- The paper introduces a comprehensive survey that categorizes instance-level, cluster-level, and emerging scenarios for efficient LLM inference serving.
- It details methodologies such as model placement, request scheduling, and cache optimization to tackle memory and computational challenges.
- Findings highlight practical strategies like load balancing and cloud-based serving that enable scalable and real-time LLM deployment.
Taming the Titans: A Survey of Efficient LLM Inference Serving
The paper "Taming the Titans: A Survey of Efficient LLM Inference Serving" provides a comprehensive overview of methodologies and strategies aimed at optimizing the inference serving processes for LLMs. As these models become increasingly complex and resource-intensive, efficient deployment and execution strategies are essential to meet real-time application demands and service level objectives. This survey systematically categorizes recent advancements into instance-level techniques, cluster-level strategies, emerging scenarios, and miscellaneous impactful areas.
Instance-Level Approaches
Instance-level optimizations are crucial for addressing unique computational and memory challenges inherent to LLMs.
Model Placement
The substantial size of LLM parameters often exceeds the capacity of a single GPU, necessitating advanced model placement strategies for efficient multi-GPU deployment or offloading to CPU resources. Techniques such as pipeline and tensor parallelism allow for distributed computation across devices, while offloading solutions balance GPU and CPU usage to optimize memory and computational efficiency (Figure 1).
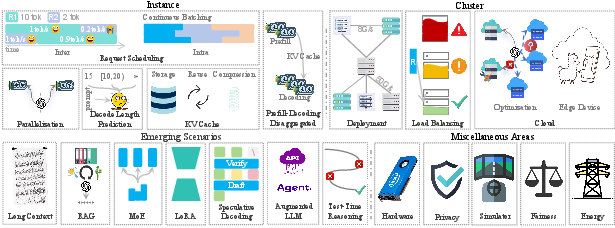 *Figure 1: Overview of the paper, detailing Instance, Cluster, Emerging Scenarios, and Miscellaneous Areas. $\mathbf{R$
*Figure 1: Overview of the paper, detailing Instance, Cluster, Emerging Scenarios, and Miscellaneous Areas. $\mathbf{R$
Request Scheduling
Efficient request scheduling significantly impacts throughput and latency in high-load scenarios. This encompasses inter-request approaches like Shortest Job First, which prioritize shorter tasks to improve overall efficiency, and intra-request methods that dynamically manage batched processing within concurrent requests to maximize GPU utilization.
Decoding Length Prediction
Predictive modeling for request lengths, whether exact, range-based, or relative ranking, informs scheduling strategies to refine processing order and optimize computational resources.
KV Cache Optimization
Memory management using KV caching significantly reduces computation overhead per token. Techniques for lossless storage, semantic reuse, and compression address memory limitations and enhance retrieval speed, crucial for efficient LLM inference.
PD Disaggregation
Separating prefill and decoding phases allows for targeted optimizations that improve throughput and reduce latency. Techniques like dynamic pipeline management direct resources according to phase-specific computational requirements.
Cluster-Level Strategies
Cluster-level optimizations focus on broader resource allocation and load-balancing strategies.
Cluster Optimization
In multi-GPU environments, heterogeneity-aware solutions enable efficient parameter distribution and execution within varied hardware settings. These methods tailor computation phases and prioritize service-oriented scheduling to meet diverse configuration demands.
Load Balancing
Algorithms that prioritize workload distribution prevent server overloading and optimize throughput, leveraging dynamic and predictive models to adjust resource allocation based on real-time demand and system metrics.
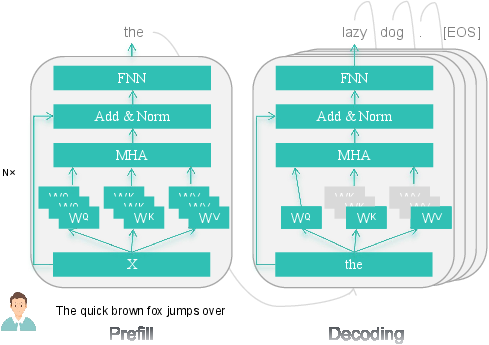
Figure 2: Illustration of the LLM Inference process.
Cloud-Based LLM Serving
When local resources are insufficient, leveraging cloud infrastructure offers scalability and flexibility. These approaches utilize serverless architectures and edge collaborations to maximize efficiency, reduce latency, and support dynamic deployment needs.
Emerging Scenarios
Emerging scenarios showcase innovative applications and challenges inherent to advancing LLM capabilities.
Long Context
Processing extensive contexts requires sophisticated attention mechanisms and cache management strategies to efficiently handle increased token counts while maintaining computational integrity.
RAG and MoE
Retrieval-Augmented Generation (RAG) and Mixtures of Experts (MoE) models introduce novel complexities in workflow scheduling, storage optimization, expert placement, and communication efficiency.
LoRA and Speculative Decoding
LoRA's fine-tuning frameworks and speculative decoding techniques achieve enhanced adaptability and speed without compromising output quality.
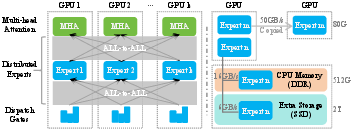 *Figure 3: This figure illustrates a MoE architecture, highlighting expert placement, All-to-All communication (left), and load balancing (right). On the right, high-traffic Expert $\mathbf{m$
*Figure 3: This figure illustrates a MoE architecture, highlighting expert placement, All-to-All communication (left), and load balancing (right). On the right, high-traffic Expert $\mathbf{m$
Miscellaneous Areas
Specialized research directions address critical challenges like hardware optimization, privacy, simulation frameworks, fairness, and energy usage, which are vital for shaping sustainable and equitable LLM deployments.
Conclusion
Efficient inference serving for LLMs necessitates a multi-faceted approach, encompassing instance-level, cluster-level, and emerging scenario optimizations. This comprehensive survey provides insights into addressing the computational, memory, and architectural challenges posed by LLMs, laying the groundwork for continued innovation and sustained progress in this pivotal field. The paper emphasizes that tackling these challenges is essential for advancing the practical deployment and performance of LLM systems across diverse applications.