- The paper introduces NPUEval, a benchmark that evaluates LLM-generated NPU kernel code based on performance, vectorization, and correctness.
- It demonstrates that advanced LLMs can generate vectorized code, though compiler feedback and RAG techniques are essential to improve efficiency.
- The evaluation framework uses open-source compilers and detailed performance metrics, highlighting the challenges in optimizing kernels for NPUs.
"NPUEval: Optimizing NPU Kernels with LLMs and Open Source Compilers"
Introduction
The paper, "NPUEval: Optimizing NPU Kernels with LLMs and Open Source Compilers," addresses the challenge of generating optimized neural processing unit (NPU) kernels using LLMs and explores the efficacy of these models in code generation specific to NPUs. With NPUs becoming critical components in power-sensitive devices, efficient kernel codes are essential to leverage their full potential. However, unlike GPUs, NPU programming lacks extensive developer resources and mature software ecosystems, posing unique challenges.
NPUEval Benchmarking
NPUEval is introduced as a benchmark designed to evaluate LLM-generated kernel code for AMD NPUs, focusing on functional correctness and vectorization efficiency. The dataset consists of 102 common operators used in machine learning workloads. Evaluation is performed using open-source compilers targeting AMD NPUs. The primary objective is to assist in advancing research in code generation and NPU kernel optimization by providing a public dataset and a comprehensive evaluation framework.
