- The paper introduces AIOS 1.0’s innovative MCP server that transforms computer states into semantic contexts for LLM-based agents.
- It employs a minimalist orchestrator-worker architecture with a perceive-reason-act cycle to optimize task management in computer-use agents.
- Evaluation shows LiteCUA achieving a 14.66% success rate on the OSWorld benchmark, underscoring its performance gains over complex systems.
LiteCUA: Computer as MCP Server for Computer-Use Agent on AIOS
Introduction
The paper introduces AIOS 1.0, a platform designed to enable LLMs to seamlessly interact with computer-use agents (CUAs) by contextualizing computing environments. This approach aims to bridge the semantic disconnect between LLMs and the typically rigid structures of computer interfaces. Through the development of AIOS 1.0, computers are transformed into contextual environments that LLMs can understand, thus decoupling interface complexity from decision complexity.
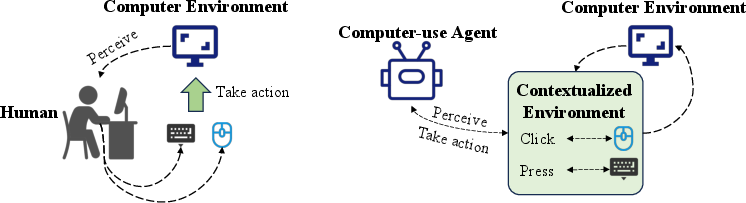
Figure 1: Illustration of the differences between how human operates computer and how computer-use agent (CUA) operates computer, where CUA requires a specific contextualized environment to understand the original computer environment and take actions.
Architecture and System Design
AIOS 1.0 builds on previous AIOS systems by incorporating a Model Context Protocol (MCP) server architecture. It abstracts computer states and actions into semantic representations that LLMs can effectively utilize. The architecture consists of multiple layers:
- Application Layer: Provides APIs for agents to interact with components such as terminals and browsers, creating a unified interaction surface.
- Kernel Layer: Enhances the AIOS kernel with tools like a VM Controller and MCP Server, facilitating a sandboxed environment for agent interaction.
This architecture transforms computers into semantic landscapes that align with LLM reasoning, facilitating long-term strategic planning.
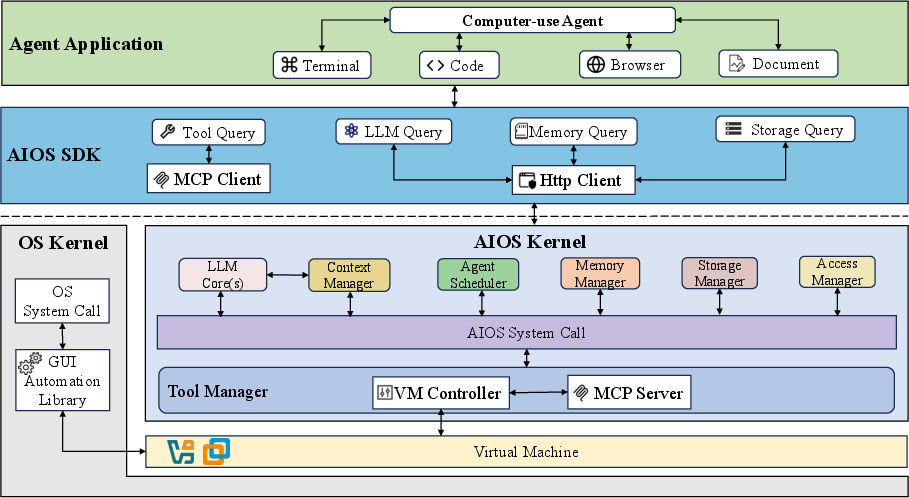
Figure 2: The serving architecture of AIOS 1.0 for computer-use agent, which extends on the basis of AIOS 0.x versions.
Contextualizing Computers as MCP Servers
The core innovation of AIOS 1.0 is its ability to transform traditional computing environments into interactive contexts for LLMs:
- Environment Perception Framework: A multi-modal sensing approach that enriches the computer's state with semantic information via screenshots and accessibility trees.
