Evaluating the Limitations of Local LLMs in Solving Complex Programming Challenges
Abstract: This study examines the performance of today's open-source, locally hosted large-LLMs in handling complex competitive programming tasks with extended problem descriptions and contexts. Building on the original Framework for AI-driven Code Generation Evaluation (FACE), the authors retrofit the pipeline to work entirely offline through the Ollama runtime, collapsing FACE's sprawling per-problem directory tree into a handful of consolidated JSON files, and adding robust checkpointing so multi-day runs can resume after failures. The enhanced framework generates, submits, and records solutions for the full Kattis corpus of 3,589 problems across eight code-oriented models ranging from 6.7-9 billion parameters. The submission results show that the overall pass@1 accuracy is modest for the local models, with the best models performing at approximately half the acceptance rate of the proprietary models, Gemini 1.5 and ChatGPT-4. These findings expose a persistent gap between private, cost-controlled LLM deployments and state-of-the-art proprietary services, yet also highlight the rapid progress of open models and the practical benefits of an evaluation workflow that organizations can replicate on in-house hardware.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper tests how well “local” AI coding tools can solve lots of tough programming puzzles. Local means the AI runs on your own computer or server, not in the cloud. The authors build a reliable, offline testing system and use it to compare eight open‑source models on 3,589 problems from Kattis, a site known for serious coding challenges.
In short: they ask, “If you don’t want to send your code to the cloud (for privacy, speed, or cost reasons), how good are today’s open models at solving real, complex programming problems?”
What questions did the researchers try to answer?
- How well do open-source, locally run AI coding models solve a very large and difficult set of problems?
- How do they compare to top cloud models like ChatGPT‑4 and Gemini 1.5?
- Can we build a simple, fully offline evaluation setup that others can copy and use on their own hardware?
How did they run the study?
Think of the study like a well-organized “robot” that:
- collects many problems,
- asks an AI to write code,
- submits that code to a judge,
- saves the results carefully so nothing is lost.
Here’s what they did, in everyday terms:
- The problem set: They used Kattis, which has over 3,500 programming problems of all levels. Unlike sites like LeetCode (where solutions are often public), Kattis discourages sharing answers. That makes it a tougher, more honest test because the models are less likely to have memorized solutions from the internet.
- Local models: They picked eight open-source models that are small enough to run on normal GPUs (about 6.7–9 billion parameters). Running them locally helps with privacy, avoids cloud fees, and removes API limits.
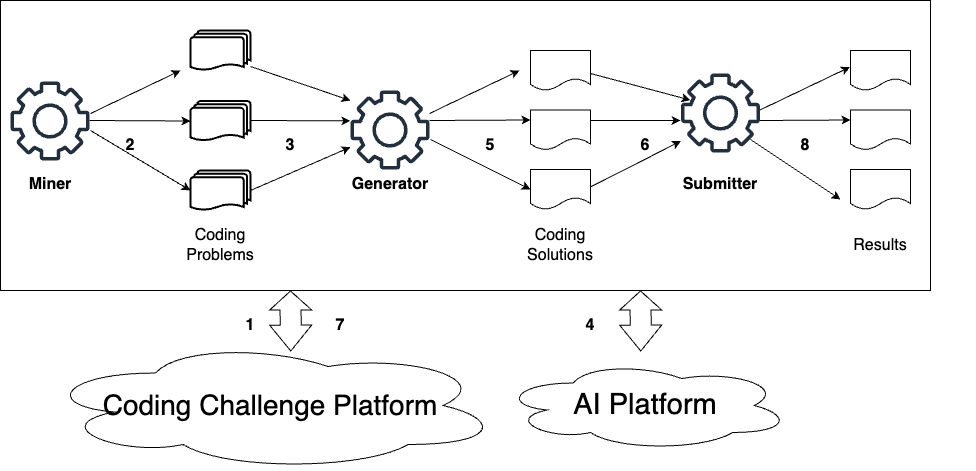
- Upgrading the testing system: They improved a tool called FACE so it runs fully offline using Ollama (a platform for running local LLMs). They also:
- Swapped thousands of tiny folders and files for a handful of big JSON files. This is like replacing a messy filing cabinet with a few neat binders—faster, cleaner, and easier to share.