Code Generation with LLMs
The study leverages various state-of-the-art LLMs to generate kernel code, including proprietary models and open-weight models. Initial results indicate that advanced reasoning models like DeepSeek R1 can achieve commendable vectorization rates on select kernels out-of-the-box, although the average vectorization score across the dataset remains low. The low average score indicates the complexity and challenge posed by the dataset even for advanced models.
Vectorization is a critical component of optimizing kernel performance on NPUs. The paper provides a detailed example comparing scalar and vectorized kernel implementations, showcasing the significant performance benefits of vectorized code. The evaluation criteria for the generated kernels include compilation success, functional correctness, and performance metrics, particularly focusing on vectorization scores.
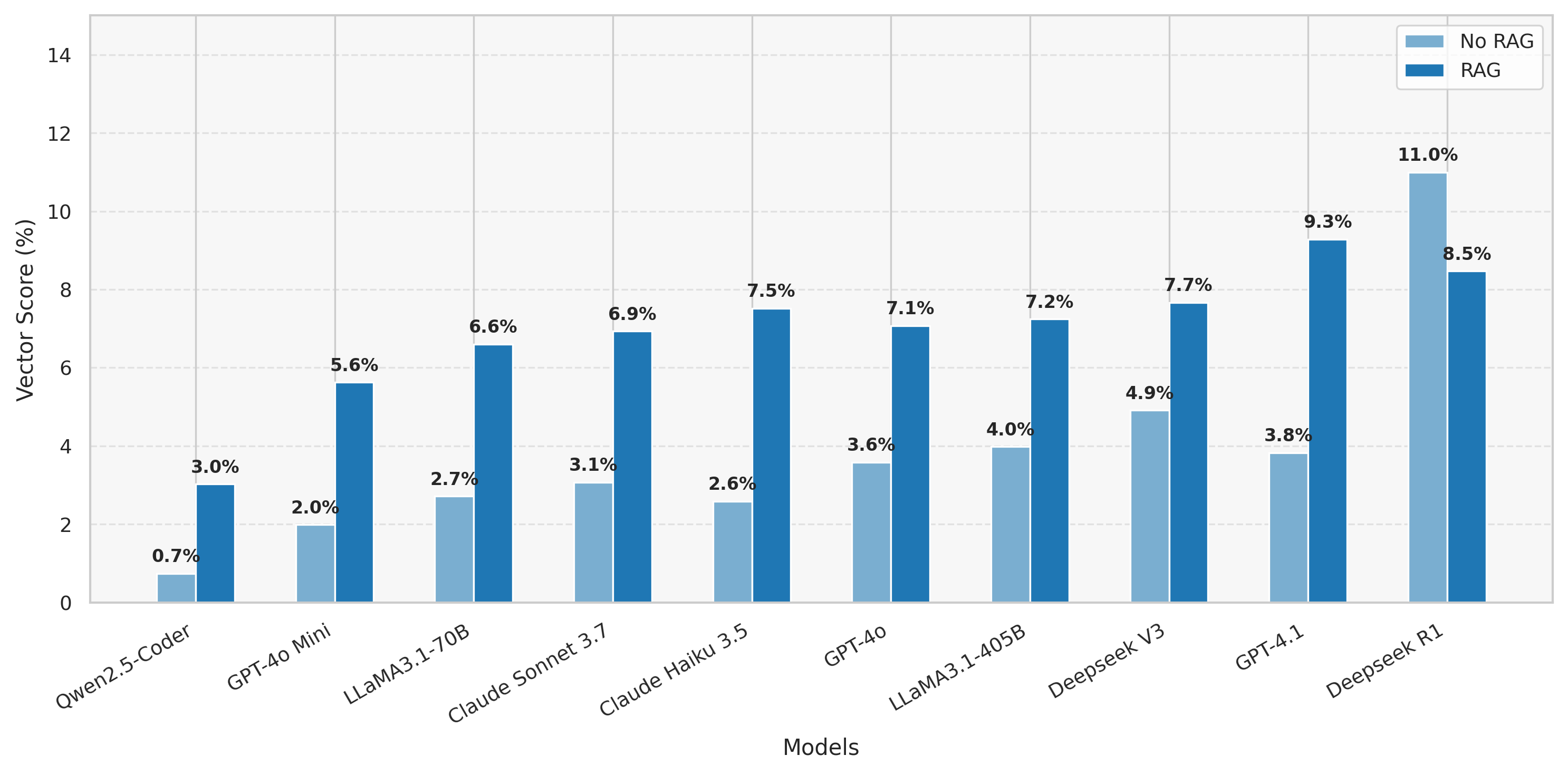
Figure 1: Vectorization results
Evaluation Framework
The evaluation harness integrates behavioral models, test vectors, and utilizes the LLVM-AIE compiler, which is adapted specifically for AIE kernel programming. The framework runs the generated kernels, comparing outputs against expected results, and measures cycle-accurate performance metrics to scrutinize VPU utilization.
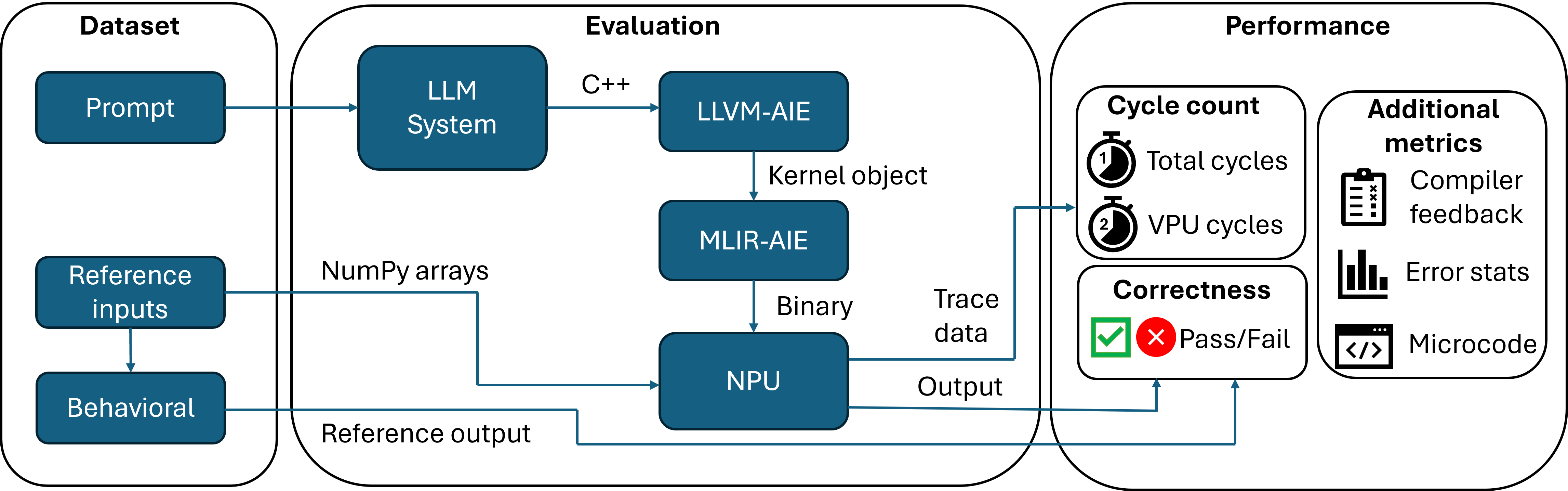
Figure 2: Overview of NPUEval evaluation pipeline.
