- The paper introduces PLENA, a co-designed hardware-software system that improves long-context large language model inference by overcoming memory bandwidth and capacity walls.
- It employs a flattened systolic array and an asymmetric quantization scheme (using W_mxint4, A_mxint8, and KV_mxint4) to enhance resource utilization, achieving up to 8.5 times better throughput.
- Native support for FlashAttention minimizes off-chip memory I/O, optimizing performance for agentic workloads that consume substantially more tokens.
Combating the Memory Walls: Optimization Pathways for Long-Context Agentic LLM Inference
The paper "Combating the Memory Walls: Optimization Pathways for Long-Context Agentic LLM Inference" introduces PLENA, a co-designed hardware-software system to address the computational challenges associated with long-context LLM inference. This section provides a comprehensive overview of the key methodologies and implications outlined in the research.
Introduction
To optimize the efficiency of LLMs designed for agentic tasks, PLENA incorporates three primary pathways: a flattened systolic array architecture, an asymmetric quantization scheme, and native support for FlashAttention. Each of these approaches is targeted at mitigating the so-called memory bandwidth and capacity walls that hinder contemporary hardware from fully utilizing computation units during LLM inference.
The paper highlights the groundbreaking implications of agentic LLM workloads, which require much larger context lengths compared to traditional chatbot workloads, consequently consuming significantly more tokens (Figure 1).
