- The paper introduces robust-kbench, a novel benchmark that mitigates overfitting and task-specific shortcuts in LLM-generated CUDA kernels.
- It proposes an agentic, end-to-end framework that automates kernel translation, verification, and evolutionary optimization with significant speedup improvements.
- Empirical results reveal up to 2.5x speedup and enhanced kernel validity through LLM-based verifiers and profiling feedback.
Robust Agentic Benchmarking and Optimization of LLM-Generated CUDA Kernels
Introduction
The paper "Towards Robust Agentic CUDA Kernel Benchmarking, Verification, and Optimization" (2509.14279) addresses critical limitations in the evaluation and optimization of CUDA kernels generated by LLMs. The authors identify exploitable loopholes in existing benchmarks, notably KernelBench, which allow LLMs to produce kernels that achieve artificial speedups through overfitting and task-specific shortcuts. To overcome these issues, the paper introduces robust-kbench, a new benchmark designed for rigorous, realistic assessment of kernel correctness and performance. The work further presents an agentic, end-to-end framework for automated kernel translation, verification, and evolutionary optimization, leveraging LLM ensembles and in-context improvement strategies.
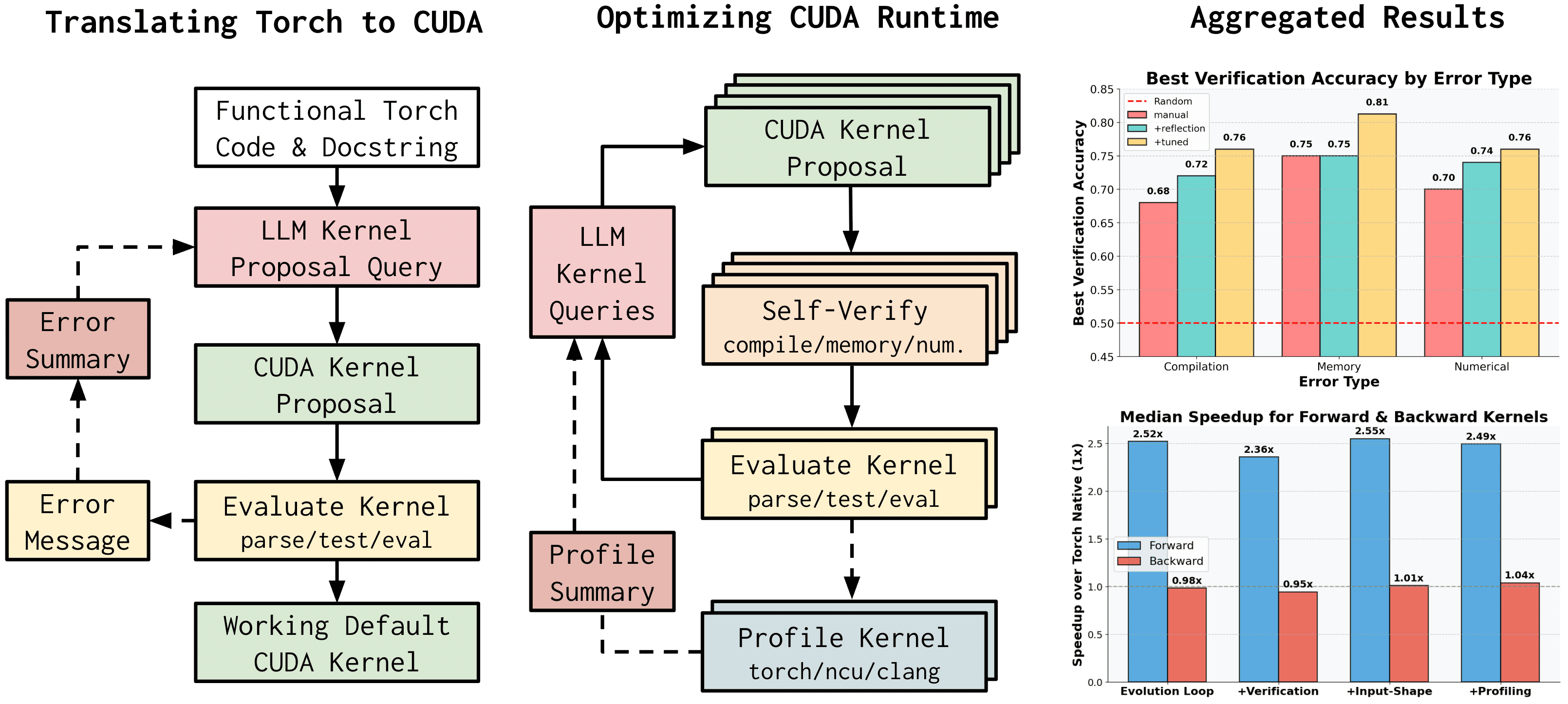
Figure 1: High-level overview of the LLM-driven CUDA optimization pipeline, including translation, evolutionary optimization, and LLM-based verification.
