- The paper presents two scalable algorithms that improve test-time compute efficiency, demonstrating provably diminishing failure probabilities with increased compute.
- The knockout-style algorithm generates multiple candidate solutions and aggregates them through pairwise comparisons, achieving exponential error decay when both candidate count and comparisons are scaled.
- The league-style algorithm evaluates candidates based on average win rates, proving robustness to imperfect comparisons and offering practical methods for reliable large language model inference.
Provable Scaling Laws for the Test-Time Compute of LLMs
Introduction
The paper proposes two scalable algorithms for improving the test-time compute efficiency of LLMs and establishes provable scaling laws governing their performance. The focus is on a knockout-style algorithm and a league-style algorithm, both demonstrating that their failure probability decays to zero as test-time computation increases. These methods do not require a verifier or reward model, relying only on the generation and comparison capabilities of black-box LLMs.
Knockout-Style Algorithm
The knockout-style algorithm involves two stages: generation of candidate solutions and aggregation through a knockout tournament.
Generation Stage: Multiple candidate solutions are generated following a chain-of-thought (CoT) prompting approach. The expectation is that at least one correct solution will emerge with non-zero probability.
Aggregation Stage: Candidates undergo a series of pairwise comparisons to identify the winner at each round until a final solution is selected.
Provable Guarantees
Two notable results are presented. First, when both the number of candidates N and the number of pairwise comparisons K increase, the failure probability diminishes exponentially. Second, scaling only N suffices for the failure probability to diminish by a power law, even for fixed K.
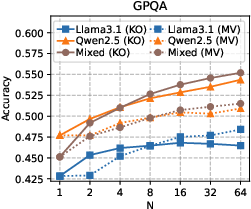
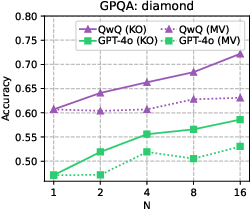
Figure 1: Accuracy versus the number of initial candidates N for the knockout-style algorithm (KO), as well as for majority voting (MV), a strong baseline widely adopted in practice.
League-Style Algorithm
The league-style algorithm evaluates candidates based on their average win rate against subsampled opponents. This contrasts with the knockout strategy of elimination after a single loss.
Under the assumption that "correct-and-strong" solutions exist, which have higher average win rates against all incorrect solutions, the failure probability decays exponentially. The model tolerates imperfect comparison capabilities, thus offering robustness against systematic errors in pairwise judgments.
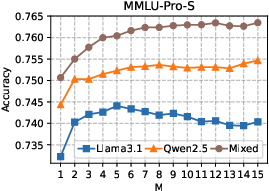
Figure 2: Empirical results for the league-style algorithm on MMLU-Pro-S.
Experimental Validation
Extensive experiments validate the scalability of both algorithms across different datasets and LLMs, including Llama3.1, Qwen2.5, and GPT-4o.
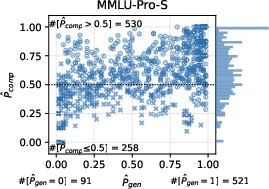
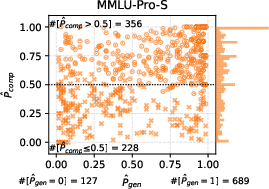
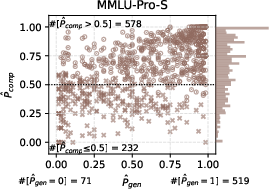
Figure 3: The distribution of GPQA (top) and MMLU-Pro-S (bottom) problems, characterized by p and p that are estimated with the empirical results for the knockout-style algorithm using the Llama3.1 (left), Qwen2.5 (middle), or Mixed (right) option.
Theoretical Implications
These algorithms extend the toolkit for scalable inference with LLMs, offering practical solutions without relying on external validation mechanisms. They facilitate improved reliability for tasks demanding high success rates, achieved by strategic utilization of additional compute at inference time.
Future Directions
Future work could explore the integration of knockout and league-style algorithms with other test-time scaling strategies, refine assumptions for broader applicability, and develop adaptive algorithms for variable compute availability.
Conclusion
The presented algorithms provide foundational insights and practical methods that leverage increased compute for enhancing LLM test-time performance, ensuring solutions are robust and scalable even under challenging scenarios. The proven scaling laws attest to the algorithms' potential in real-world applications where reliability cannot be compromised.