- Added “checkpointing,” which is like saving your game. If the computer crashes during a multi-day run, it can pick up right where it left off.
- Used careful “atomic” saving so results don’t get corrupted—like writing your final answer in pencil on scratch paper and only copying it to the official sheet once you’re sure it’s correct.
- The process: For each problem, the system fed the description and examples to a local model, got a code answer, submitted it to Kattis, and recorded the result (Accepted, Wrong Answer, Run Time Error, etc.). This took more than three weeks to run for all models.
- How success was measured: The main score was “pass@1,” which is simply the chance that the model’s first try solves the problem.
What did they find?
- Accuracy is modest for local models: The best two local models solved about 5% to 6% of problems on the first try:
- Qwen2.5‑Coder: 5.7%
- Yi‑Coder: 5.4%
- Most others were lower.
- Cloud models are still ahead: In earlier work on a large subset of Kattis problems, Gemini 1.5 and ChatGPT‑4 each solved around 11% on the first try. So the best local models are about half as good—for now.
- Difficulty matters a lot:
- Easy problems: Some got solved, but still many wrong answers or errors.
- Medium problems: Accepted solutions dropped sharply.
- Hard problems: Basically none were solved. Only two local models produced even a single accepted solution in the “Hard” set.
- Common failure types: Most misses were “Wrong Answer” or “Run Time Error.” That means the models often produced code that looked right but didn’t pass all tests, or crashed when running.
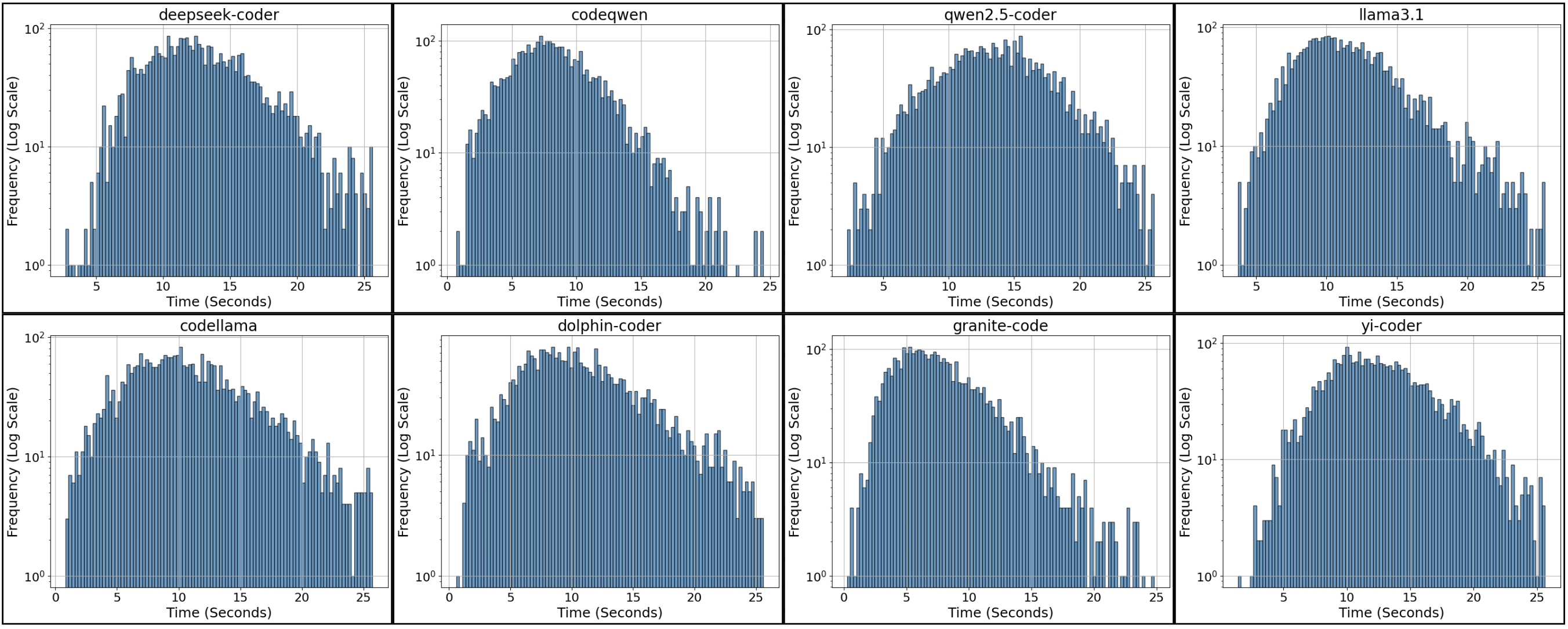
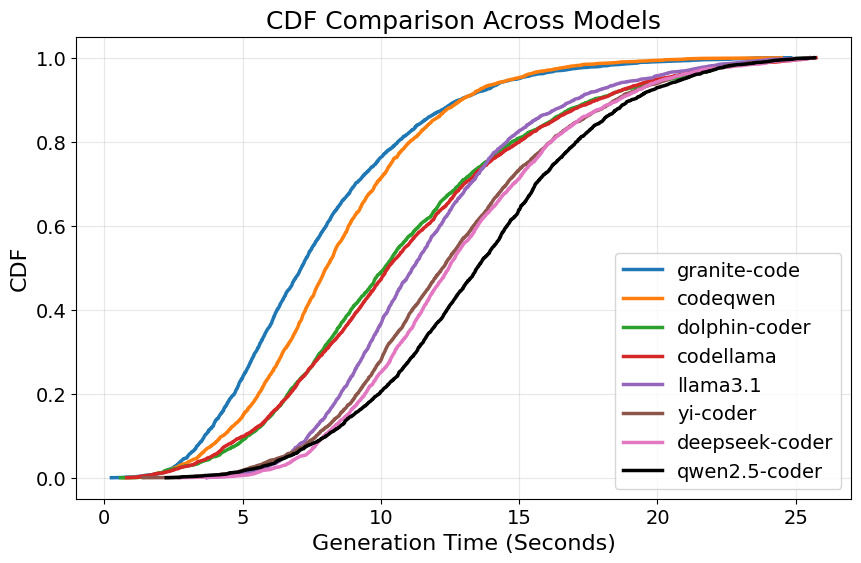
- Speed vs accuracy trade-off: Some of the more accurate local models were slower to generate code. In other words, taking more time didn’t guarantee better answers, but the best performers tended to be a bit slower.
