- The paper presents LLMPerf, a framework that leverages a pre-trained large language model to predict GPU execution times solely from static OpenCL kernel code.
- It employs prompt engineering to integrate kernel details into a regression task, achieving robust predictive accuracy with a mean absolute percentage error of 24.25%.
- The work contributes a large-scale OpenCL kernel performance dataset and outlines a new research direction merging natural language processing with system-level performance modeling.
The paper "LLMPerf: GPU Performance Modeling meets LLMs" presents a novel approach to GPU performance modeling by leveraging the power of LLMs for estimating execution times of OpenCL kernels. This work highlights the bridging of LLM capabilities with traditional performance modeling tasks, offering a fresh perspective on automating and scaling performance predictions without relying on dynamic runtime information.
Introduction and Motivation
Current GPU performance modeling techniques predominantly employ either analytical or statistical models, each with its respective strengths and drawbacks. Analytical models require meticulous manual design by domain experts, which can become obsolete with system architecture changes. In contrast, statistical approaches often depend on runtime data, creating overhead and restricting usability. This research addresses the shortcomings of existing models by proposing a method that strictly relies on static program data, benefiting from the interpretative capabilities of LLMs. Specifically, the LLMPerf framework predicts execution times using only the OpenCL kernel source code, effectively ensuring uniform applicability across different OpenCL devices.
Dataset Generation
A key contribution of this paper is the introduction of a large-scale OpenCL kernel performance dataset. The dataset consists of kernel source codes primarily adapted from the BenchPress corpus, pre-processed for uniformity. Execution configurations are synthesized to explore a wide range of performance scenarios by simulating different execution environments.
The dataset creation includes implementing innovative techniques to generate kernel execution configurations automatically. It utilizes both simple and advanced strategies for input argument selection. The advanced strategy, informed by memory access patterns within kernel code, ensures that generated data is richly expressive, better representing diverse real-world performance characteristics.
Example of Execution Time Data
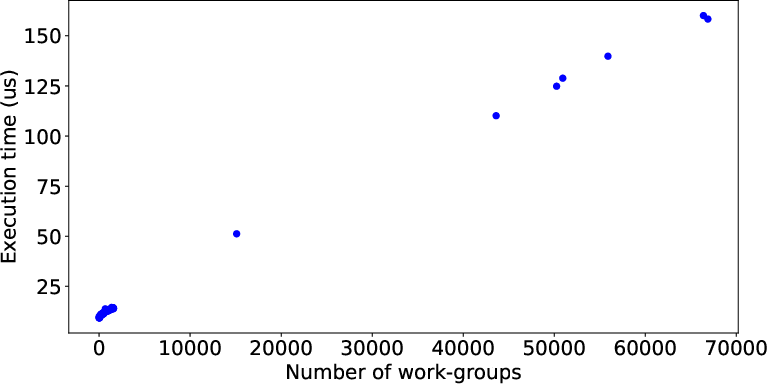
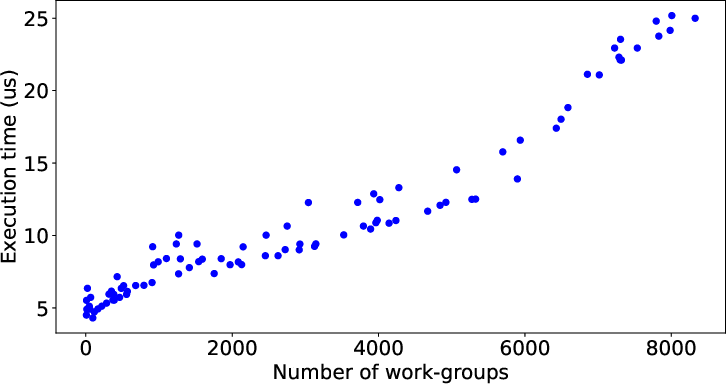
Figure 1: Example of execution time data before and after using IQR.
The use of statistical methodologies like Interquartile Range (IQR) improves the representational balance of execution times, thereby enhancing the learning potential for LLMs by addressing data distribution imbalances.
LLMPerf Model Architecture
LLMPerf advances prior works by harnessing the pre-trained CodeGen LLM, adapting it for a regression task dedicated to predicting GPU execution times. The model employs prompt engineering to structure kernel and execution settings into a comprehensible format for the LLM.
