential dependencies for enterprise rollout: sandboxing, least-privilege execution, human-in-the-loop approvals, and audit logs should precede high-stakes use.
Glossary
- Agent-S2-style prompting: A prompting schema modeled after the Agent-S2 framework to improve reasoning in agent pipelines; e.g., "with Agent-S2-style prompting to enhance reasoning capabilities."
- Agentic Model: A model purpose-built or fine-tuned for autonomous computer-use tasks rather than general language understanding; e.g., "Agentic Model."
- Atomic verification functions: Minimal, programmatic checks that determine specific environment states for task verification; e.g., "collecting atomic verification functions (e.g., checking Chrome URLs, verifying file paths, validating image attributes)."
- Cascading failures: Errors that compound over long action sequences, causing downstream task failure; e.g., "leading to cascading failures and performance bottlenecks."
- clip-higher strategy: An RL optimization tweak that clips gradients or updates only when larger than a threshold to encourage exploration; e.g., "implement a clip-higher strategy to encourage exploration of diverse action sequences."
- DAPO: A direct alignment policy optimization method used to inspire the paper’s RL variant; e.g., "inspired by DAPO."
- Evaluator-first generation: A task synthesis strategy that starts from programmatic evaluators and then generates tasks to satisfy them; e.g., "Evaluator-first generation produces complex, verifiable tasks ideal for RL training."
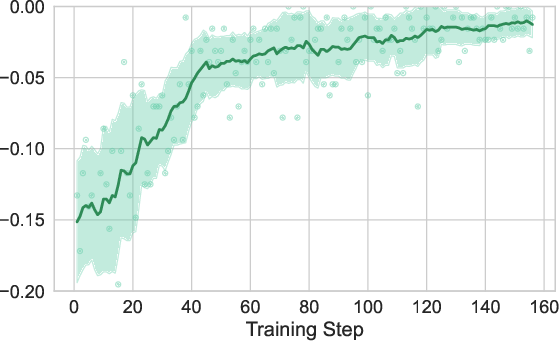
- Format rewards: Rewards that score an agent’s output formatting or syntax rather than outcomes; e.g., "format rewards also improve substantially (Fig. 2) despite not being explicitly optimized."
- GAIA: A benchmark for tool-using agents highlighting programmatic capabilities; e.g., "benchmarks like GAIA."
- GRPO: A reinforcement learning algorithm variant used for policy optimization; e.g., "we employ a variant of GRPO."
- Grounder agent: A specialized component that performs precise visual localization and GUI action execution; e.g., "comprising a Planner agent and a specialized Grounder agent."
- grounding model: A model trained for accurate mapping from visual UI elements to actions; e.g., "a state-of-the-art grounding model (GTA1-7B)."
- GUI primitives: Low-level interface actions such as click, type, and scroll; e.g., "seamlessly integrating GUI primitives with high-level programmatic tool calls."
- Hybrid action: A combined action space that interleaves GUI primitives with programmatic tool calls; e.g., "We present UltraCUA, a foundation model that bridges this gap through hybrid action."
- KL regularization: A common RL regularizer based on Kullback–Leibler divergence that was removed in this work to promote exploration; e.g., "We remove KL regularization."
- MCP servers: Model Context Protocol servers offering structured tool interfaces to LLM agents; e.g., "APIs, MCP servers, and tools."
- Multi-Agent Frameworks: Systems that coordinate multiple specialized components (e.g., planner and grounder) to solve tasks; e.g., "Multi-Agent Frameworks: systems that orchestrate multiple components to solve computer-use tasks."
- online reinforcement learning: RL performed during interaction with tasks/environments rather than purely offline from logs; e.g., "followed by online reinforcement learning on synthetic tasks."
- OSWorld-Verified: A benchmark suite with deterministic initial states and automated evaluators for reproducible assessment; e.g., "We use OSWorld-Verified as our primary benchmark."
- Out-of-domain evaluation: Testing a model on data or environments different from its training distribution; e.g., "Out-of-domain evaluation on WindowsAgentArena."
- Pass@4: A metric counting success if any of four independent attempts solves the task; e.g., "Pass@4."
- Planner agent: The agent component that decides which action modality (tool vs. GUI) to use; e.g., "comprising a Planner agent."
- Programmatic tool calls: High-level, parameterized function invocations that encapsulate multi-step operations; e.g., "high-level programmatic tool calls."
- ReAct framework: A prompting and reasoning framework that interleaves reasoning with actions; e.g., "operates in a ReAct framework."
- relative improvement: Performance gain expressed as a percentage relative to a baseline; e.g., "achieve an average 22% relative improvement over base models."
- rollouts: Multiple independent execution attempts used to sample strategies and measure stochastic performance; e.g., "8 rollouts per task."
- sparse environment reward: A binary success/failure signal used in RL instead of dense shaping; e.g., "the sparse environment reward (1 for task success, -1 for failure)."
- Tool-use reward: An auxiliary RL reward that encourages effective use of programmatic tools; e.g., "the tool-use reward is defined as:"
- Trajectory Efficiency: An efficiency metric counting the number of action steps taken to succeed; e.g., "Trajectory Efficiency."
- Visual grounding: Mapping from visual observations of UIs to actionable targets and coordinates; e.g., "accurate visual grounding."
- Working memory: An internal, persistent state store the agent maintains across steps; e.g., "We address this through an integrated working memory system."
- zone of proximal development: The task difficulty region where learning progress is maximized; e.g., "within the model's zone of proximal development."
- Zero-shot tool generalization: The agent’s ability to use previously unseen tools correctly at inference time; e.g., "This zero-shot tool generalization capability also extends beyond single-platform scenarios."
Collections
Sign up for free to add this paper to one or more collections.