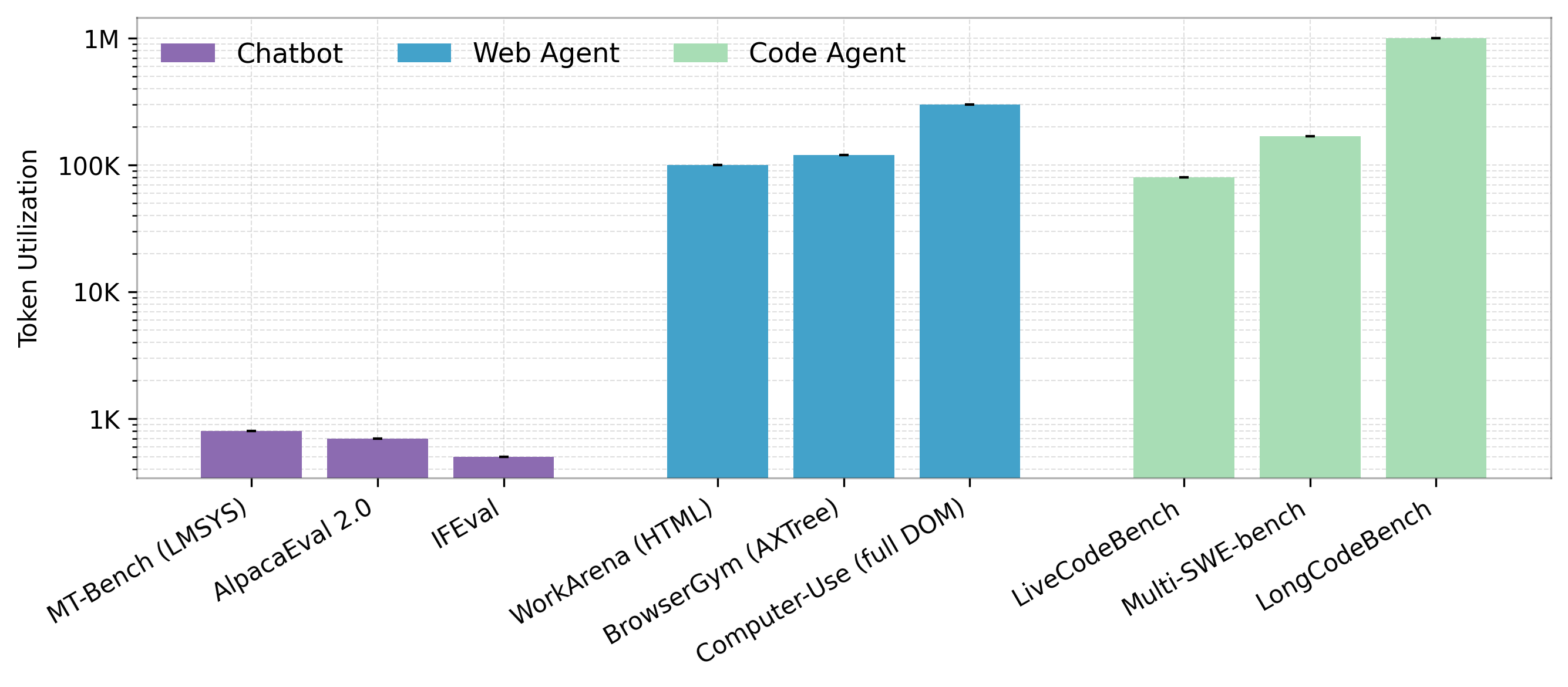
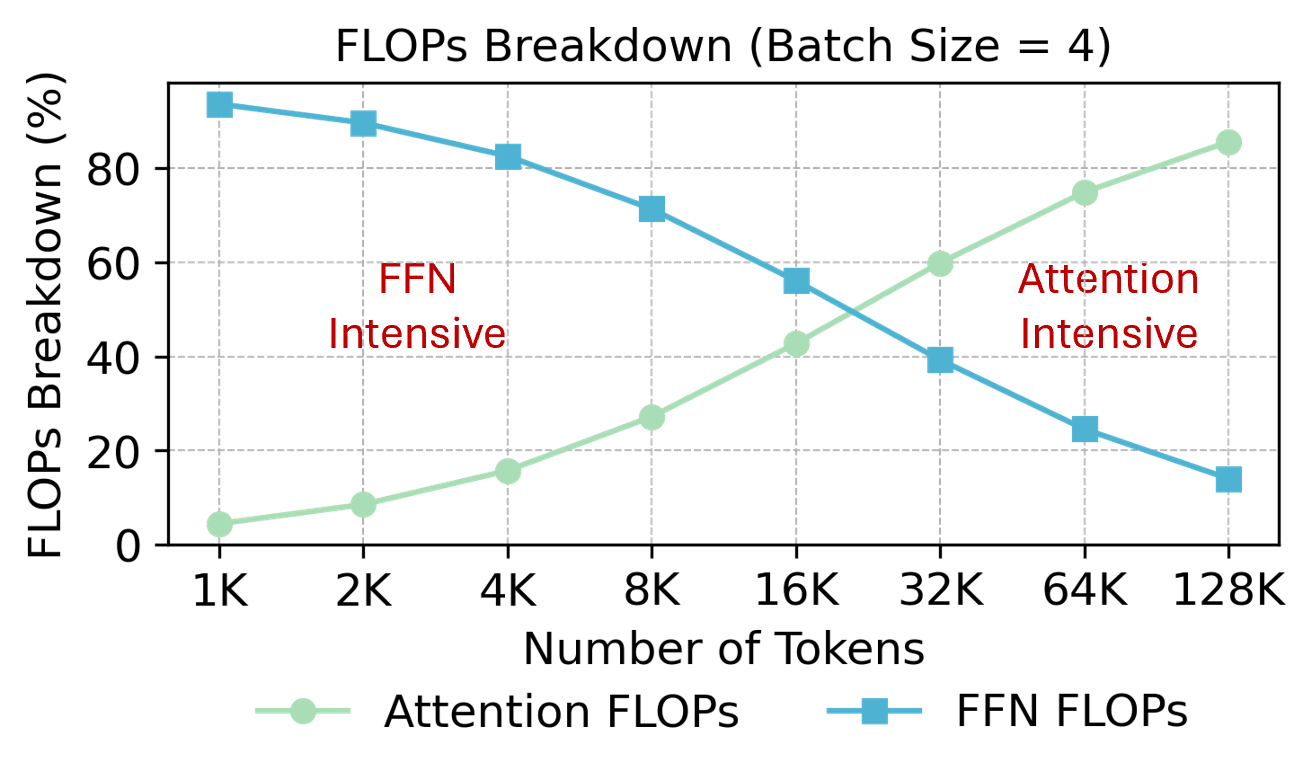
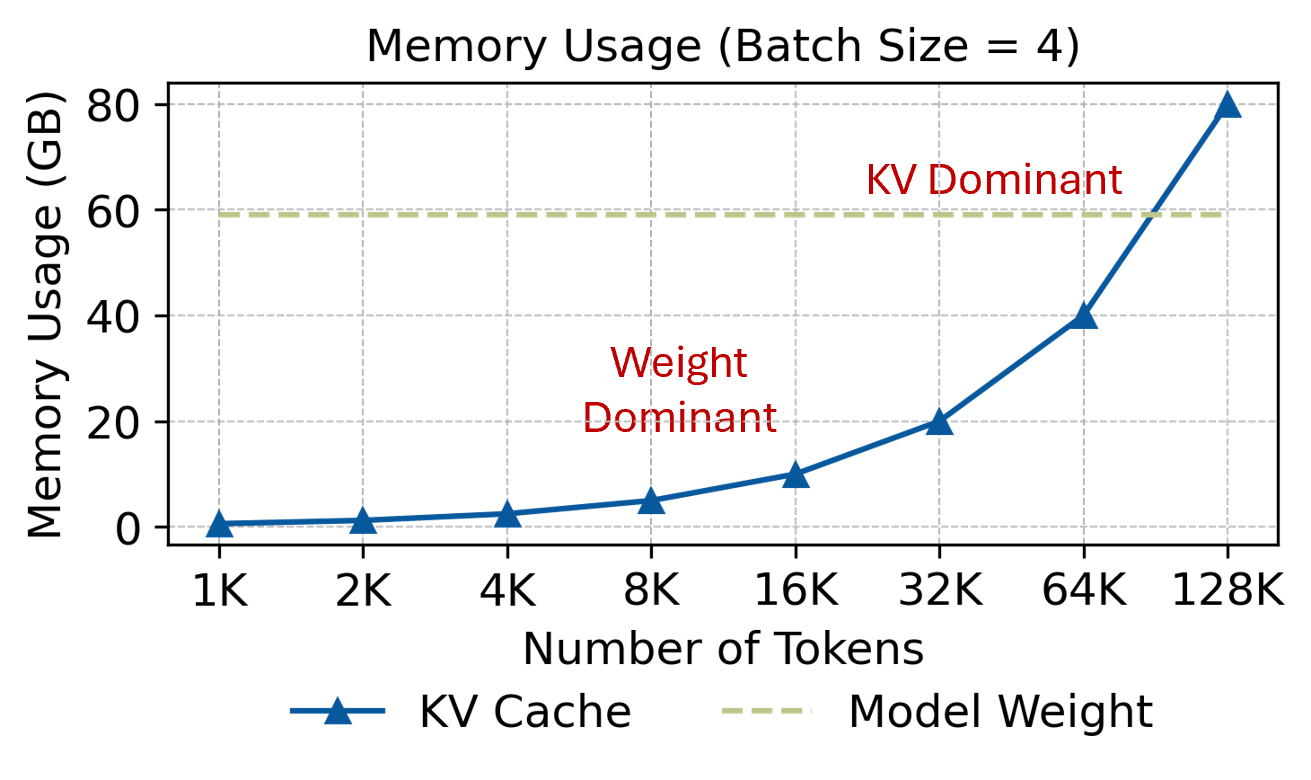
Figure 1: Compared with standard chatbot workloads, the selected agentic web and code tasks generally consume over 100times more tokens.
System Architecture and Optimization Pathways
Flattened Systolic Array
PLENA implements a unique flattened systolic array to better accommodate the uneven matrix shapes found in long-context LLM inference tasks. This architecture optimizes the utilization of GEMM units across both the prefilling and decoding stages of agentic inference tasks. By adjusting the architecture to handle large inner dimensions (K), PLENA enhances compute efficiency over conventional square-shaped systolic arrays.