Why does this matter?
- Clear trade-offs: Local models protect privacy and avoid cloud costs and rate limits. You can run as many tests as you want. But today, they still lag behind top cloud AIs in accuracy on tough problems.
- A reusable, practical setup: The upgraded, offline evaluation system is something schools, companies, and researchers can copy to test models on their own machines. It’s simpler (fewer files), safer (good saving and checkpoints), and can run for days without losing progress.
- A tougher, fairer benchmark: Because Kattis solutions are harder to find online, this test better reflects true problem-solving ability—not just memorization.
- Paths to improvement: The authors suggest ways to boost local models:
- Fine-tune them on the right kind of problems,
- Combine local and cloud models in a hybrid setup,
- Use better prompts and built‑in debugging steps.
- Uses in education: Even with modest accuracy, local models can help teachers build safer, privacy‑friendly tools—like “explain-as-you-grade” autograders that give step-by-step feedback, or gentle coding helpers inside students’ IDEs.
The simple takeaway
Local, open AI coding models are getting better, but they don’t yet match top cloud AIs on hard programming challenges. Still, they offer big advantages—privacy, control, and no usage fees—and now there’s a clean, fully offline way to test them at large scale. With smart fine-tuning and better workflows, local models could become much more capable, helping schools and organizations use AI safely and affordably.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, consolidated list of what remains missing, uncertain, or unexplored in the paper—each item is framed to guide actionable future research.