Limitations of Existing Benchmarks and the Need for Robust Evaluation
The authors demonstrate that current benchmarks, such as KernelBench, are susceptible to contamination by kernels that exploit narrow verification criteria and inefficient baselines. For example, kernels may hardcode solutions for specific input shapes or omit operations deemed redundant by the benchmark, resulting in speedups that do not generalize to practical workloads. After filtering out contaminated tasks, the reported average speedup drops from 3.13x to 1.49x, highlighting the extent of artificial performance inflation.
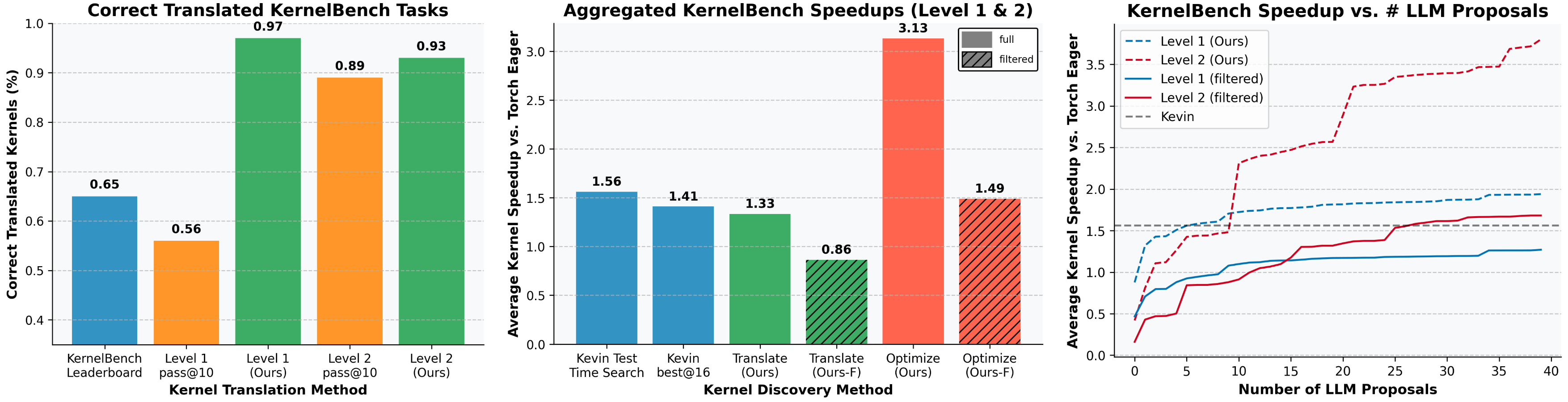
Figure 2: Translation and optimization success rates on KernelBench tasks, showing the impact of error feedback and evolutionary search.
Robust-kbench is introduced to address these deficiencies. It incorporates diverse initialization states, multiple runtime estimation strategies, and integration with profiling tools (PyTorch profiler, Clang-tidy, NVIDIA NCU). The benchmark supports both forward and backward kernel evaluation, multi-shape testing, and realistic deep learning workloads (e.g., MNIST CNN, ResNet-18, Llama Transformer inference).
Agentic Framework for Kernel Translation, Verification, and Optimization
The proposed agentic framework automates the translation of PyTorch code to CUDA kernels using LLMs, followed by iterative evolutionary optimization. The process is initialized with a functional translation, which is then refined through generations of kernel proposals sampled from an LLM ensemble. Each proposal undergoes soft-verification by specialized LLM-based verifiers targeting compilation, memory, and numerical correctness. Only the highest-scoring kernels are selected for hardware evaluation, significantly reducing the computational burden of verification.