Prompt Engineering and Model Training
Strikingly, the model utilizes a customized prompt that integrates static kernel information such as argument details and execution sizes while eschewing runtime details. The LLM is fine-tuned on this dataset to predict execution times, with the training process optimizing for mean squared error in log-transformed execution times.
Evaluation
LLMPerf demonstrates significant predictive capacity across various experimental conditions using large-scale synthetic datasets and real-world OpenCL benchmarks. Notably, the model achieves a mean absolute percentage error (MAPE) of 24.25% on a comprehensive validation set, indicating high accuracy and robust generalization.
Figure 2 illustrates the performance prediction capabilities of LLMPerf when applied to various SHOC and Rodinia benchmarks. Despite the inherent complexity and diverse performance patterns of these benchmarks, the model shows significant accuracy in estimating execution times solely from code characteristics, underscoring its general applicability.
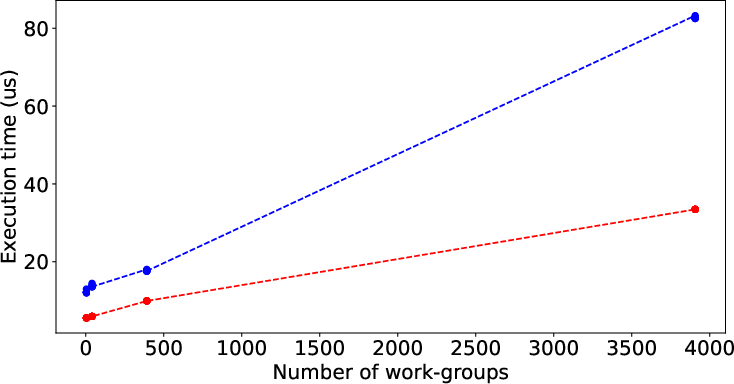
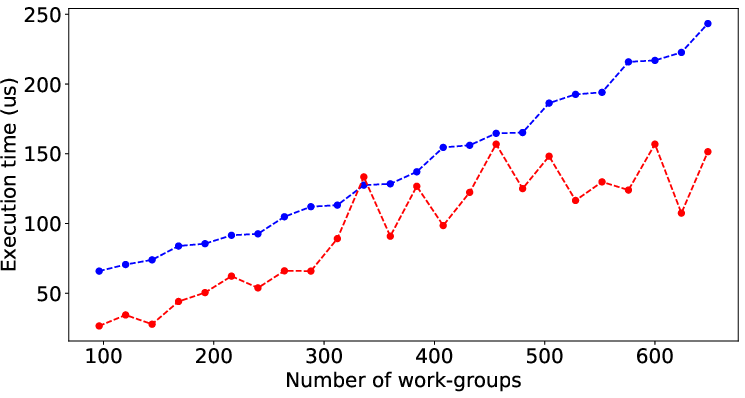
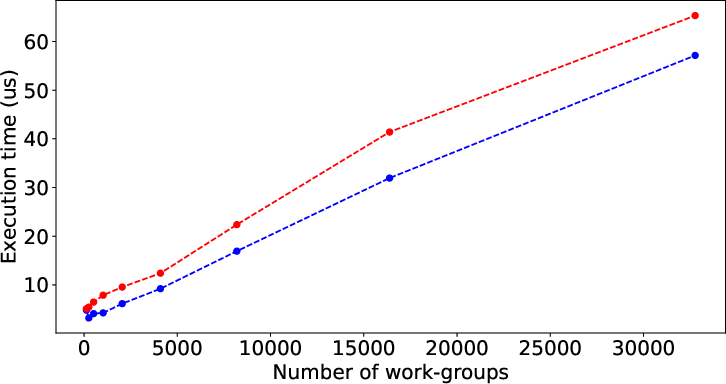
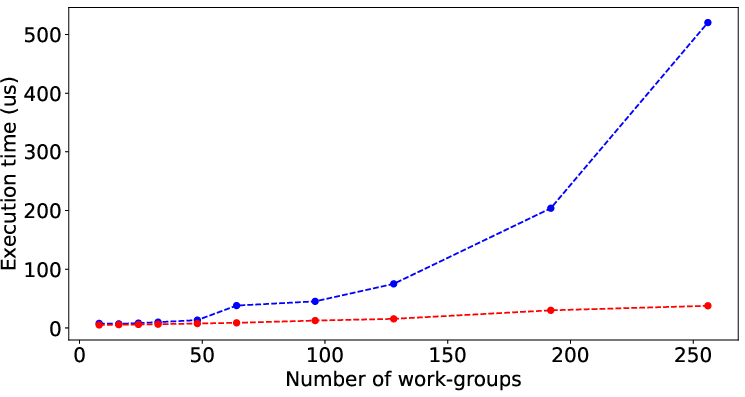
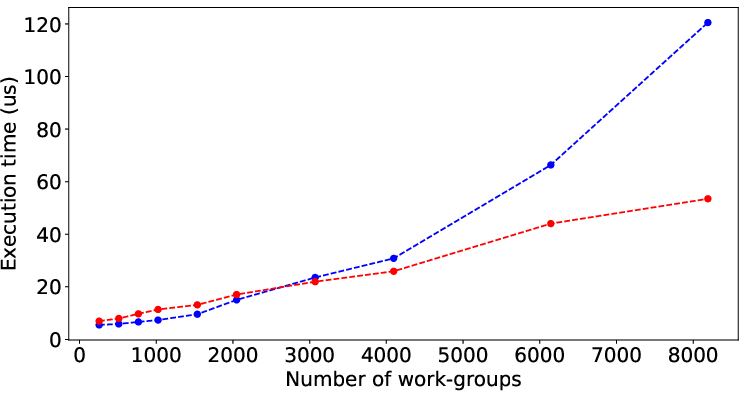
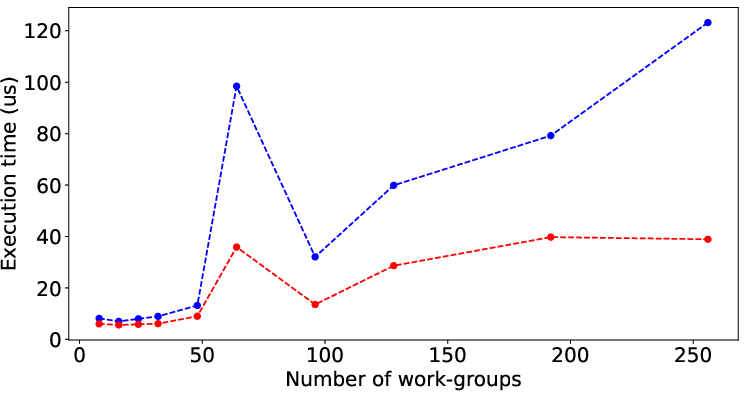
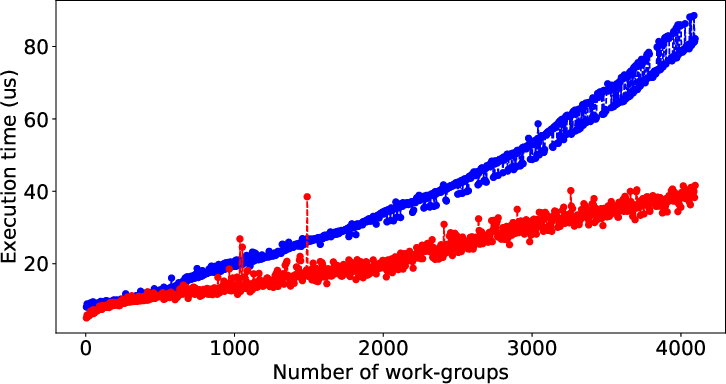
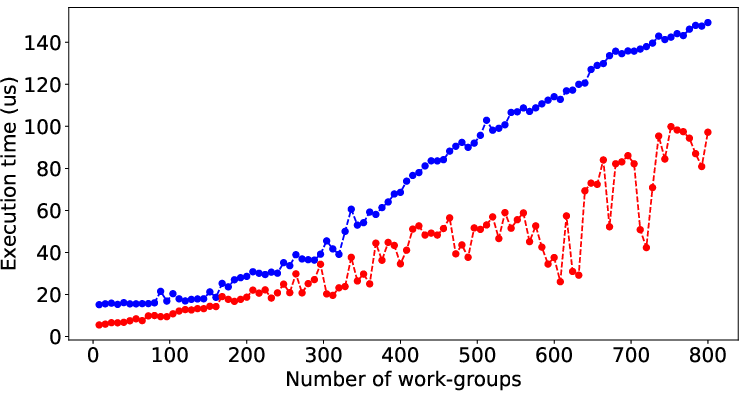
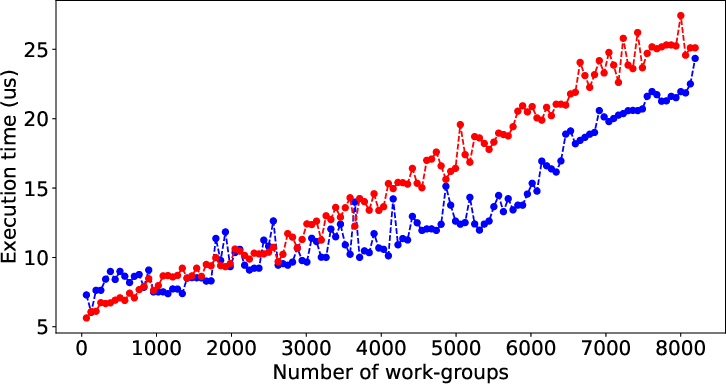
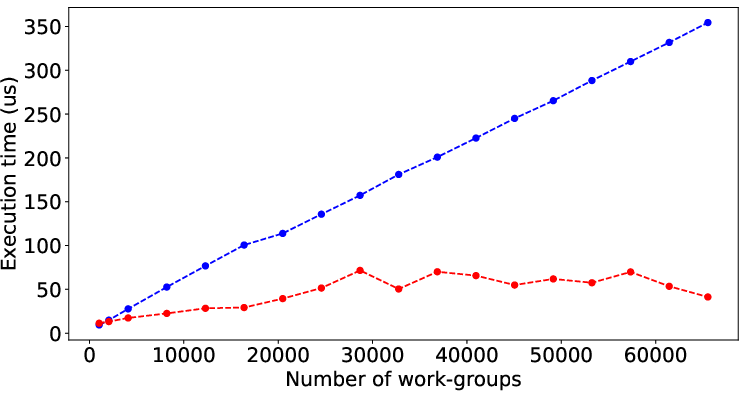
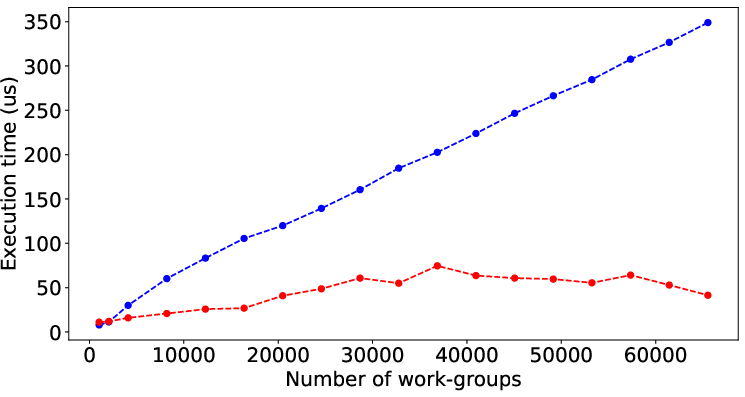
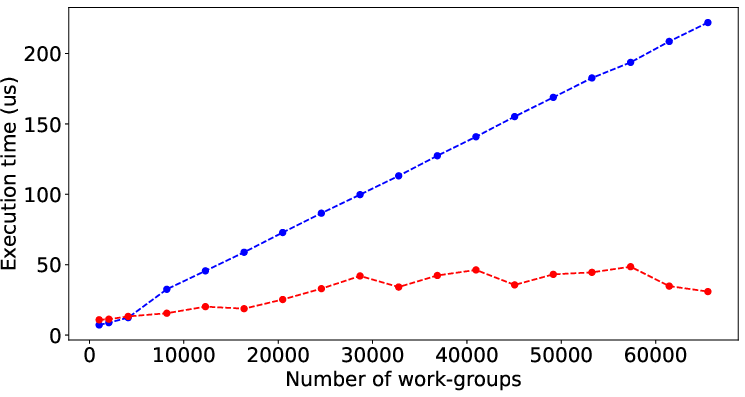
Figure 2: Result of LLMPerf on real benchmark kernels by data (input) size. Red points and blue points are prediction time and its corresponding target time.
Conclusion and Future Directions
The paper presents a pioneering integration of LLMs into the domain of GPU performance modeling, setting a precedent for future research that combines natural language processing capabilities with system performance tasks. While the LLMPerf model shows reliable performance, the paper identifies potential for further enhancement by incorporating larger and more diverse datasets as well as refining input selection methodologies. Prospective advances in this domain are likely to yield even greater improvements in predictive accuracy and model scalability. Furthermore, this approach opens avenues for leveraging AI models in broad system-level analysis tasks beyond the confines of traditional approaches.