Enhancements through RAG and Compiler Feedback
The study employs Compiler Feedback and Retrieval-Augmented Generation (RAG) to improve LLM outputs. RAG incorporates vectorized kernel examples to guide models toward producing better-optimized code. The paper demonstrates that the incorporation of these methods substantially enhances the functional correctness of the generated kernels across various models.
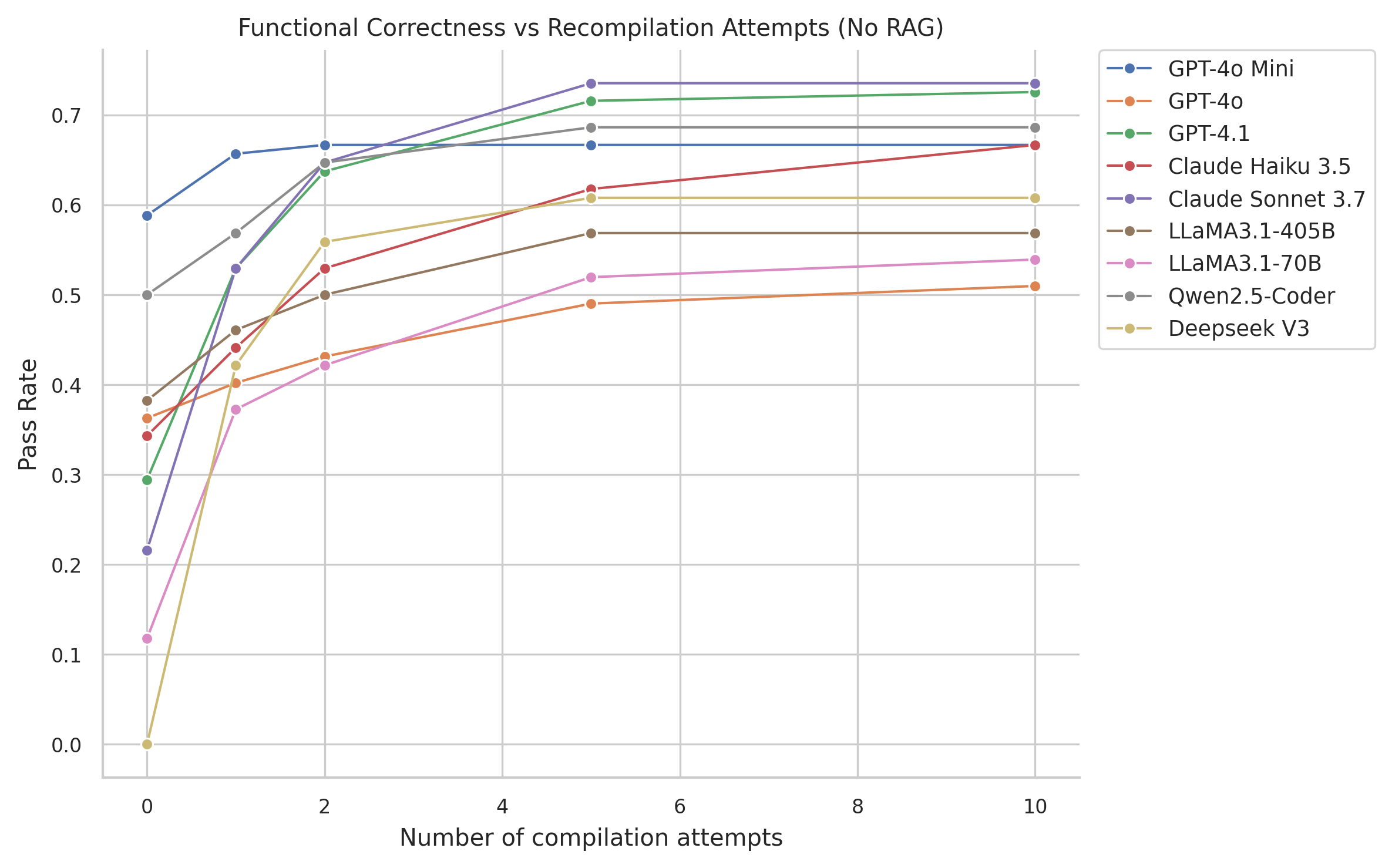
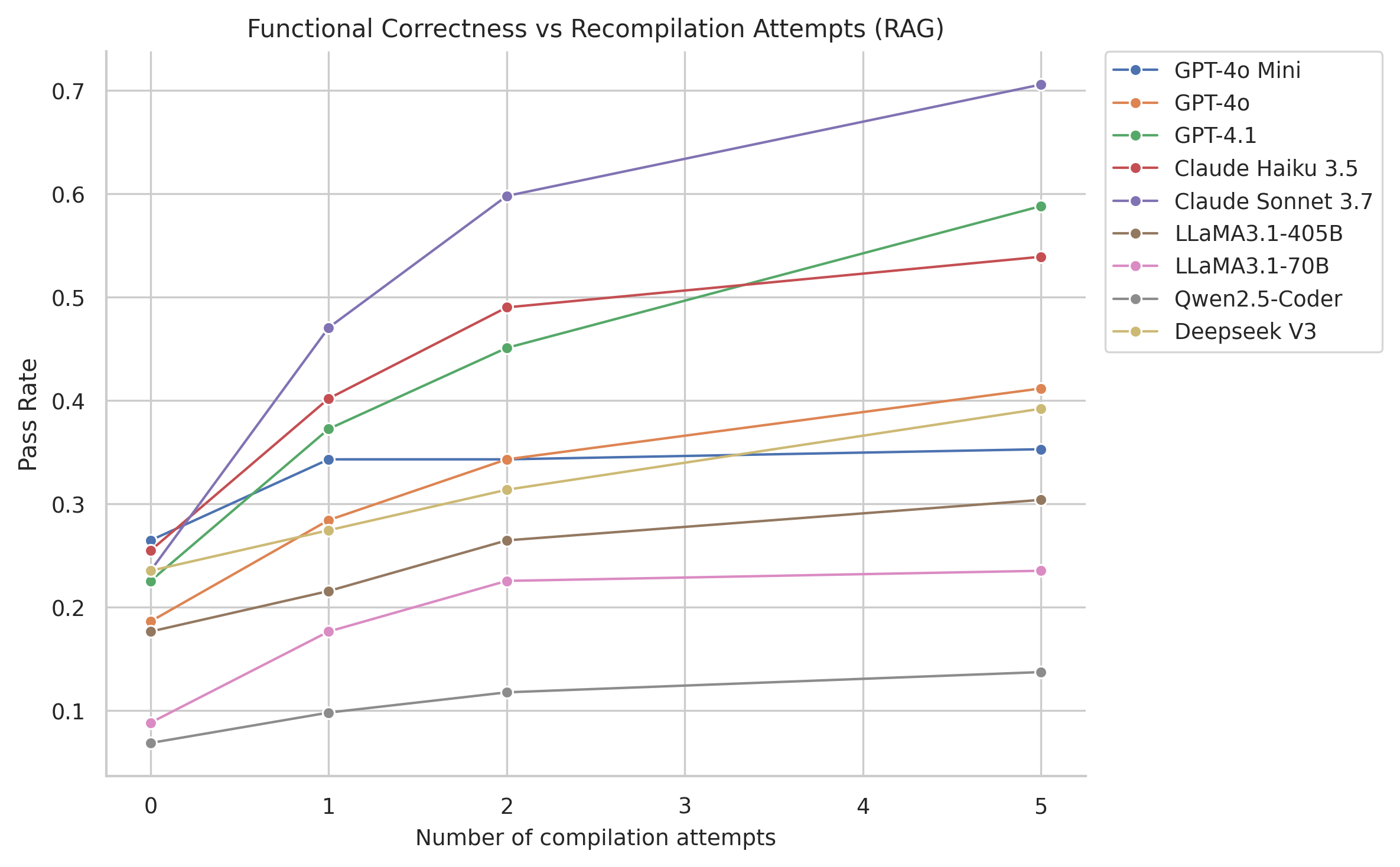
Figure 3: Test pass rate as number of recompilations increases.