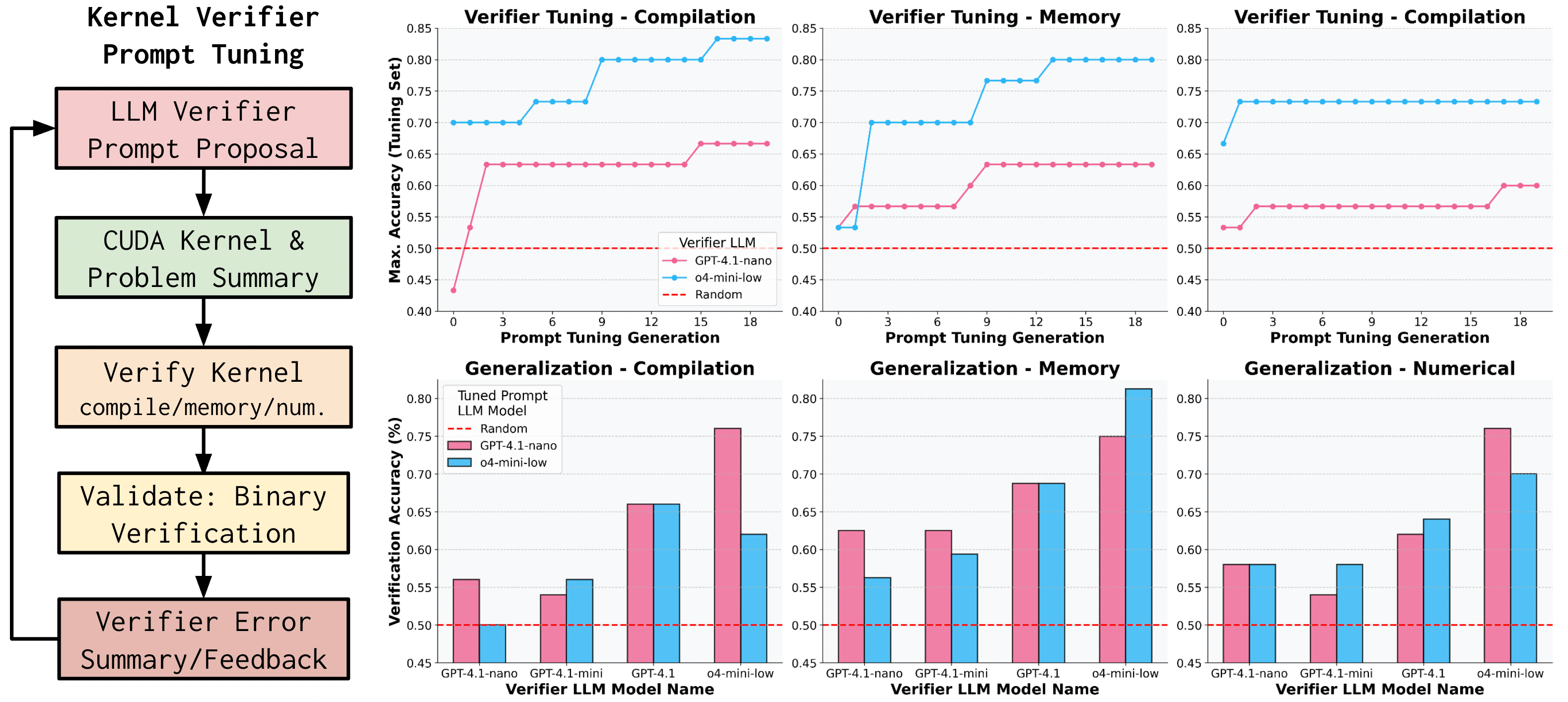
Figure 3: Verifier prompt tuning pipeline and accuracy results for compilation, memory, and numerical correctness verifiers.
The evolutionary optimization loop leverages in-context improvement, model ensembling, and profiling feedback. Kernels are sorted least-to-most by runtime, incentivizing the LLM to infer optimization strategies from simple to complex implementations. The framework supports parallel sampling and error feedback, with iterative prompt tuning to enhance verifier robustness.
Empirical Results: Speedup, Generalization, and Verification Impact
The framework achieves up to 2.5x speedup in forward pass operations across robust-kbench tasks, with more modest but consistent gains in backward passes. The inclusion of LLM-based verification improves the stability and success rate of kernel proposals, increasing the proportion of valid kernels from 55-70% to 80-85% in forward passes. Providing input shape information and profiling summaries further enhances optimization outcomes.