- Exact prompts, input formatting, and system instructions used for generation are not disclosed; share the full prompt templates and context construction to ensure reproducibility and enable prompt ablations.
- Inference hyperparameters (e.g., temperature, top‑p, top‑k, max tokens, stop sequences, repetition penalty) are unspecified; report and systematically vary them to quantify their impact on pass@1, speed, and failure modes.
- Only 6.7–9B models were tested; evaluate larger locally deployable models (e.g., 13B–70B with quantization) to determine the accuracy/latency/VRAM trade‑off ceiling for “local” use.
- Python was the sole target language; compare performance across languages (C++/Java/Go) to assess effects on Time Limit/Memory Limit errors and alignment with Kattis’ runtime constraints.
- Single‑attempt (pass@1) evaluation only; measure pass@k with multi‑sample strategies (self‑consistency, diverse decoding) and quantify improvements versus cost/time.
- No iterative repair loop was used; evaluate closed‑loop workflows (compile/run, capture error, re‑prompt/fix) and automated debugging agents on acceptance rates and failure reduction.
- Limited error forensics; categorize compile errors (syntax/indentation/imports), wrong answers (I/O formatting vs algorithmic), and runtime errors (exceptions vs resource limits) to target corrective interventions.
- Stochasticity is unaddressed; control and vary random seeds, repeat trials, and report variance/confidence intervals to understand performance stability.
- Cloud vs local comparison used different problem counts; perform matched‑set, controlled comparisons on identical Kattis subsets to eliminate dataset confounds.
- Context truncation is not analyzed; measure statement length distribution, check truncation events per model, and quantify correctness degradation versus context window size.
- Training data contamination is assumed but not measured; estimate Kattis problem presence in model pretraining (via near‑duplicate detection) and correlate with acceptance to assess “long‑tail” effects.
- Sampling strategy effects are unexplored; run ablations across decoding regimes (greedy, nucleus, beam, temperature sweeps) to map accuracy/speed trade‑offs.
- Energy/cost metrics for local inference are missing; log GPU/CPU utilization, energy consumption, and throughput to compare local vs cloud cost‑effectiveness.
- Generation time was reported but not normalized by tokens; collect tokens generated and compute tokens/sec to disentangle model speed from problem length.
- No formal correlation analysis between generation time and acceptance; compute correlations and partial correlations controlling for problem length and difficulty.
- Outliers were removed via the 1.5×IQR rule without further analysis; characterize the outlier cases to identify pathological prompts, models, or Kattis tasks that cause extreme latencies.
- Artifacts are not publicly released; publish the FACE extensions, Ollama configs, JSON schemas, and per‑problem submission logs to enable replication and meta‑analysis.
- Prompt engineering strategies were not tested; evaluate targeted I/O guidance, algorithmic templates, constraint reminders, and reasoning directives (e.g., “optimize for O(n log n)”) on correctness.
- Tool‑use and test‑generation were omitted; integrate unit‑test synthesis, local sample‑test execution, and verification strategies (e.g., property‑based tests) before submission.
- No error‑aware re‑prompting; design structured re‑prompt policies conditioned on failure type (compile vs wrong answer vs TLE) and measure iterative gains.
- Retrieval or summarization for long inputs is absent; test RAG or statement summarization to fit within context limits while preserving constraints and corner cases.
- Language‑specific runtime limits were not analyzed; quantify Time/Memory Limit Exceeded distribution by language choice and problem category to inform language selection.
- Difficulty stratification is coarse (Easy/Medium/Hard) with unclear mapping; align with Kattis’ 1.0–10.0 difficulty ratings and report per‑bin acceptance for finer‑grained insights.
- Untracked Kattis statuses were filtered out; list and analyze these statuses to determine whether additional failure modes inform remediation (e.g., “Judging errors,” “Presentation errors”).
- Per‑category algorithmic performance is missing; break down acceptance by topic (graphs, DP, geometry, greedy, string processing) to identify domain‑specific weaknesses.
- Fine‑tuning was proposed but not evaluated; run task‑specific fine‑tunes (e.g., Kattis‑style I/O + algorithmic patterns) and report gains versus base models.
