- The paper presents DualMindVLM, a visual language model that adaptively selects fast or slow reasoning modes based on query complexity, reducing token consumption by up to 40%.
- It introduces a two-stage reinforcement learning process using mode auto-labeling (via output length) and group relative policy optimization to balance concise and detailed responses.
- Evaluations on benchmarks such as MathVista and ScienceQA demonstrate that DualMindVLM maintains state-of-the-art accuracy while significantly cutting computational costs.
Learning to Think Fast and Slow for Visual LLMs: DualMindVLM
Motivation and Problem Statement
The proliferation of Visual LLMs (VLMs) with step-by-step (System 2) reasoning capabilities has led to advances in complex visual question answering (VQA) tasks. Yet, these models frequently enforce detailed reasoning for both simple and complex queries, inducing substantial computational inefficiency—so-called "overthinking"—and elevated token costs. The paper "Learning to Think Fast and Slow for Visual LLMs" (2511.16670) introduces DualMindVLM, a VLM augmented with an adaptive, dual-mode (System 1+2) thinking process. Inspired by dual-process theories of human cognition, DualMindVLM automatically selects between concise, fast responses for simple queries and comprehensive, multi-step reasoning for complex questions, offering superior token efficiency without compromising accuracy.
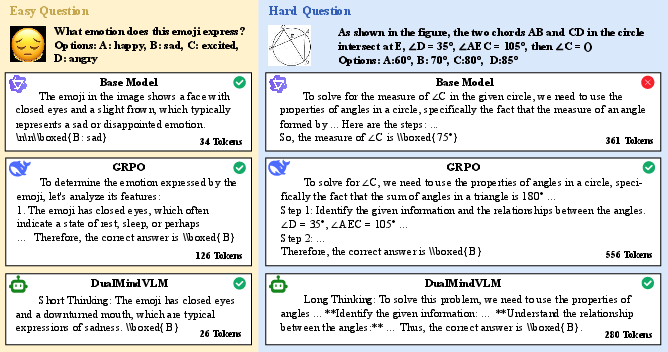
Figure 1: DualMindVLM dynamically balances response length by offering concise answers for simple queries and detailed reasoning for complex ones, unlike models that produce unnecessarily verbose outputs for all queries.
Methodology
DualMindVLM is trained through a two-stage reinforcement learning (RL) regimen, designed to produce self-supervised data annotations for thinking modes and adaptively optimize for both token efficiency and correctness.
Stage 1: Mode Auto-Labeling via Output Length
A base VLM model is used to generate multiple responses per question in the training set. The mean output length serves as a proxy for task complexity: samples with mean response lengths below a threshold (e.g., <100 tokens) are labeled as "fast thinking," while those above (e.g., >200 tokens) are labeled "slow thinking." This heuristic is justified empirically—tasks requiring complex reasoning (e.g., mathematics or chart understanding) induce longer responses, while perceptual tasks yield shorter ones.
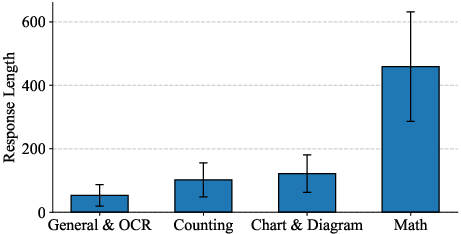
Figure 2: The average response length of a pre-trained VLM across diverse VQA tasks substantiates the use of output length as an implicit signal for problem complexity.
Stage 2: Dual-Mode RL Training
DualMindVLM employs Group Relative Policy Optimization (GRPO), leveraging both mode-labeled and free-form rollouts per sample. The RL objective combines answer correctness and compliance with the prescribed thinking mode prefix ("Short Thinking:" or "Long Thinking:") as rewards:
- Prefix-conditioned rollouts are guided using the annotated mode.
- Free-form rollouts allow the model to self-select a mode, enabling robust acquisition of automated mode selection.
Hybrid response sampling and dual-mode-specific prompting act as control signals for learning and evaluation.
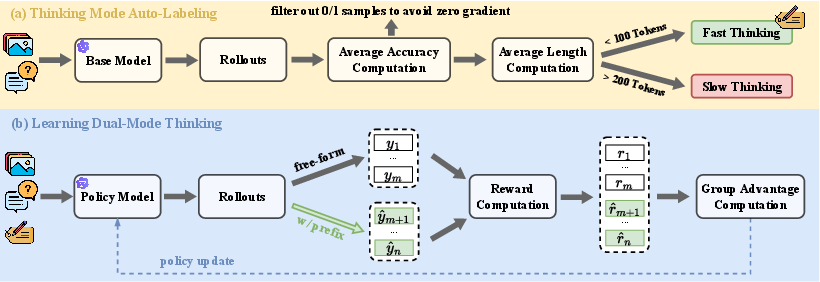
Figure 3: DualMindVLM's training pipeline comprises mode annotation and dual-mode RL, jointly optimizing both explicit guidance and self-judgment across candidate responses.