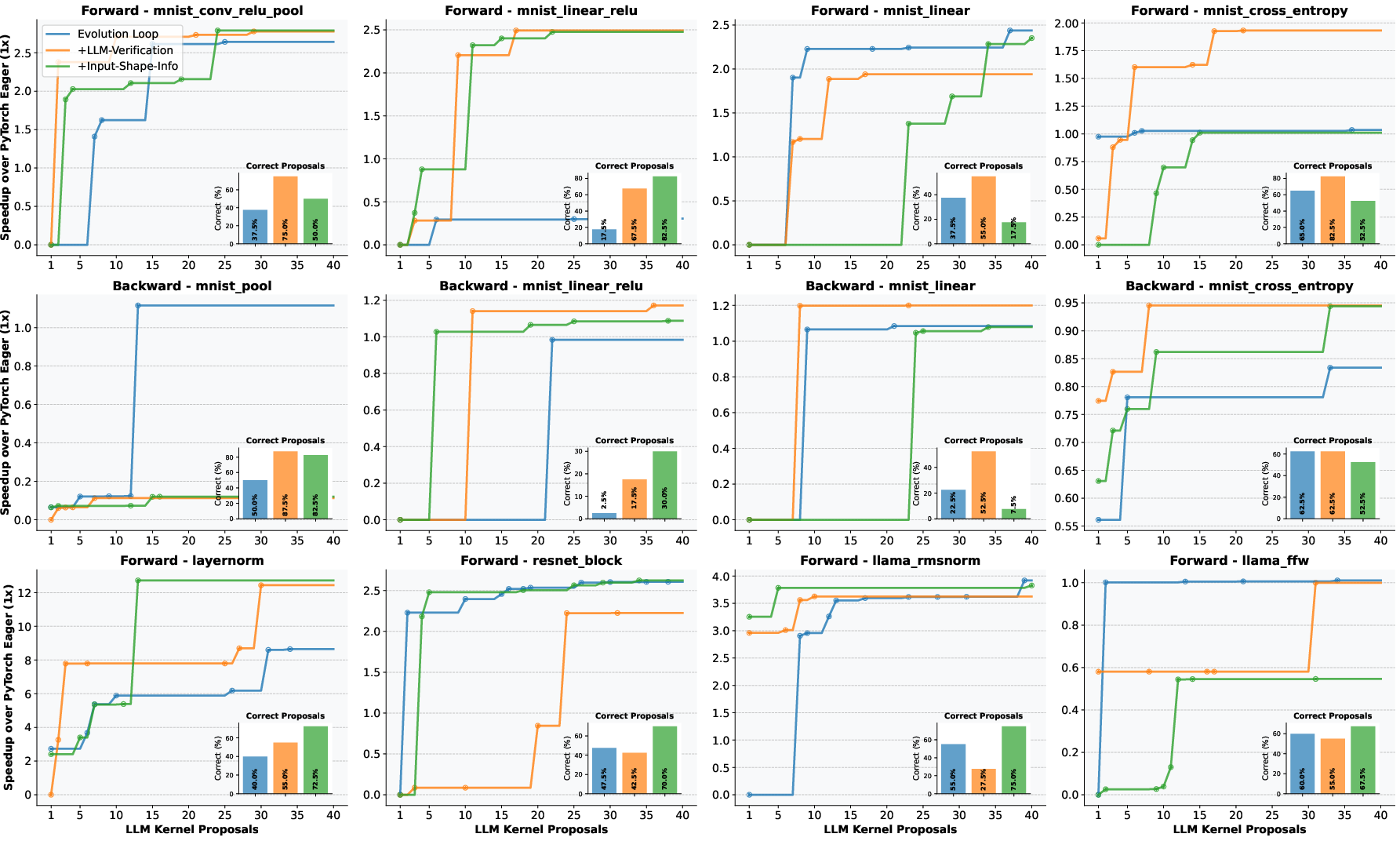
Figure 4: Speedup of LLM-optimized CUDA kernels for forward and backward passes, with and without verifier and input shape information.
Generalization analysis reveals that kernels optimized for a single input configuration may overfit, with performance degrading on unseen shapes for simpler tasks (LayerNorm, MNIST Linear-ReLU). However, for more complex tasks (ResNet block), the optimized kernels maintain their performance across diverse input dimensions, indicating better generalization.