- Action Space Semantics: Encapsulates essential operations like Click, Scroll, and Drag into higher-level commands compatible with the semantic understanding of LLMs.
By decoupling interface operations from cognitive reasoning, AIOS 1.0 facilitates more refined and efficient task management.
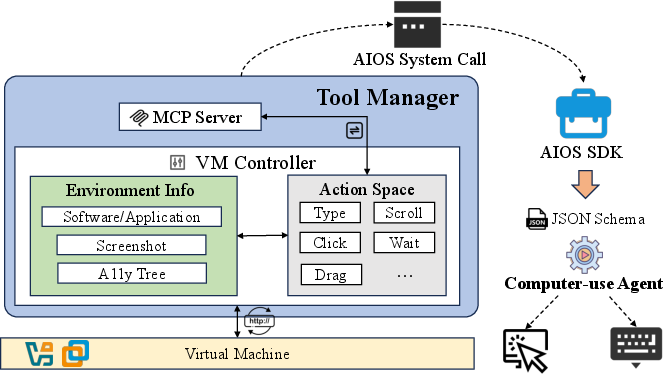
Figure 3: Pipeline for agents to take actions to interact with VM environments.
LiteCUA: Implementation on AIOS 1.0
LiteCUA, developed as an application on AIOS 1.0, leverages the contextual environment framework to simplify agent design and enhance performance on the OSWorld benchmark.
- Orchestrator-Worker Architecture: Employs a decentralized model separating task planning from execution, thereby optimizing task workflows.
- Perceive-Reason-Act Cycle: A structured process where the agent perceives its environment, reasons through potential actions, and then acts on these decisions.
This minimalist architecture allows LiteCUA to achieve a 14.66% success rate on the OSWorld benchmark, outperforming more complex systems despite its simplicity.
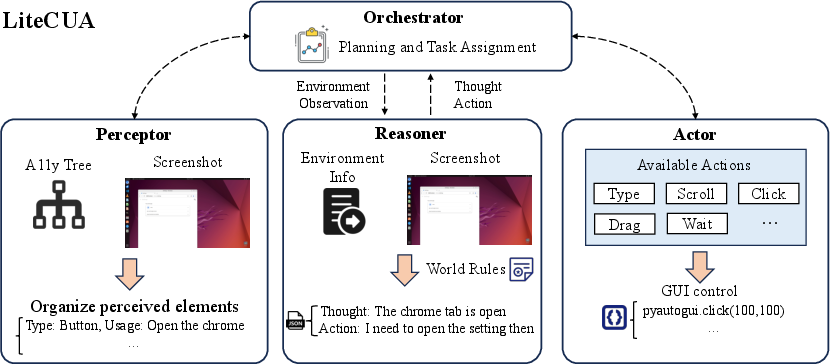
Figure 4: Design of LiteCUA. We adopt a simple orchestrator-worker architecture, where orchestrator is responsible for planning and assigning tasks and other workers deal with specialized duties like perceiving, reasoning and acting.
Evaluation
In a controlled environment, LiteCUA demonstrated significant promise, especially in tasks involving straightforward interactions like operating systems (OS). However, it faced challenges with more complex applications requiring intricate interface manipulation. The varying performance underscores the importance of enriched semantic processing in agent systems.
Current researches in CUAs have placed emphasis on harnessing multimodal data for better interfacing with complex environments, much like the methodology showcased by LiteCUA. Further development in AIOS infrastructures is pivotal in advancing from tool-specific to more generalized applications of these systems.
Conclusion
AIOS 1.0 and LiteCUA set forth a compelling argument for contextualizing computational environments to optimize LLM-based agent performance. Future work will likely explore refining perception frameworks and expanding application domains to fully harness this contextualization strategy. Transforming computer interfaces into environments that LLMs can naturally navigate represents a pivotal shift in advancing general-purpose AI capabilities.