Experimental Validation
DualMindVLM is evaluated on a suite of challenging multimodal reasoning benchmarks spanning mathematics (MathVista, MathVision), science (ScienceQA, AI2D), and general VQA (MMStar, MMbench). The results substantiate the central claims of the paper:
- Token Efficiency: DualMindVLM achieves state-of-the-art or highly competitive accuracy while reducing token consumption by up to 40% compared to other reasoning VLMs.
- Adaptive Mode Selection: The model adapts its mode selection to problem complexity, defaulting to fast thinking for perceptual tasks and slow thinking for complex reasoning.
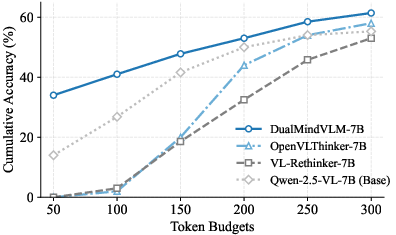
Figure 4: DualMindVLM sustains higher accuracy under tight token budgets relative to competing models, highlighting its computational efficiency.
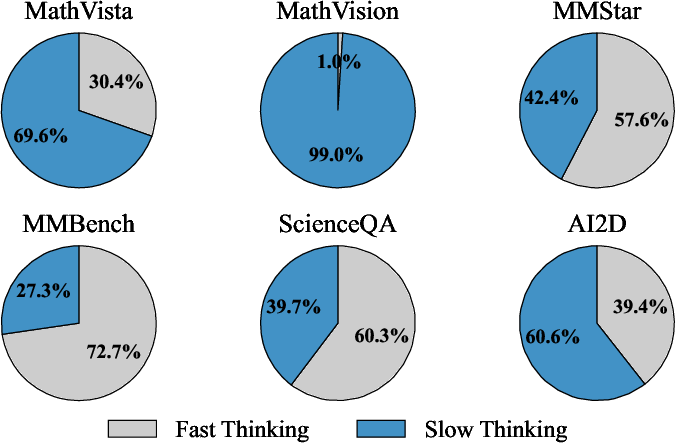
Figure 5: The ratio of slow to fast thinking is dynamically tuned by DualMindVLM, with the model favoring slow thinking for benchmarks like MathVista while selecting fast thinking for perceptual challenges.
- Ablation Studies: Mode auto-labeling and dual-mode RL are essential. Without them, models degenerate into always selecting the fast mode (mode collapse) or revert to standard "System 2 only" reasoning, leading to redundant outputs and impaired performance.
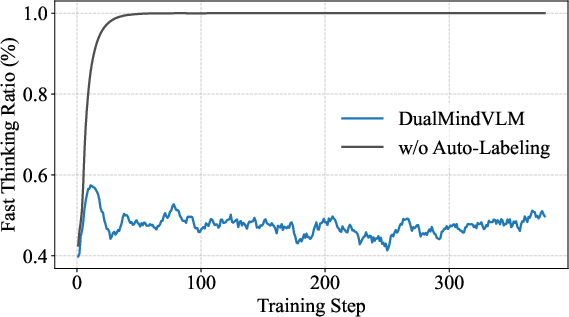
Figure 6: Without auto-labeling, models collapse to only fast thinking; with the full pipeline, a well-balanced mode allocation is achieved.
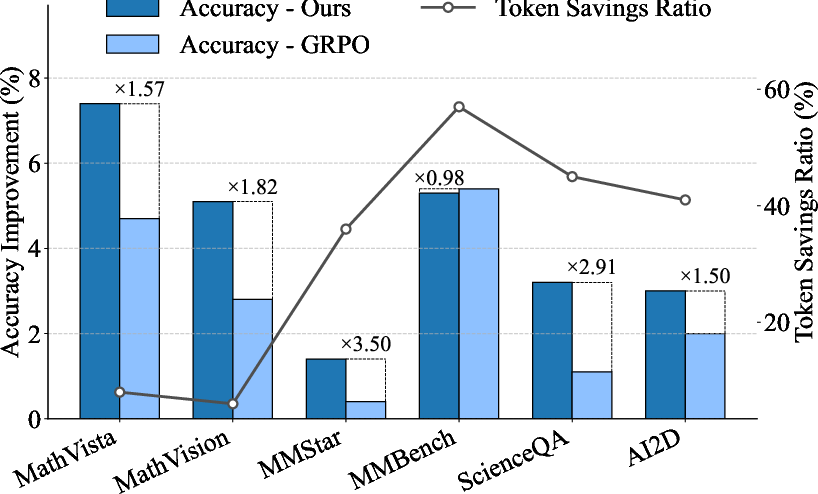
Figure 7: DualMindVLM demonstrates superior net accuracy gains and token savings relative to base and System-2-only RL models.