- Concurrency and throughput are not studied; profile multi‑model/multi‑GPU scheduling, batch sizes, and server configurations to optimize wall‑clock time for large runs.
- Similarity/plagiarism risks are not assessed; compute code similarity (AST, token n‑grams) across models and problems to ensure uniqueness and avoid Kattis plagiarism flags.
- Kattis environment specifics (Python version, permitted libraries, time/memory policy) are not documented; standardize and disclose environment assumptions to reduce avoidable failures.
- Problem‑level outcomes are not released; provide per‑problem acceptance/failure details to facilitate targeted follow‑up studies and reproducibility checks.
- Sample test usage in prompts is not examined; test whether emphasizing samples biases solutions that overfit visible cases and fail hidden tests, and devise countermeasures.
- Chain‑of‑thought or plan‑then‑code prompting is not evaluated; compare direct code generation vs structured reasoning pipelines on acceptance and failure types.
- Warm‑up/caching effects on generation time are unknown; measure first‑call latencies vs steady‑state to ensure runtime statistics reflect typical usage.
Glossary
- Atomic file operations: File-system writes performed in an all-or-nothing manner to prevent partial or corrupted outputs during crashes or interruptions. "The system uses atomic file operations: The temporary results file is flushed and synced to disk before being renamed to its final JSON output."
- Box plot rule: A conventional outlier detection heuristic labeling values outside [Q1 − 1.5·IQR, Q3 + 1.5·IQR] as outliers. "we applied the conventional box plot rule and discarded any outliers."
- Checkpointing: Periodically saving progress so long-running processes can resume from the last save point after a failure. "adding robust checkpointing so multi-day runs can resume after failures."
- Context window: The maximum number of tokens a model can attend to in a single prompt/response. "context window size (in thousands of tokens)."
- Cumulative distribution function (CDF): A function giving the probability (or fraction) that a random variable is less than or equal to a given value; used to summarize latency distributions. "the corresponding cumulative distribution functions (CDF)"
- Deduplication: Removing duplicate data points from a dataset to improve training quality and reduce bias or leakage. "with extensive filtering and deduplication."
- Direct preference optimization: An alignment method that trains models directly on pairwise preference signals to better match desired outputs. "aligned through supervised fine-tuning and direct preference optimization."
- Flash Attention: An exact yet IO-aware, memory-efficient attention algorithm that speeds up Transformer attention computations. "optimized for code generation with Flash Attention"
- Infilling objective: A training objective where the model learns to fill in missing spans of text/code within a sequence. "using an infilling objective."
- Interquartile range (IQR): The spread between the 25th and 75th percentiles (Q3 − Q1), commonly used for robust dispersion and outlier detection. "to form the interquartile range:"
- Kattis: An online judge platform with a large, plagiarism-checked set of programming problems for benchmarking. "Kattis is a publicly available platform with more than 3,500 coding problems of varying difficulty and is widely used to evaluate programming proficiency."
- Long-tail information: Rare or underrepresented knowledge that is sparsely reflected in training data and thus harder for models to learn. "struggle with long-tail information"
- Ollama: A local LLM inference platform for running and managing models on on-premise hardware. "through the Ollama platform"
- Pass@k metrics: The probability that at least one of k generated attempts solves a problem; pass@1 is the single-try success rate. "The pass@ metrics represent the probability that at least one of solution attempts will succeed."
- Rate limits: Provider-imposed caps on the number of API requests over a time window that constrain large-scale experimentation. "Token quotas and rate limits hinder large-scale experiments"
- Supervised fine-tuning: Further training a pre-trained model on labeled examples to specialize behavior for a target task. "aligned through supervised fine-tuning and direct preference optimization."
- Token quotas: Limits on the total number of input/output tokens an API user can consume, affecting throughput and cost. "Token quotas and rate limits hinder large-scale experiments"
- VRAM: On-GPU memory used to hold model parameters and intermediate activations during inference/training. "consumer-grade GPUs (8 GB VRAM)"
Collections
Sign up for free to add this paper to one or more collections.