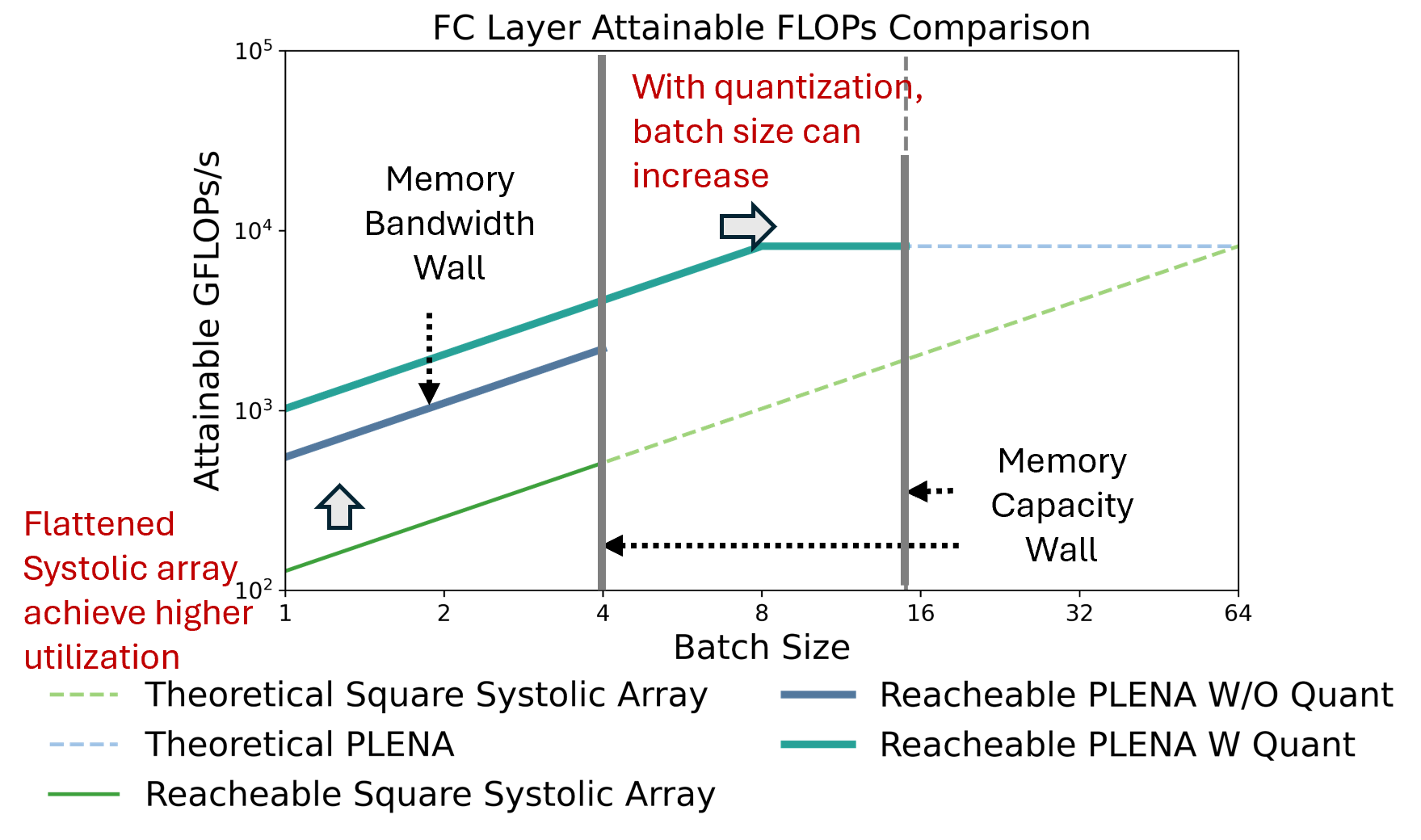
Figure 2: PLENA achieves higher utilization than the standard square systolic array(same resources).
Asymmetric Quantization Scheme
PLENA's asymmetric quantization strategy allows different numerical types and precisions to be applied to weights, activations, and the KV cache. This flexibility significantly alleviates the constraints imposed by memory bandwidth and capacity walls. For example, applying more aggressive quantization such as Wmxint4, Amxint8, KVmxint4, enables larger batch sizes and overall improved latency.
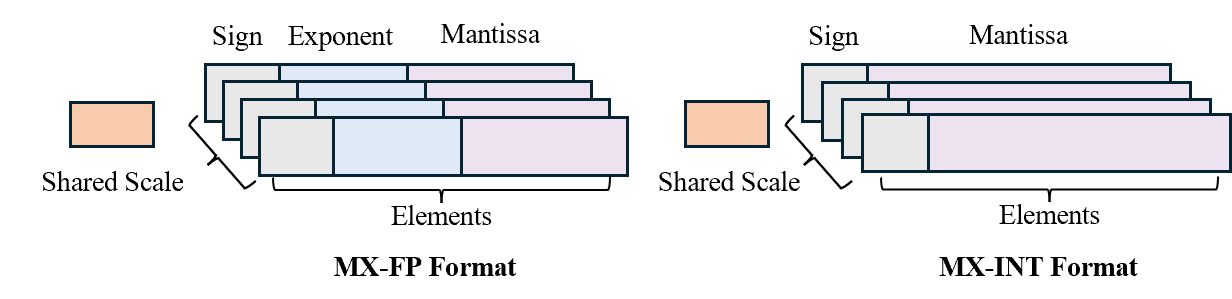
Figure 3: A typical setting of the MX data formats in this design. A scale is shared by a group of elements. Scale is in power of two quantization and elements can be quantized to integer or minifloat.