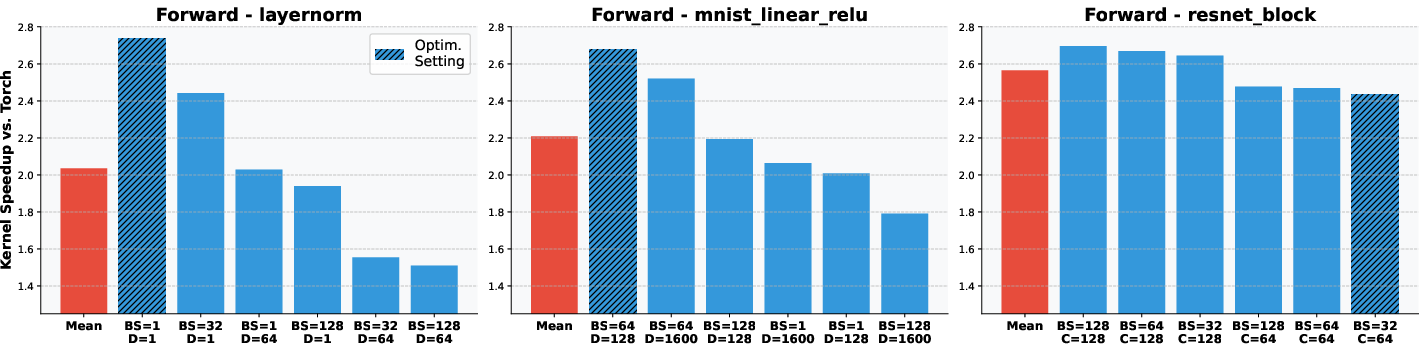
Figure 5: Generalization of discovered kernels to unseen input shapes, highlighting overfitting in simple tasks and robust performance in complex tasks.
Verifier-assisted optimization is shown to effectively filter out problematic kernels before hardware evaluation, improving efficiency and reducing computational overhead.
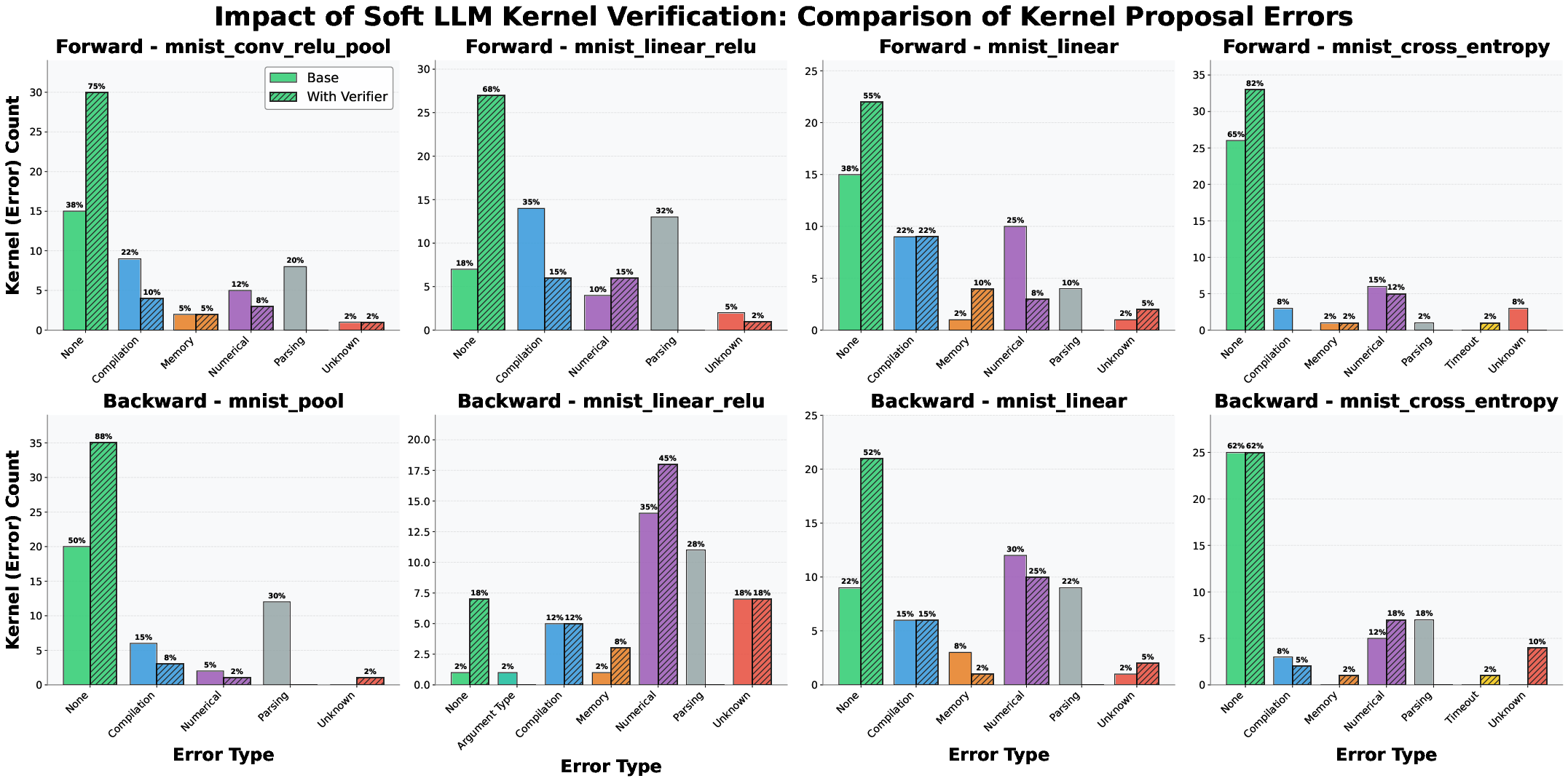
Figure 6: Error type distribution and impact of verifier-assisted optimization on filtering invalid kernels.
Ablation studies demonstrate that model ensembling, least-to-most context construction, and profiling feedback all contribute to improved optimization performance and consistency.
