- The paper proposes the 'Thinker' task, a multi-stage QA framework that leverages Dual Process Theory to enhance LLM reasoning.
- It decomposes the reasoning process into fast thinking, verification, slow thinking, and summarization to improve efficiency and accuracy.
- Empirical results demonstrate up to a 4% accuracy improvement in models like Qwen2.5-1.5B, highlighting significant token efficiency gains.
Thinker: Learning to Think Fast and Slow
Introduction
The paper "Thinker: Learning to Think Fast and Slow" (2505.21097) proposes a novel task framework, Thinker, that leverages Dual Process Theory to enhance the reasoning capabilities of LLMs through a structured, multi-stage approach to Question-Answering (QA). This framework decomposes the QA task into four distinct stages: Fast Thinking, Verification, Slow Thinking, and Summarization, each designed to target specific capabilities such as intuition, evaluation, refinement, and integration. This approach aims to address inefficiencies in existing reinforcement learning (RL) applications for reasoning in LLMs, particularly the challenge of long and redundant responses resulting from imprecise search behaviors.
Methodology
Fast Thinking Stage: The initial stage, Fast Thinking, restricts the model to generate a concise response within a strict token budget. The intent is to cultivate the model’s ability to identify promising search paths rapidly, akin to the intuitive capabilities of System 1 in Dual Process Theory.
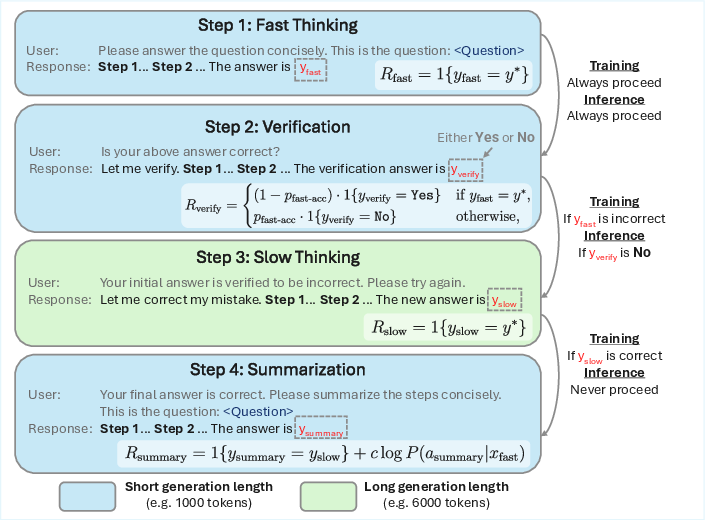
Figure 1: The four-step Thinker task. Each stage involves a user prompt, model response, and specific rewards and transition conditions designed to train distinct agent capabilities (intuition, evaluation, refinement, and integration).
Verification Stage: This stage allows the model to evaluate the correctness of the Fast Thinking response using a longer token budget, offering distinct rewards for correct verifications. It mirrors the more deliberate evaluation processes of System 2.
Slow Thinking Stage: If the initial response fails verification, the model engages in Slow Thinking to refine the initial ideas, employing a deliberate and extensive reasoning process with a generous token budget. This stage emphasizes error correction and alternative path exploration.
Summarization Stage: The final stage requires the model to summarize the reasoning steps, reinforcing concise and coherent solution paths. This reinforces effective reasoning patterns valuable for improving the model's intuition.
This task setup isolates reward signals specific to each stage to enhance the targeted capabilities effectively, encouraging a synergistic interplay between intuitive and deliberative reasoning.
Results
Empirical evaluation of the Thinker task demonstrates notable improvements in reasoning tasks over standard QA approaches. For the Qwen2.5-1.5B model, accuracy improved from 24.9% to 27.9%, while DeepSeek-R1-Qwen-1.5B saw an increase from 45.9% to 49.8%. These improvements were achieved with efficient inference, particularly in the Fast Thinking mode, which reached 26.8% accuracy with less than 1000 tokens, highlighting significant efficiency gains.
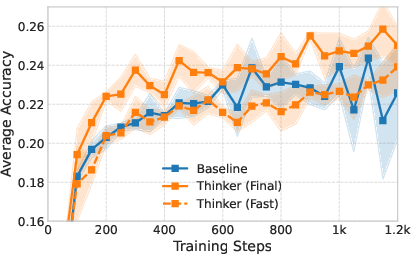
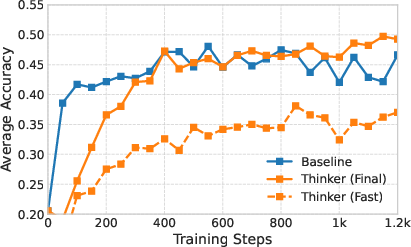
Figure 2: Evaluation performance across seven common benchmarks. For the Qwen2.5-1.5B model, the shaded region represents the standard deviation across three independent seeds.
Analysis and Implications
The Thinker task offers a structured approach to RL in LLMs, emphasizing distinct strategies to improve different cognitive processes. By harnessing targeted training for separate reasoning components, agents can achieve better generalization and efficiency.
The framework's design aligns with cognitive theories of decision-making and offers a practical method to implement structured task design in RL environments. It underscores the potential of environment augmentation in RL, suggesting that bespoke task structures can lead to significant performance enhancements.
This study's insights prompt further exploration into enhancing RL environments to capitalize on focused skill development. Potential research trajectories include adaptive task enrichment based on agent capabilities and further refinement of task decomposition methods for improved AI reasoning abilities.
Conclusion
"Thinker: Learning to Think Fast and Slow" (2505.21097) provides a new perspective on improving LLM reasoning via a structured QA task decomposition. Its success hints at broader implications for RL task design and presents a compelling case for further exploration and application of Dual Process Theory in AI development. As LLMs continue to evolve, structured, multi-stage tasks could pave the way for more advanced and efficient reasoning models.

