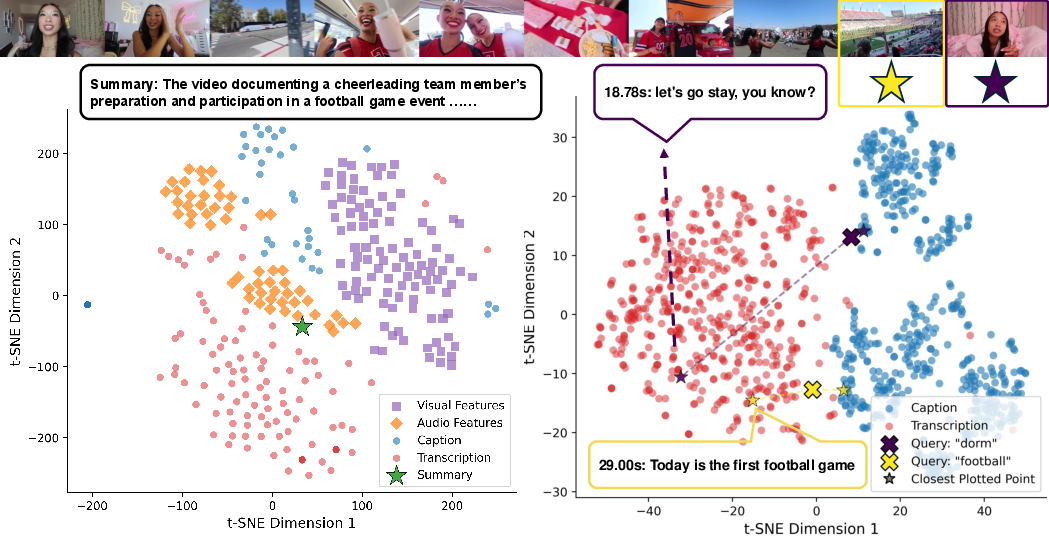
- The paper introduces HippoMM, a hippocampal-inspired model that segments continuous audiovisual data into discrete episodes for long event understanding.
- It employs a four-stage process—temporal pattern separation, perceptual encoding, memory consolidation, and semantic replay—using models like ImageBind and Qwen2.5-VL.
- Experimental results on the HippoVlog benchmark show a state-of-the-art 78.2% accuracy, balancing fast semantic retrieval with detailed recall.
HippoMM: Hippocampal-inspired Multimodal Memory for Long Audiovisual Event Understanding
Introduction
The paper "HippoMM: Hippocampal-inspired Multimodal Memory for Long Audiovisual Event Understanding" presents a novel biomimetic architecture designed to address the challenges of processing and understanding long-form audiovisual data. Current approaches often fail to effectively integrate and retrieve information from continuous, multimodal streams. In contrast, HippoMM draws inspiration from the human hippocampus, known for its ability to form, store, and retrieve integrated episodic memories from complex multimodal experiences.
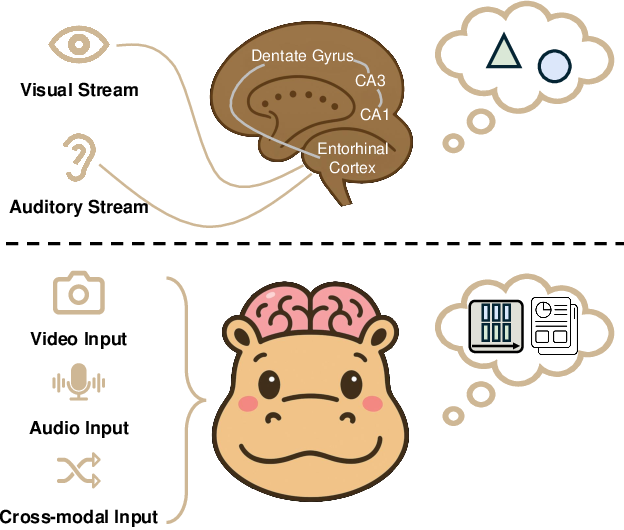
Figure 1: Conceptual overview of hippocampal versus HippoMM multimodal processing. The biological hippocampus and the proposed architecture show analogous processes for episodic memory formation and retrieval.
System Architecture
The memory formation in HippoMM advances through four main stages: Temporal Pattern Separation, Perceptual Encoding, Memory Consolidation, and Semantic Replay.
- Temporal Pattern Separation: Inspired by the hippocampus's ability to delineate experiences into discrete episodes, this stage analytically segments continuous audiovisual inputs based on perceptual boundaries. This process ensures that the system effectively identifies significant audiovisual changes, using metrics such as SSIM for visual inputs and audio energy levels for auditory inputs.
- Perceptual Encoding: Employs a dual-modal strategy to encode visual and auditory inputs into a multimodal representation using pre-trained models like ImageBind and Whisper. The collected data is stored in ShortTermMemory objects that provide a structured representation of the segment.
- Memory Consolidation: Similar to biological memory processes that stabilize and optimize memory storage, this stage reduces redundancy by filtering similar consecutive segments based on cross-modal embedding similarity, thus forming a more efficient and organized long-term memory.
- Semantic Replay: Functions like hippocampal replay during sleep, converting detailed perceptual information into abstracted semantic summaries using LLMs such as Qwen2.5-VL. These summaries form the core of ThetaEvent objects, encapsulating the semantic gist of each experience.
