- The paper introduces an adaptive framework that selects retrieval strategies based on query complexity to optimize QA accuracy and efficiency.
- It employs a classifier that distinguishes simple, moderate, and complex queries, switching between no retrieval, single-step, and multi-step approaches.
- The framework outperforms traditional methods by effectively balancing computational costs with improved performance on diverse QA datasets.
Adaptive-RAG: Learning to Adapt Retrieval-Augmented LLMs through Question Complexity
The paper "Adaptive-RAG: Learning to Adapt Retrieval-Augmented LLMs through Question Complexity" presents a novel adaptive framework for improving open-domain question answering (QA) systems by dynamically selecting appropriate retrieval strategies based on query complexity. This work addresses the limitations of previous approaches that either lead to unnecessary overhead for simple queries or fail to handle complex multi-step queries effectively.
Introduction
Recent advances in LLMs have shown remarkable performance across various tasks. However, these models often produce factually incorrect answers due to their reliance on parametric knowledge. Retrieval-augmented LLMs, which incorporate external, non-parametric knowledge, have gained attention for enhancing response accuracy. This augmentation is particularly useful in QA tasks, where LLMs retrieve relevant documents from a knowledge base and generate answers based on this augmented information.
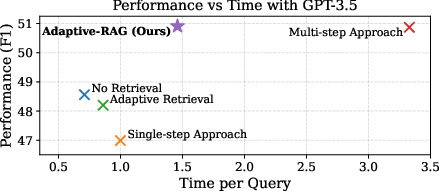
Existing retrieval-augmented systems typically utilize a single-step approach for simple queries or a multi-step approach for complex queries. The challenge arises from the variability in query complexity, which current systems do not adequately address. To overcome this, the authors propose an adaptive QA framework that dynamically selects between retrieval-augmented strategies based on query complexity.
Adaptive-RAG Framework
The Adaptive-RAG framework is built on a classifier that predicts the complexity of incoming queries. This classifier influences the choice between three processing strategies:
- No Retrieval: Directly using the LLM for straightforward queries.
- Single-Step Retrieval: Retrieving documents once for moderately complex queries.
- Multi-Step Retrieval: Iteratively retrieving documents and refining answers for complex queries.
The framework's adaptive nature allows it to balance computational efficiency and accuracy by tailoring the strategy to each query's complexity. This adaptive capability is crucial in real-world deployments where queries range in complexity.

Figure 1: A conceptual comparison of different retrieval-augmented LLM approaches to question answering.
The authors evaluate Adaptive-RAG on several open-domain QA datasets featuring both single-hop and multi-hop queries. The results demonstrate superior performance of Adaptive-RAG over baseline systems, highlighting its capability to optimize latency and accuracy dynamically.
Trade-offs and Implementation Considerations
Implementing Adaptive-RAG involves training the query complexity classifier using automatically collected labels, derived from the models' response accuracy and dataset biases. This training process does not require human annotations, reducing the resources needed for deployment.
The framework's flexible switching between retrieval strategies implies varying computational costs:
- Simple Queries: Using only the LLM, minimizing retrieval overhead.
- Moderate Queries: Benefits from a single retrieval step, balancing speed and reliability.
- Complex Queries: The multi-step approach incurs higher computational costs due to repeated accesses but is essential for achieving high accuracy.
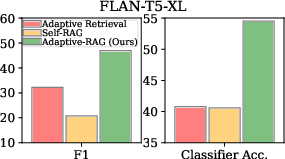
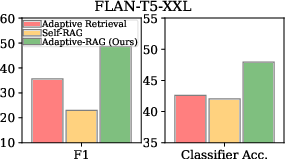

Figure 3: Performance on QA and query-complexity assessment with different adaptive approaches.
Conclusion
Adaptive-RAG significantly enhances the QA systems' performance by adapting dynamically to query complexity. Its ability to oscillate between non-retrieval, single-step, and multi-step strategies ensures efficient handling of diverse queries, making it well-suited for scalable and cost-effective real-world applications. Future directions include refining the complexity classifier and exploring additional granularity in query assessments, which would further optimize its operational efficiency and precision.