- The paper introduces a novel asynchronous streaming RL framework that decouples tasks, achieving up to 2.03× throughput improvement over traditional methods.
- It presents the TransferQueue module that enables efficient concurrent data management and dynamic task scheduling in RL workflows.
- The design supports engine-agnostic integration and dynamic load balancing, enhancing scalability across diverse computing environments.
AsyncFlow: An Asynchronous Streaming RL Framework for Efficient LLM Post-Training
The paper "AsyncFlow: An Asynchronous Streaming RL Framework for Efficient LLM Post-Training" presents an innovative approach to address the challenges of reinforcement learning (RL) in the post-training phase of LLMs. The framework aims to overcome the scalability limitations of traditional task-collocated RL systems and the inefficiencies in task-separated RL approaches.
Introduction
AsyncFlow introduces a novel asynchronous streaming RL framework to enhance the post-training efficiency of LLMs. Traditional RL frameworks face two major challenges: scalability bottlenecks due to task-colocation and complex dataflows with underutilized resources in task-separated setups. Existing frameworks are often tightly integrated with specific training or inference engines, limiting flexibility. AsyncFlow addresses these issues through a decoupled architecture that supports a wide range of backends, allowing for dynamic load balancing and pipeline overlapping.
System Architecture
AsyncFlow's architecture consists of several layers:
- Resource Layer: Utilizes Ray for computing resource management and optimized hardware allocation.
- Backend Layer: Provides modular adapters compatible with various training and inference engines, maintaining engine-agnostic RL task execution.
- Optimization Layer: Implements the TransferQueue for data management and an asynchronous workflow to maximize computational resource utilization.
- Interface Layer: Offers a unified algorithm entry point and service-oriented APIs for seamless integration into different infrastructures.
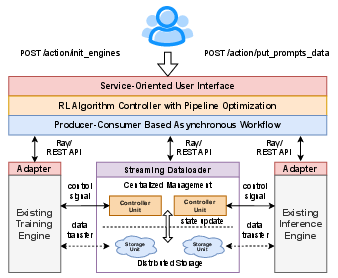
Figure 1: System overview of AsyncFlow framework.
TransferQueue, a centralized data management module, is a cornerstone of AsyncFlow. It supports asynchronous, distributed data storage and transfer, enabling efficient handling of data dependencies across RL tasks.
Architecture Design
TransferQueue separates the data plane from the control plane, managing task-specific data components in a 2D columnar format to support concurrent read/write operations.
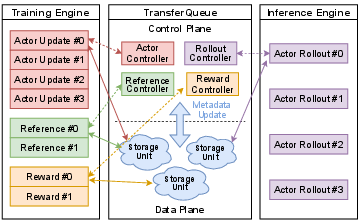
Figure 2: Architecture design of TransferQueue, showing metadata communication and data handling processes.
The control plane provides a centralized view of data statuses, updated via metadata notifications when new data is available. This setup enables real-time dynamic allocation of tasks, reducing idle times and improving load balancing in RL workflows.
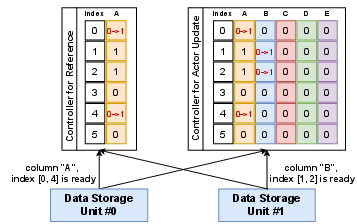
Figure 3: Metadata notification process ensures controllers are updated with new data availability.
Asynchronous Workflow Optimization
AsyncFlow implements an asynchronous workflow to minimize pipeline bubbles and hardware idling by overlapping RL tasks.
Delayed Parameter Update
A delayed parameter update mechanism allows continuous actor rollout, even as updates are processed, avoiding synchronization overhead and extending the steady phase of RL pipelines.

Figure 4: Asynchronous off-policy RL workflow leveraging the delayed parameter update mechanism.
Scheduling and Resource Planning
Using a hybrid cost model combining analytical and profiling-based methods, AsyncFlow optimizes resource allocation, minimizing end-to-end execution times of RL workflows.
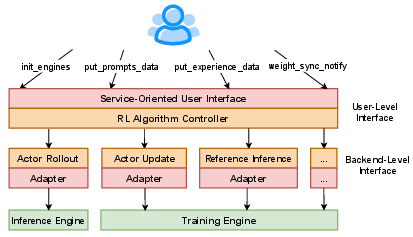
Service-Oriented User Interface
AsyncFlow's interface design separates algorithm-specific tasks from backend operations:
Evaluation
Extensive experiments demonstrate that AsyncFlow achieves up to 2.03× throughput improvement over state-of-the-art baselines in large-scale settings. The task-separated architecture exhibits superior scalability and resource utilization compared to task-collocated systems.
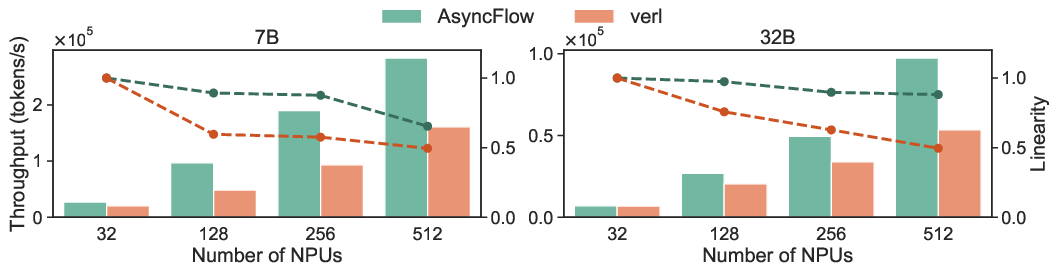
Figure 6: End-to-end throughput and scalability analysis underscore AsyncFlow's advantages in large clusters.
Conclusion
AsyncFlow effectively bridges the gap between research and industrial applications by providing a scalable and flexible framework for LLM post-training. Future developments may include further optimization of actor rollout and parameter updates to enhance the sub-step asynchronous workflow. The proposed innovations in data management and task scheduling pave the way for more efficient RL systems, particularly in large-scale AI deployments.