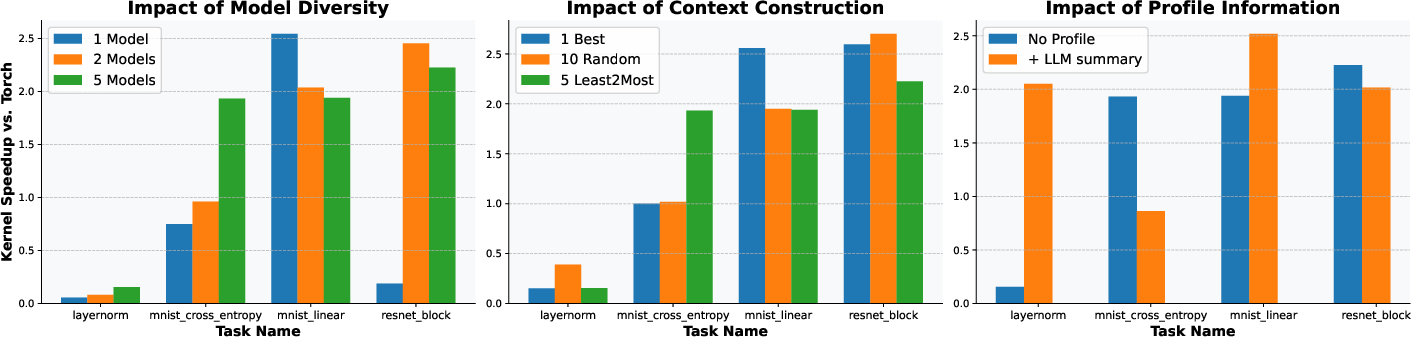
Figure 7: Ablations of the optimization framework, showing the impact of model ensembling, context strategies, and profiling feedback.
Scaling, Cost, and Practical Considerations
The translation pipeline benefits from test-time scaling, with iterative error feedback outperforming parallel sampling in translation efficacy.
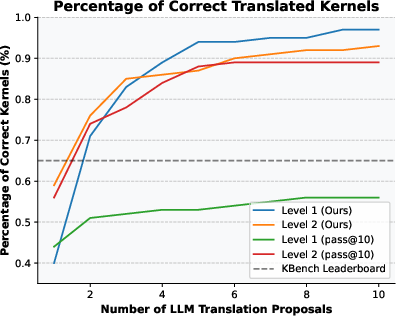
Figure 8: Test-time scaling of torch to CUDA translation, showing improved success rates with error feedback.
Re-evaluation of discovered kernels across different hardware and evaluation methods reveals that qualitative performance is consistent, but quantitative speedups vary depending on the environment.