FlashAttention Support
PLENA supports FlashAttention natively, overcoming limitations in conventional architectures that require costly off-chip memory I/O for attention computation. This integration prevents excessive data movement, thereby improving inference performance, especially at longer context lengths where attention layers dominate the computational flow.
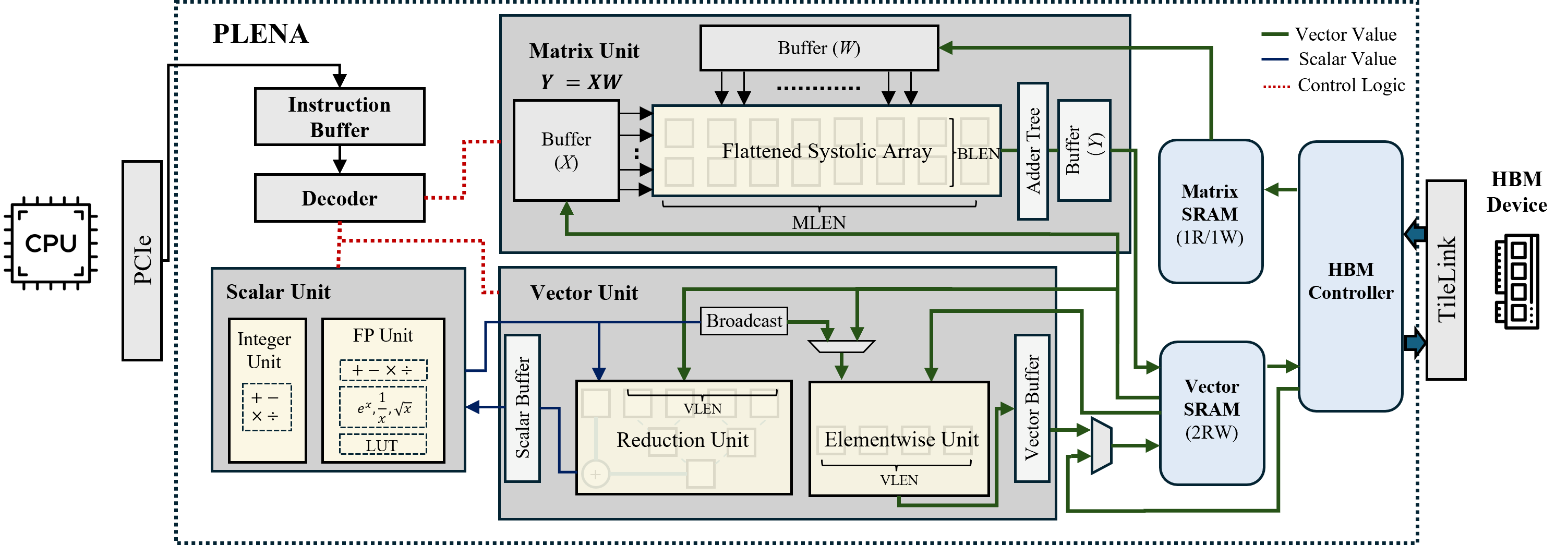
Figure 4: PLENA architecture overview. Execution is controlled by the decoder's system-pipeline controller, which derives control signals from decoded instructions and monitors memory dependencies. For example, if the current instruction needs to read from a Vector SRAM row that is still being updated by the vector or matrix unit, the controller inserts a stall to ensure correctness. Vector SRAM acts as the on-chip scratchpad, providing data to the matrix and vector units and accepting their results.
Implementation and Evaluation
The proposed PLENA system is rigorously evaluated through simulations and compared with leading accelerators and commercial GPUs/TPUs. The results demonstrate that PLENA achieves up to 8.5 times better utilization in agentic workloads and offers higher throughput than the A100 GPU and TPU v6e, confirming its effectiveness in long-context scenarios.