- Response Analysis: DualMindVLM demonstrates flexible allocation of cognitive effort, producing concise responses for simple queries and allocating longer, multi-step chains for complex cases.
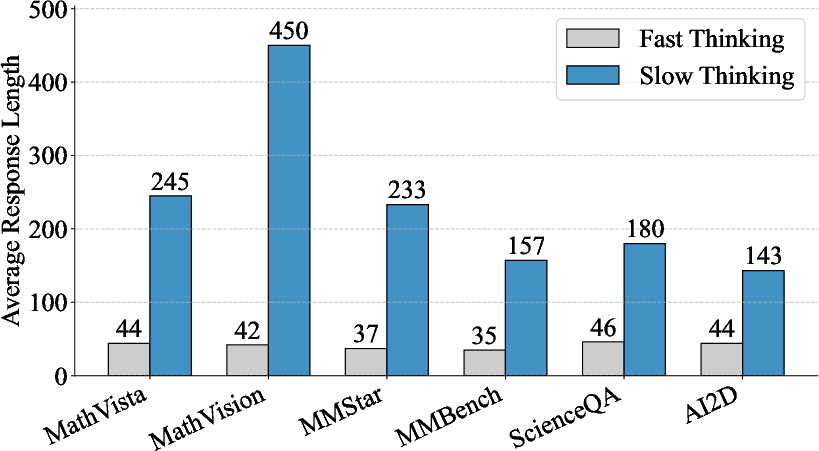
Figure 8: Average response lengths reinforce that fast-thinking responses are stable and concise, while slow-thinking outputs scale with problem intricacy.
Failure Modes and Limitations
DualMindVLM inherits limitations from the hard thresholding in mode labeling, leading to occasional bias and incorrect mode selection, especially when training distributions induce heuristics specific to certain data domains. Figure 9 illustrates a case where training data induces a bias toward fast thinking for chart-related tasks, resulting in a suboptimal failure.

Figure 9: Example of incorrect mode selection, underscoring the challenge of modality-induced biases.
The model's reliance on output length as a proxy for task complexity, while robust at scale, does not accommodate all forms of nuanced multimodal reasoning—potentially overlooking some instances where short yet hard-to-solve questions arise. Further, iterative human-in-the-loop labeling remains a potential avenue for mitigating these weaknesses.
Hallucination and Robustness
DualMindVLM also demonstrates lower incidence of hallucinated outputs compared to competing reasoning models, as assessed on the HumbleBench hallucination benchmark. Its dual-mode design appears to encourage epistemic humility—conciseness in simple cases and thoroughness in complex ones—mitigating generator-induced hallucination.
Case Study and Scalability
Qualitative analyses reinforce that DualMindVLM’s adaptive reasoning generalizes across question types (scene-based, chart-based, diagrammatic, and scientific VQA), and the method is effective at both 7B and 3B parameter scales. Larger training sets further boost reasoning on complex tasks, evidencing scalable gains for high-difficulty domains.

Figure 10: For diagram-based VQA, DualMindVLM truncates unnecessary reasoning for easy cases compared to System-2-only models.

Figure 11: For scientific VQA, DualMindVLM extends reasoning only when needed, matching or exceeding accuracy while offering token economy.
Practical and Theoretical Implications
Practically, DualMindVLM sets a blueprint for deploying VLMs in resource-constrained environments (e.g., edge AI or cloud-serving scenarios with tight inference budgets), offering a route toward greener, cost-effective multimodal deployment. Theoretically, the methodology introduces a triply aligned approach: cognitive alignment through dual-mode thinking, task-adaptive computation allocation, and reinforcement-based scalable training.
The paradigm invites future research in:
- Soft/hierarchical mode selection and continuous reasoning control,
- Data-centric RL approaches that optimize beyond static heuristics,
- Hybridization with external modules for even finer-grained complexity estimation and personalized adaptation,
- Application to domains beyond VQA, including planning and robotic perception.
Conclusion
DualMindVLM demonstrates that equipping VLMs with fast-and-slow thinking capabilities using a simple yet effective self-supervised RL protocol yields models that automatically allocate computational resources to problem complexity. This approach achieves state-of-the-art accuracy/token efficiency trade-offs and reduces overthinking on simple tasks. The framework advances the design of reasoning systems that better mimic human cognition and sets the stage for more efficient, adaptive, and robust multimodal AI (2511.16670).

