- The paper introduces a heterogeneous memory structure that integrates motion and appearance features to improve VideoQA.
- It features a redesigned question memory and an LSTM-based multimodal fusion layer for refined attention across modalities.
- Experimental evaluations on TGIF-QA, MSVD-QA, MSRVTT-QA, and YouTube2Text-QA demonstrate significant performance gains over existing methods.
Heterogeneous Memory Enhanced Multimodal Attention Model for Video Question Answering
Introduction
The paper "Heterogeneous Memory Enhanced Multimodal Attention Model for Video Question Answering" introduces an advanced framework to address the complexity inherent in VideoQA tasks. These tasks necessitate the model's ability to correlate visual content sequences in videos with complex query semantics, and derive answers from these associations.
(Video Figure 1)
Figure 1: VideoQA is a challenging task as it requires the model to associate relevant visual contents in frame sequence with the real subject queried in question sentence.
Model Architecture
The proposed model consists of three primary components:
- Heterogeneous Video Memory: This module integrates motion and appearance features from videos. It employs a memory structure with read and write operations that jointly learn spatiotemporal attention across frames (Figure 2). Unlike conventional single-stream processing, this approach enables the model to capture comprehensive video contexts by attending synchronously to motion and appearance.
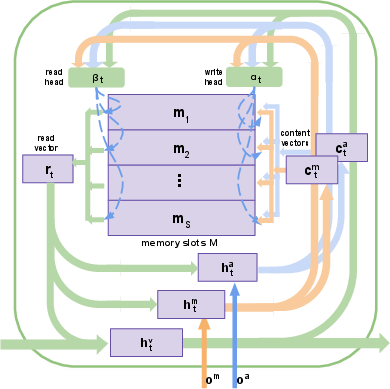
Figure 2: Our designed heterogeneous visual memory which contains memory slots M, read and write heads α,β, and three hidden states hm,ha,hv.
- Redesigned Question Memory: To adequately handle the semantic complexities of questions, a refined question memory was developed (Figure 3). This component combines local word details with global contextual insights, providing enriched question feature representations for subsequent multimodal analysis.
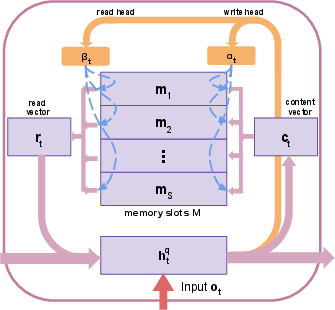
Figure 3: Our re-designed question memory with memory slots M, read and write heads α,β, and hidden states hq.
- Multimodal Fusion Layer: This layer utilizes an LSTM controller to perform iterative reasoning and integrates video and question features through a learned attention mechanism. The process refines joint feature attention across multiple steps, enhancing final decision accuracy (Figure 4).
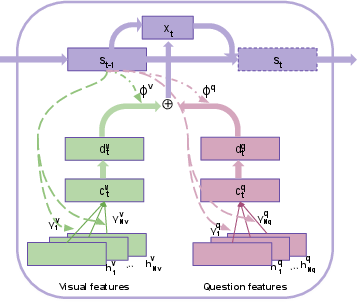
Figure 4: Multimodal fusion layer. An LSTM controller with hidden state st attends to relevant visual and question features, and combines them to update current state.
Experimental Evaluation
The experimental results indicate that the proposed framework achieves substantial improvements over existing state-of-the-art VideoQA models across several benchmark datasets. The use of a heterogeneous memory structure and multimodal fusion significantly boosts the model's ability to draw meaningful connections between complex visual and textual data.
Comparative Analysis and Results
The model was evaluated against existing methods such as ST-VQA and Co-Mem on benchmark datasets including TGIF-QA, MSVD-QA, MSRVTT-QA, and YouTube2Text-QA. Notable findings include:
- TGIF-QA: Demonstrated a reduction in counting error and improvement in action and transitional question performance.
- MSVD-QA and MSRVTT-QA: Achieved superior performance in 'what' and 'who' question types despite the inherent dataset class imbalances.
- YouTube2Text-QA: Outperformed existing methods by a significant margin in both multiple-choice and open-ended question tasks, even without additional supervisory signals.
Visualizations and Interpretations
The attention mechanism's effectiveness is depicted through attention heatmaps on key frames and words. Examples illustrate the model's capacity to focus on relevant video segments and query words, emphasizing its ability to comprehend complex questions.
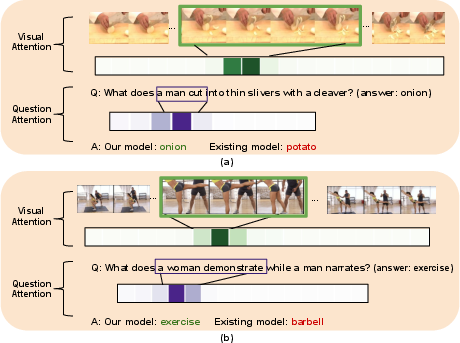
Figure 5: Visualization of multimodal attentions learned by our model on two QA exemplars. Highly attended frames and words are highlighted.
Conclusion
The integration of heterogeneous memory and an advanced multimodal attention approach in VideoQA tasks facilitates a profound understanding of video and question interactions, leading to significant performance gains. The model's innovative architecture showcases its potential to handle the complexity of real-world VideoQA applications effectively. Further research can explore scalability to larger datasets and the incorporation of additional multimodal data.