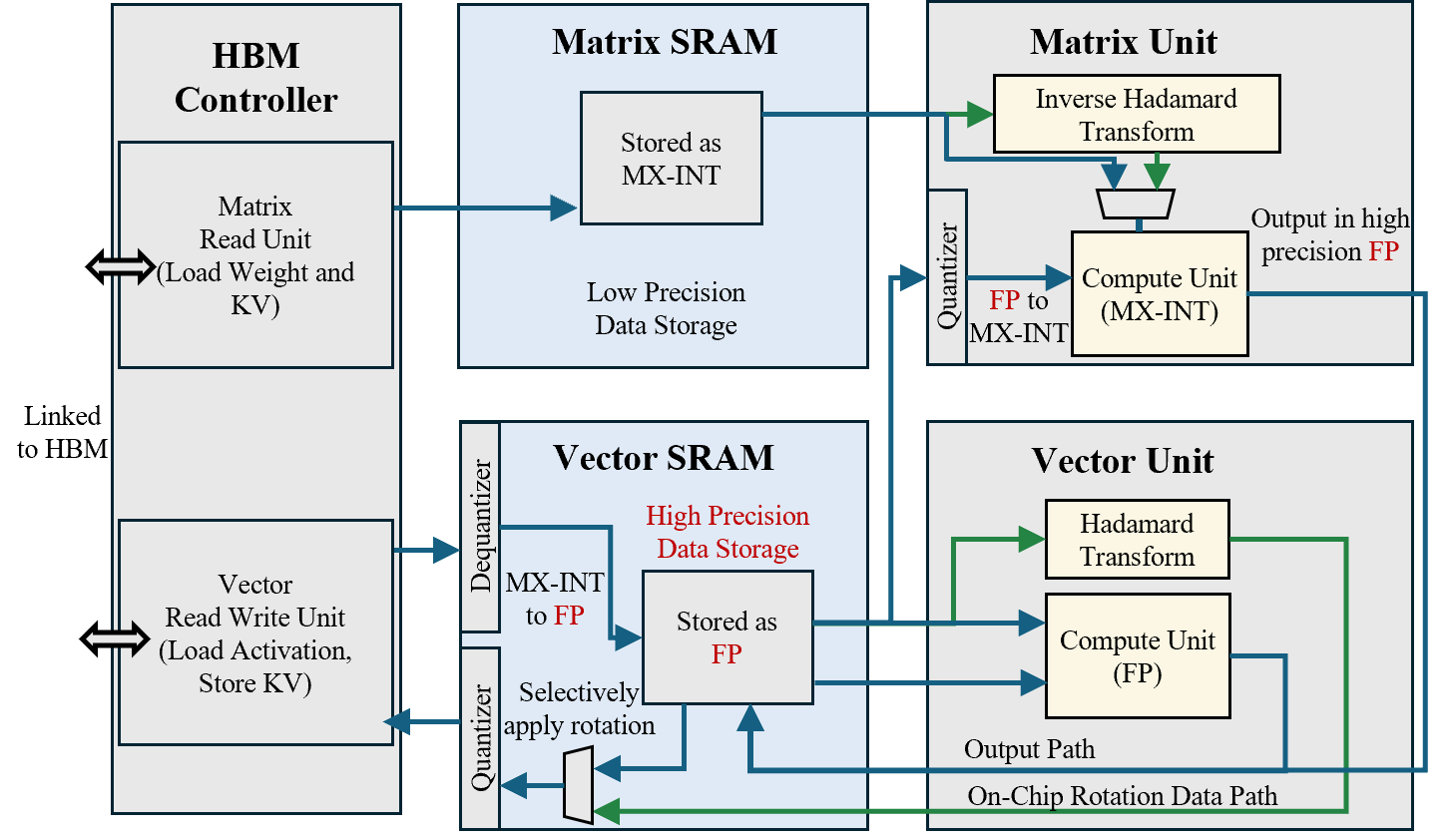
Figure 5: Asymmetric-precision datapath example. Vector SRAM stores FP4 values, whereas Matrix SRAM stores MX-INT4 values. Green paths denote the selective rotational quantization flow: a fast Walsh–Hadamard transform is applied, with its inverse used to map back~\cite{hadamard_transform.
Conclusion
The PLENA system effectively addresses the underutilization challenges posed by memory walls in contemporary hardware systems used for LLM inference. Through strategic hardware and software optimization pathways including flattened systolic arrays, asymmetric quantization, and native FlashAttention support, PLENA improves performance metrics significantly compared to existing solutions.
With these advances, PLENA paves the way for more efficient inference of agentic LLM workloads, promising substantial improvements in areas requiring extensive context comprehension and processing. Future developments could focus on further enhancing GEMM utilization within FlashAttention and extending PLENA's capabilities with multi-core architectures to better exploit parallelism.