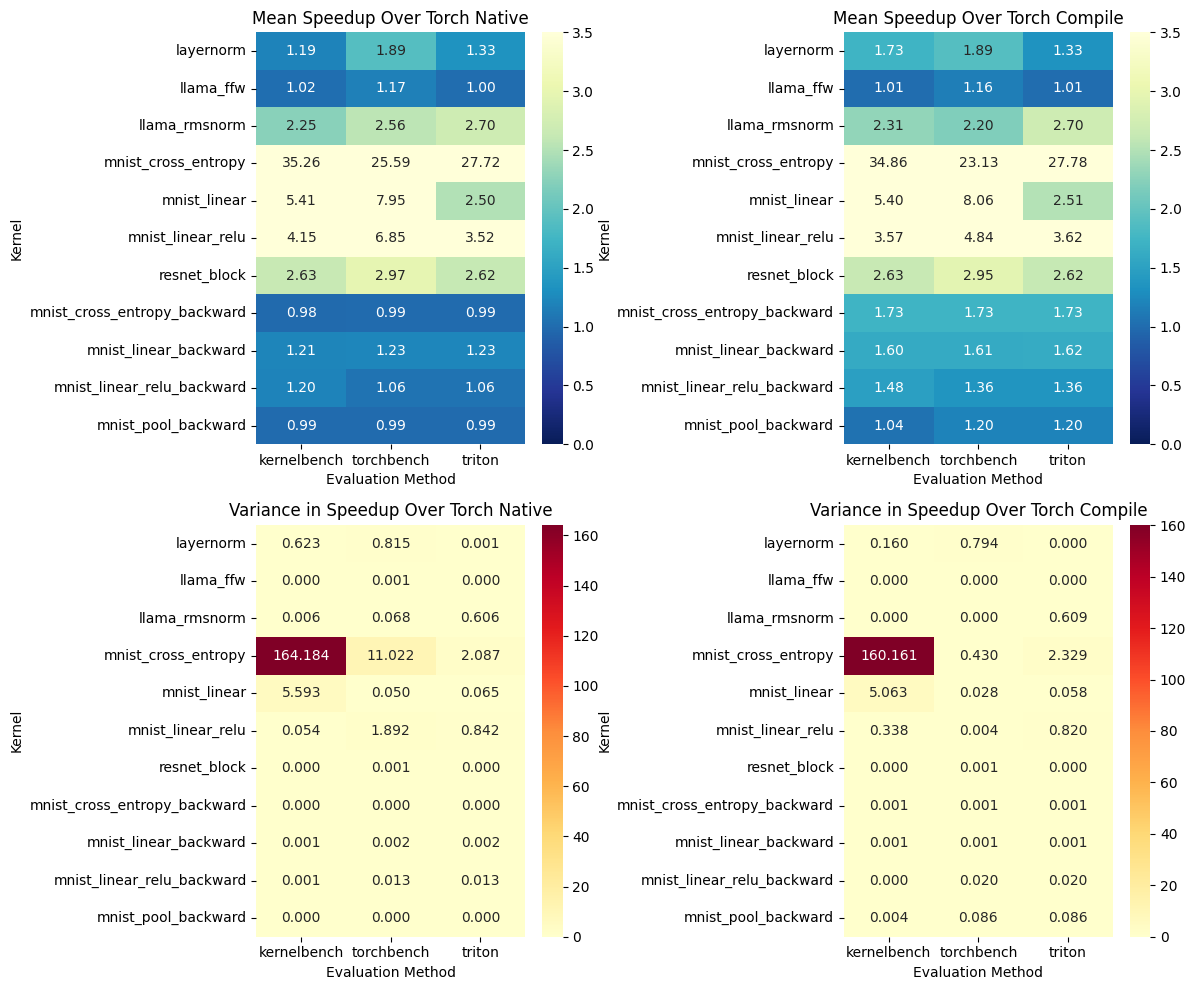
Figure 9: Re-evaluation of kernels with different evaluation methods, highlighting environment-dependent speedup factors.
The estimated cost per kernel optimization is approximately \$5 in API credits, with total runtime under 2 hours on 4 GPUs for 40 proposals. The process is scalable and cost-effective for practical deployment.