Results and Observations
The LLM evaluation indicates that smaller models often default to scalar solutions that are syntactically correct but inefficient. In contrast, stronger models attempt more sophisticated vectorized implementations but face challenges with API knowledge and hallucinations. Correctness improved with successive compiler feedback, highlighting its importance in the LLM-driven code generation pipeline.
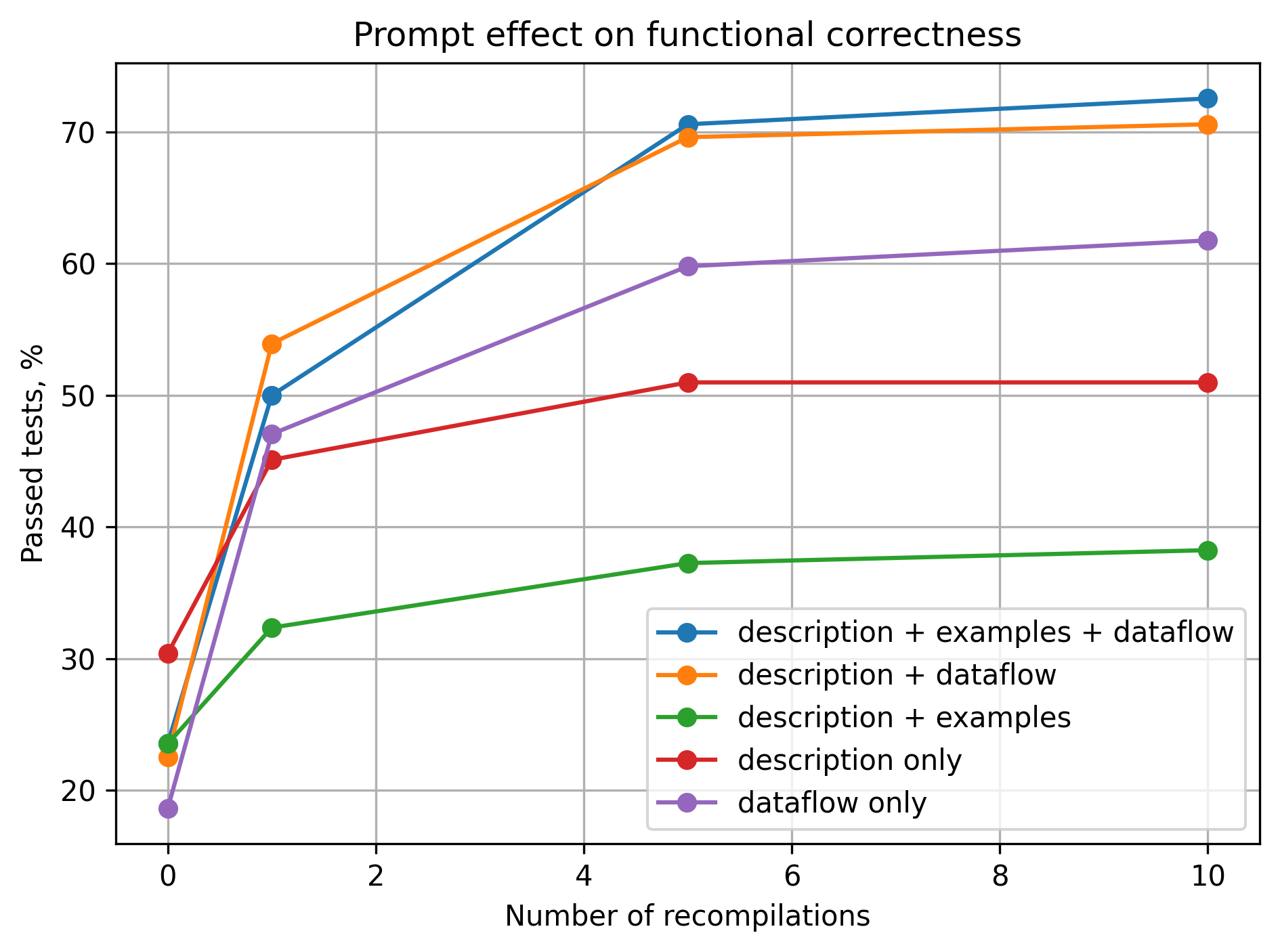
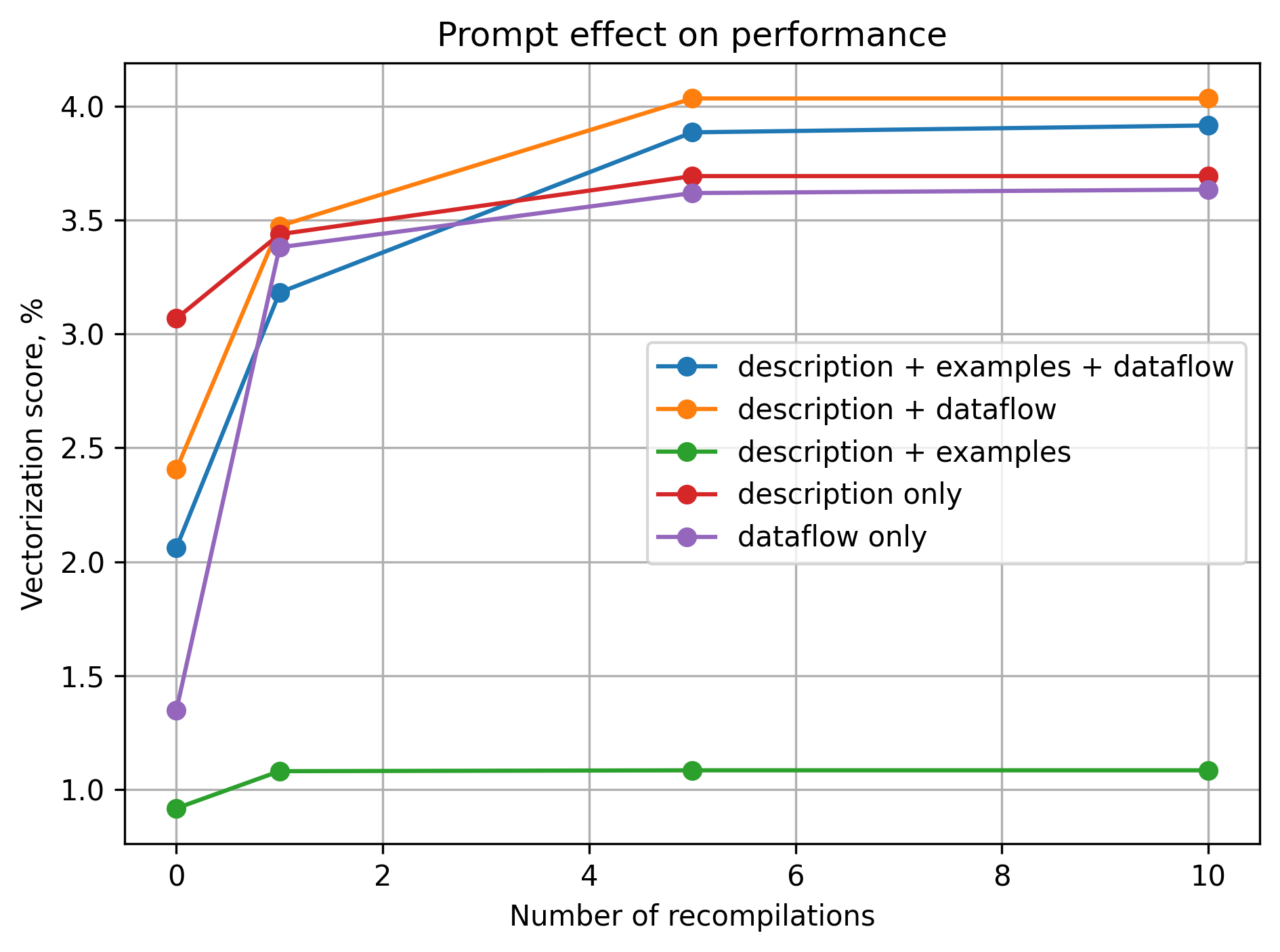
Figure 4: Functional correctness results.
Conclusion and Future Directions
"NPUEval" establishes a vital benchmark for assessing LLM capabilities in generating NPU kernel code and highlights the need for more refined techniques to handle specialized hardware programming challenges. Future work involves extending the benchmark to other NPU architectures and refining the RAG process to accommodate compiler-specific nuances, which would further enhance the applicability and effectiveness of LLMs in this domain.