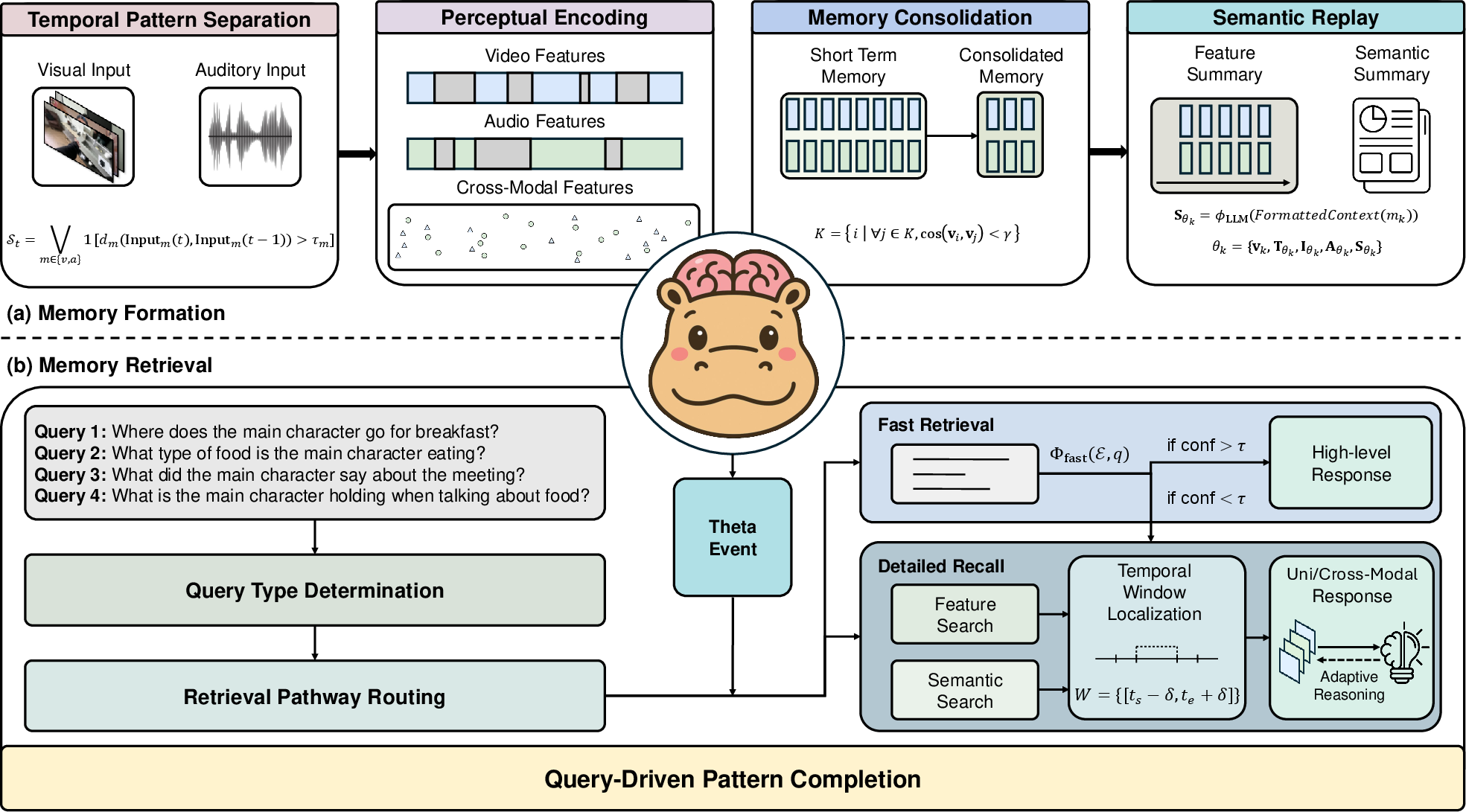
Figure 2: The HippoMM architecture for multimodal memory, illustrating the phases of Memory Formation.
Memory Retrieval
Memory retrieval in HippoMM consists of a hierarchical retrieval architecture that handles user queries efficiently:
Experimental Results
HippoMM was evaluated on the HippoVlog benchmark, excelling in both accuracy and speed compared to existing methods. The architecture achieved a state-of-the-art average accuracy of 78.2% across multimodal tasks, a significant improvement over competing models like Video RAG. The dual retrieval pathways—fast retrieval and detailed recall—ensured that the system maintained efficiency with a balanced average response time of 20.4 seconds.
Ablation studies showed that removing components like detailed recall or adaptive reasoning impacted accuracy, illustrating the synergistic importance of each element in the model's hierarchy. Generalization evaluations on datasets like Charades confirmed HippoMM's robust applicability to long-form audiovisual understanding tasks.

Figure 4: Retrieval pathway analysis reveals dynamics between fast and detailed pathways based on response time and accuracy.
Conclusion
HippoMM demonstrates the potential of integrating hippocampal-inspired principles into computational architectures for improved multimodal memory processing. By effectively mimicking neural processes of memory formation, consolidation, and retrieval, the system outperforms traditional methods in handling long-form audiovisual content. Future work may refine the architecture's ability to handle open-domain queries and explore further alignment of memory mechanisms with biological models.