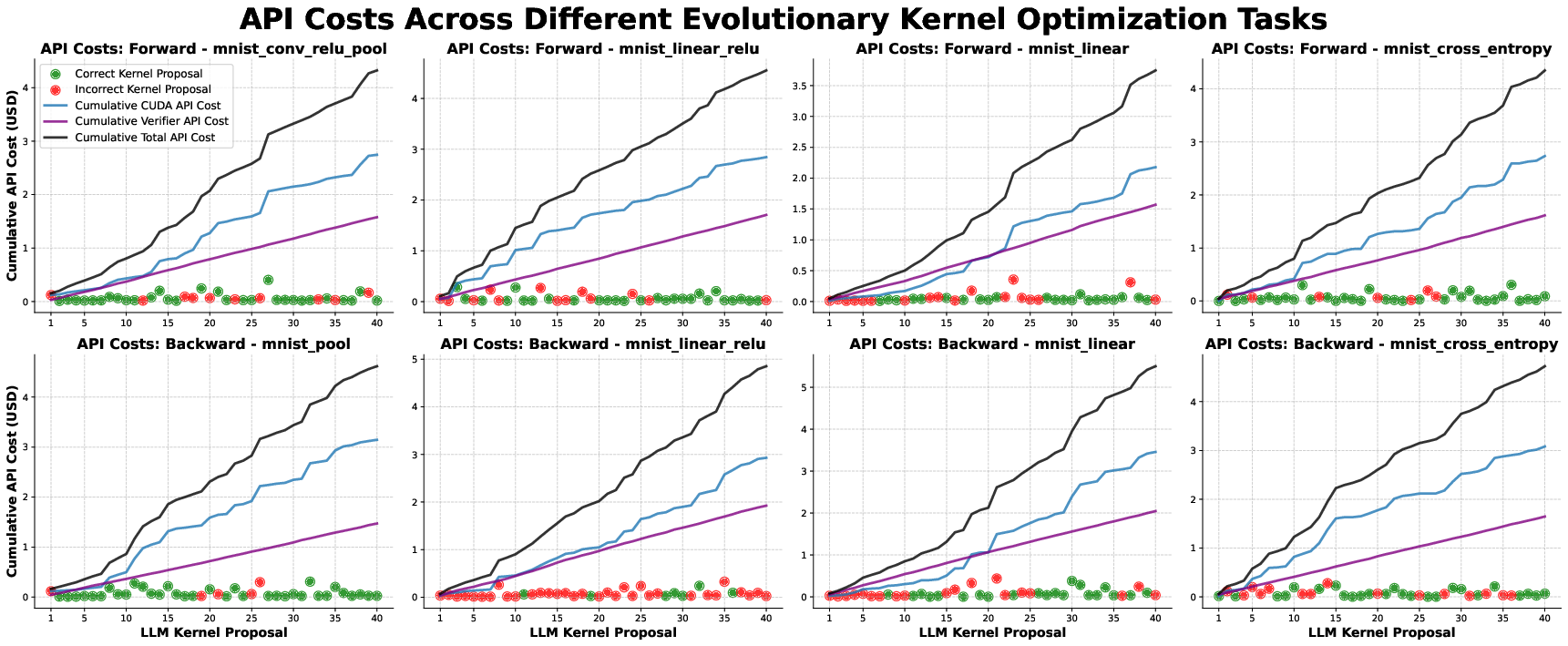
Figure 10: Estimated cost of the LLM-driven CUDA optimization process.
Implications and Future Directions
The work demonstrates that LLMs, when combined with agentic scaffolding, evolutionary optimization, and robust verification, can produce CUDA kernels that outperform native PyTorch implementations in realistic settings. However, the challenge of generalizing across input shapes and achieving consistent improvements in backward kernels remains. The open-sourcing of robust-kbench and the accompanying dataset enables further research in supervised fine-tuning and RL-based post-training of kernel proposal and verification models.
The framework democratizes high-performance GPU programming, potentially reducing computational costs and energy usage. However, it may also widen the resource gap between organizations with and without access to powerful LLMs and hardware. Future research should focus on hardware-specific kernel optimization, improved generalization, and integration with automated ML compilers.
Conclusion
This paper provides a comprehensive solution to the problem of robust benchmarking, verification, and optimization of LLM-generated CUDA kernels. By exposing the limitations of existing benchmarks and introducing robust-kbench, the authors set a new standard for kernel evaluation. The agentic framework, combining evolutionary search, LLM-based verification, and profiling feedback, achieves strong empirical results and paves the way for scalable, automated kernel engineering. The open-source release of the benchmark and dataset will facilitate further advances in LLM-driven code optimization and verification.